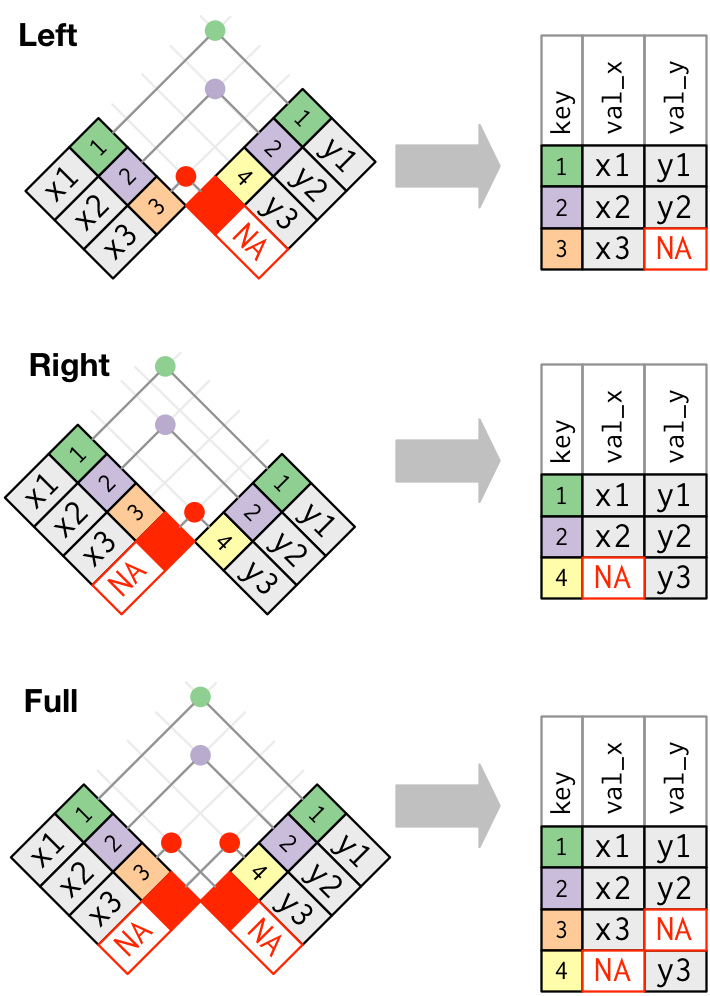
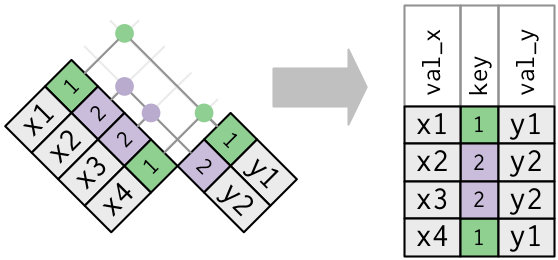
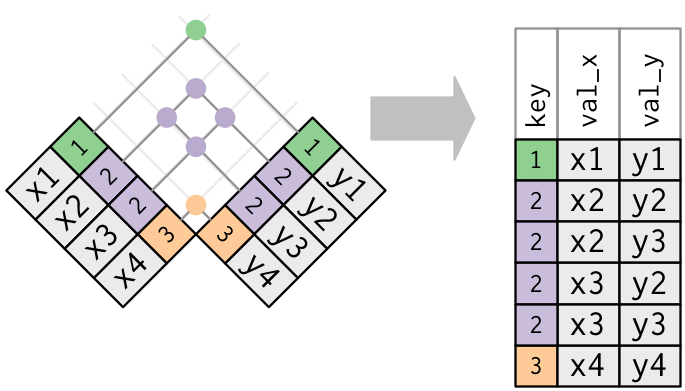
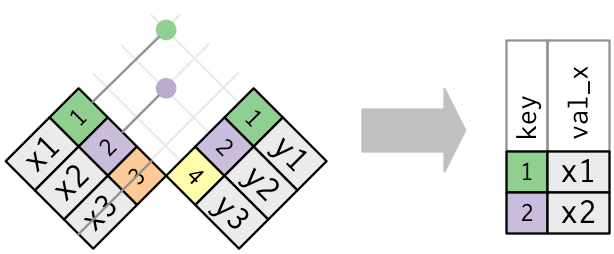
Display machine information for reproducibility.
R version 4.2.2 (2022-10-31)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Big Sur ... 10.16
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] digest_0.6.30 lifecycle_1.0.3 jsonlite_1.8.4 magrittr_2.0.3
[5] evaluate_0.18 rlang_1.0.6 stringi_1.7.8 cli_3.4.1
[9] rstudioapi_0.14 vctrs_0.5.1 rmarkdown_2.18 tools_4.2.2
[13] stringr_1.5.0 glue_1.6.2 htmlwidgets_1.6.0 xfun_0.35
[17] yaml_2.3.6 fastmap_1.1.0 compiler_4.2.2 htmltools_0.5.4
[21] knitr_1.41
import IPythonprint (IPython.sys_info())
{'commit_hash': 'add5877a4',
'commit_source': 'installation',
'default_encoding': 'utf-8',
'ipython_path': '/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/IPython',
'ipython_version': '8.8.0',
'os_name': 'posix',
'platform': 'macOS-10.16-x86_64-i386-64bit',
'sys_executable': '/Library/Frameworks/Python.framework/Versions/3.10/bin/python3',
'sys_platform': 'darwin',
'sys_version': '3.10.9 (v3.10.9:1dd9be6584, Dec 6 2022, 14:37:36) [Clang '
'13.0.0 (clang-1300.0.29.30)]'}
using InteractiveUtils versioninfo ()
Julia Version 1.8.3
Commit 0434deb161e (2022-11-14 20:14 UTC)
Platform Info:
OS: macOS (x86_64-apple-darwin21.4.0)
CPU: 8 × Intel(R) Core(TM) i7-6920HQ CPU @ 2.90GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-13.0.1 (ORCJIT, skylake)
Threads: 1 on 8 virtual cores
Environment:
DYLD_FALLBACK_LIBRARY_PATH = /Library/Frameworks/R.framework/Resources/lib:/Library/Java/JavaVirtualMachines/jdk1.8.0_241.jdk/Contents/Home/jre/lib/server
JULIA_EDITOR = code
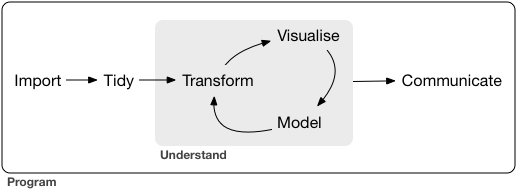
Load tidyverse (R), Pandas (Python), and DataFrames.jl (Julia).
# Load the pandas library import pandas as pd# Load numpy for array manipulation import numpy as np
using DataFrames , Pipe , StatsBase
A typical data science project:
nycflights13 data
library ("nycflights13" )
# A tibble: 336,776 × 19
year month day dep_time sched_de…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 1 1 517 515 2 830 819 11 UA
2 2013 1 1 533 529 4 850 830 20 UA
3 2013 1 1 542 540 2 923 850 33 AA
4 2013 1 1 544 545 -1 1004 1022 -18 B6
5 2013 1 1 554 600 -6 812 837 -25 DL
6 2013 1 1 554 558 -4 740 728 12 UA
7 2013 1 1 555 600 -5 913 854 19 B6
8 2013 1 1 557 600 -3 709 723 -14 EV
9 2013 1 1 557 600 -3 838 846 -8 B6
10 2013 1 1 558 600 -2 753 745 8 AA
# … with 336,766 more rows, 9 more variables: flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>, and abbreviated variable names
# ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
The nycflights13 data is available from the nycflights13 package in Python.
from nycflights13 import flights
year month day ... hour minute time_hour
0 2013 1 1 ... 5 15 2013-01-01T10:00:00Z
1 2013 1 1 ... 5 29 2013-01-01T10:00:00Z
2 2013 1 1 ... 5 40 2013-01-01T10:00:00Z
3 2013 1 1 ... 5 45 2013-01-01T10:00:00Z
4 2013 1 1 ... 6 0 2013-01-01T11:00:00Z
... ... ... ... ... ... ... ...
336771 2013 9 30 ... 14 55 2013-09-30T18:00:00Z
336772 2013 9 30 ... 22 0 2013-10-01T02:00:00Z
336773 2013 9 30 ... 12 10 2013-09-30T16:00:00Z
336774 2013 9 30 ... 11 59 2013-09-30T15:00:00Z
336775 2013 9 30 ... 8 40 2013-09-30T12:00:00Z
[336776 rows x 19 columns]
Note there are some differences of this flights data from that in tidyverse. The data types for some variables are different. There are no natural ways in Pandas to hold integer column with missing values; so dep_time , arr_time are float64 instead of int64.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 336776 entries, 0 to 336775
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 336776 non-null int64
1 month 336776 non-null int64
2 day 336776 non-null int64
3 dep_time 328521 non-null float64
4 sched_dep_time 336776 non-null int64
5 dep_delay 328521 non-null float64
6 arr_time 328063 non-null float64
7 sched_arr_time 336776 non-null int64
8 arr_delay 327346 non-null float64
9 carrier 336776 non-null object
10 flight 336776 non-null int64
11 tailnum 334264 non-null object
12 origin 336776 non-null object
13 dest 336776 non-null object
14 air_time 327346 non-null float64
15 distance 336776 non-null int64
16 hour 336776 non-null int64
17 minute 336776 non-null int64
18 time_hour 336776 non-null object
dtypes: float64(5), int64(9), object(5)
memory usage: 48.8+ MB
To be more consistent with nycflights13 in tidyverse, we cast time_hour to datetime type.
'time_hour' ] = pd.to_datetime(flights['time_hour' ])
Let’s use RCall.jl to retrieve the nycflights13 data from R.
using RCall """ library(nycflights13) """ = rcopy (R"flights" )
336776×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
3 │ 2013 1 1 542 540 2.0 923
4 │ 2013 1 1 544 545 -1.0 1004
5 │ 2013 1 1 554 600 -6.0 812 ⋯
6 │ 2013 1 1 554 558 -4.0 740
7 │ 2013 1 1 555 600 -5.0 913
8 │ 2013 1 1 557 600 -3.0 709
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 30 2349 2359 -10.0 325 ⋯
336771 │ 2013 9 30 missing 1842 missing missing
336772 │ 2013 9 30 missing 1455 missing missing
336773 │ 2013 9 30 missing 2200 missing missing
336774 │ 2013 9 30 missing 1210 missing missing ⋯
336775 │ 2013 9 30 missing 1159 missing missing
336776 │ 2013 9 30 missing 840 missing missing
12 columns and 336761 rows omitted
To display more rows or columns:
By default, tibble prints the first 10 rows and all columns that fit on screen .
To change number of rows and columns to display:
:: flights %>% print (n = 10 , width = Inf )
# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
arr_delay carrier flight tailnum origin dest air_time distance hour minute
<dbl> <chr> <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 11 UA 1545 N14228 EWR IAH 227 1400 5 15
2 20 UA 1714 N24211 LGA IAH 227 1416 5 29
3 33 AA 1141 N619AA JFK MIA 160 1089 5 40
4 -18 B6 725 N804JB JFK BQN 183 1576 5 45
5 -25 DL 461 N668DN LGA ATL 116 762 6 0
6 12 UA 1696 N39463 EWR ORD 150 719 5 58
7 19 B6 507 N516JB EWR FLL 158 1065 6 0
8 -14 EV 5708 N829AS LGA IAD 53 229 6 0
9 -8 B6 79 N593JB JFK MCO 140 944 6 0
10 8 AA 301 N3ALAA LGA ORD 138 733 6 0
time_hour
<dttm>
1 2013-01-01 05:00:00
2 2013-01-01 05:00:00
3 2013-01-01 05:00:00
4 2013-01-01 05:00:00
5 2013-01-01 06:00:00
6 2013-01-01 05:00:00
7 2013-01-01 06:00:00
8 2013-01-01 06:00:00
9 2013-01-01 06:00:00
10 2013-01-01 06:00:00
# … with 336,766 more rows
Here we see the pipe operator %>% pipes the output from previous command to the (first) argument of the next command.
To change the default print setting globally:
options(tibble.print_max = n, tibble.print_min = m): if more than m rows, print only n rows.options(dplyr.print_min = Inf): print all row.options(tibble.width = Inf): print all columns.
"display.max_rows" , 500 )"display.max_columns" , 20 )
By default DataFrames.jl limits the number of rows and columns when displaying a data frame in a Jupyter Notebook to 25 and 100, respectively. You can override this behavior by changing the values of the ENV["DATAFRAMES_COLUMNS"] and ENV["DATAFRAMES_ROWS"] variables to hold the maximum number of columns and rows of the output. All columns or rows will be printed if those numbers are equal or lower than 0.
dplyr basics
Pick observations (rows) by their values: filter().
Reorder the rows: arrange().
Pick variables (columns) by their names: select().
Create new variables with functions of existing variables: mutate().
Collapse many values down to a single summary: summarise().
verb meaning
--------------------------------------------
filter() subset observations (or rows)
arrange() re-order the observations
distinct() remove duplicate entries
select() select variables (or columns)
mutate() add new variables (or columns)
group_by() aggregate
summarise() reduce to a single row
left_join() merge two data objects
collect() force computation and bring data back into R
Manipulate rows (cases)
Filter rows with filter()
# same as filter(flights, month == 1 & day == 1) filter (flights, month == 1 , day == 1 )
# A tibble: 842 × 19
year month day dep_time sched_de…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 1 1 517 515 2 830 819 11 UA
2 2013 1 1 533 529 4 850 830 20 UA
3 2013 1 1 542 540 2 923 850 33 AA
4 2013 1 1 544 545 -1 1004 1022 -18 B6
5 2013 1 1 554 600 -6 812 837 -25 DL
6 2013 1 1 554 558 -4 740 728 12 UA
7 2013 1 1 555 600 -5 913 854 19 B6
8 2013 1 1 557 600 -3 709 723 -14 EV
9 2013 1 1 557 600 -3 838 846 -8 B6
10 2013 1 1 558 600 -2 753 745 8 AA
# … with 832 more rows, 9 more variables: flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>, and abbreviated variable names
# ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
'month' ] == 1 ) & (flights['day' ] == 1 )]
year month day dep_time sched_dep_time dep_delay arr_time \
0 2013 1 1 517.0 515 2.0 830.0
1 2013 1 1 533.0 529 4.0 850.0
2 2013 1 1 542.0 540 2.0 923.0
3 2013 1 1 544.0 545 -1.0 1004.0
4 2013 1 1 554.0 600 -6.0 812.0
.. ... ... ... ... ... ... ...
837 2013 1 1 2356.0 2359 -3.0 425.0
838 2013 1 1 NaN 1630 NaN NaN
839 2013 1 1 NaN 1935 NaN NaN
840 2013 1 1 NaN 1500 NaN NaN
841 2013 1 1 NaN 600 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest air_time \
0 819 11.0 UA 1545 N14228 EWR IAH 227.0
1 830 20.0 UA 1714 N24211 LGA IAH 227.0
2 850 33.0 AA 1141 N619AA JFK MIA 160.0
3 1022 -18.0 B6 725 N804JB JFK BQN 183.0
4 837 -25.0 DL 461 N668DN LGA ATL 116.0
.. ... ... ... ... ... ... ... ...
837 437 -12.0 B6 727 N588JB JFK BQN 186.0
838 1815 NaN EV 4308 N18120 EWR RDU NaN
839 2240 NaN AA 791 N3EHAA LGA DFW NaN
840 1825 NaN AA 1925 N3EVAA LGA MIA NaN
841 901 NaN B6 125 N618JB JFK FLL NaN
distance hour minute time_hour
0 1400 5 15 2013-01-01 10:00:00+00:00
1 1416 5 29 2013-01-01 10:00:00+00:00
2 1089 5 40 2013-01-01 10:00:00+00:00
3 1576 5 45 2013-01-01 10:00:00+00:00
4 762 6 0 2013-01-01 11:00:00+00:00
.. ... ... ... ...
837 1576 23 59 2013-01-02 04:00:00+00:00
838 416 16 30 2013-01-01 21:00:00+00:00
839 1389 19 35 2013-01-02 00:00:00+00:00
840 1096 15 0 2013-01-01 20:00:00+00:00
841 1069 6 0 2013-01-01 11:00:00+00:00
[842 rows x 19 columns]
filter (row -> (row.month == 1 ) & (row.day == 1 ), flights)
842×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
3 │ 2013 1 1 542 540 2.0 923
4 │ 2013 1 1 544 545 -1.0 1004
5 │ 2013 1 1 554 600 -6.0 812 ⋯
6 │ 2013 1 1 554 558 -4.0 740
7 │ 2013 1 1 555 600 -5.0 913
8 │ 2013 1 1 557 600 -3.0 709
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
836 │ 2013 1 1 2353 2359 -6.0 425 ⋯
837 │ 2013 1 1 2353 2359 -6.0 418
838 │ 2013 1 1 2356 2359 -3.0 425
839 │ 2013 1 1 missing 1630 missing missing
840 │ 2013 1 1 missing 1935 missing missing ⋯
841 │ 2013 1 1 missing 1500 missing missing
842 │ 2013 1 1 missing 600 missing missing
12 columns and 827 rows omitted
filter (flights, month == 11 | month == 12 )
# A tibble: 55,403 × 19
year month day dep_time sched_de…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 11 1 5 2359 6 352 345 7 B6
2 2013 11 1 35 2250 105 123 2356 87 B6
3 2013 11 1 455 500 -5 641 651 -10 US
4 2013 11 1 539 545 -6 856 827 29 UA
5 2013 11 1 542 545 -3 831 855 -24 AA
6 2013 11 1 549 600 -11 912 923 -11 UA
7 2013 11 1 550 600 -10 705 659 6 US
8 2013 11 1 554 600 -6 659 701 -2 US
9 2013 11 1 554 600 -6 826 827 -1 DL
10 2013 11 1 554 600 -6 749 751 -2 DL
# … with 55,393 more rows, 9 more variables: flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>, and abbreviated variable names
# ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
'month' ] == 11 ) | (flights['month' ] == 12 )]
year month day dep_time sched_dep_time dep_delay arr_time \
55893 2013 11 1 5.0 2359 6.0 352.0
55894 2013 11 1 35.0 2250 105.0 123.0
55895 2013 11 1 455.0 500 -5.0 641.0
55896 2013 11 1 539.0 545 -6.0 856.0
55897 2013 11 1 542.0 545 -3.0 831.0
... ... ... ... ... ... ... ...
111291 2013 12 31 NaN 705 NaN NaN
111292 2013 12 31 NaN 825 NaN NaN
111293 2013 12 31 NaN 1615 NaN NaN
111294 2013 12 31 NaN 600 NaN NaN
111295 2013 12 31 NaN 830 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest \
55893 345 7.0 B6 745 N568JB JFK PSE
55894 2356 87.0 B6 1816 N353JB JFK SYR
55895 651 -10.0 US 1895 N192UW EWR CLT
55896 827 29.0 UA 1714 N38727 LGA IAH
55897 855 -24.0 AA 2243 N5CLAA JFK MIA
... ... ... ... ... ... ... ...
111291 931 NaN UA 1729 NaN EWR DEN
111292 1029 NaN US 1831 NaN JFK CLT
111293 1800 NaN MQ 3301 N844MQ LGA RDU
111294 735 NaN UA 219 NaN EWR ORD
111295 1154 NaN UA 443 NaN JFK LAX
air_time distance hour minute time_hour
55893 205.0 1617 23 59 2013-11-02 03:00:00+00:00
55894 36.0 209 22 50 2013-11-02 02:00:00+00:00
55895 88.0 529 5 0 2013-11-01 09:00:00+00:00
55896 229.0 1416 5 45 2013-11-01 09:00:00+00:00
55897 147.0 1089 5 45 2013-11-01 09:00:00+00:00
... ... ... ... ... ...
111291 NaN 1605 7 5 2013-12-31 12:00:00+00:00
111292 NaN 541 8 25 2013-12-31 13:00:00+00:00
111293 NaN 431 16 15 2013-12-31 21:00:00+00:00
111294 NaN 719 6 0 2013-12-31 11:00:00+00:00
111295 NaN 2475 8 30 2013-12-31 13:00:00+00:00
[55403 rows x 19 columns]
filter (row -> (row.month == 11 ) | (row.month == 12 ), flights)
55403×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time s ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? I ⋯
───────┼────────────────────────────────────────────────────────────────────────
1 │ 2013 11 1 5 2359 6.0 352 ⋯
2 │ 2013 11 1 35 2250 105.0 123
3 │ 2013 11 1 455 500 -5.0 641
4 │ 2013 11 1 539 545 -6.0 856
5 │ 2013 11 1 542 545 -3.0 831 ⋯
6 │ 2013 11 1 549 600 -11.0 912
7 │ 2013 11 1 550 600 -10.0 705
8 │ 2013 11 1 554 600 -6.0 659
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
55397 │ 2013 12 31 missing 1430 missing missing ⋯
55398 │ 2013 12 31 missing 855 missing missing
55399 │ 2013 12 31 missing 705 missing missing
55400 │ 2013 12 31 missing 825 missing missing
55401 │ 2013 12 31 missing 1615 missing missing ⋯
55402 │ 2013 12 31 missing 600 missing missing
55403 │ 2013 12 31 missing 830 missing missing
12 columns and 55388 rows omitted
Remove rows with duplicate values
distinct (flights, month, .keep_all = TRUE )
# A tibble: 12 × 19
year month day dep_time sched_de…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 1 1 517 515 2 830 819 11 UA
2 2013 10 1 447 500 -13 614 648 -34 US
3 2013 11 1 5 2359 6 352 345 7 B6
4 2013 12 1 13 2359 14 446 445 1 B6
5 2013 2 1 456 500 -4 652 648 4 US
6 2013 3 1 4 2159 125 318 56 142 B6
7 2013 4 1 454 500 -6 636 640 -4 US
8 2013 5 1 9 1655 434 308 2020 408 VX
9 2013 6 1 2 2359 3 341 350 -9 B6
10 2013 7 1 1 2029 212 236 2359 157 B6
11 2013 8 1 12 2130 162 257 14 163 B6
12 2013 9 1 9 2359 10 343 340 3 B6
# … with 9 more variables: flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
# time_hour <dttm>, and abbreviated variable names ¹sched_dep_time,
# ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
With .keep_all = FALSE, only distinct values of the variable are selected:
# A tibble: 12 × 1
month
<int>
1 1
2 10
3 11
4 12
5 2
6 3
7 4
8 5
9 6
10 7
11 8
12 9
= ['month' ])
year month day dep_time sched_dep_time dep_delay arr_time \
0 2013 1 1 517.0 515 2.0 830.0
27004 2013 10 1 447.0 500 -13.0 614.0
55893 2013 11 1 5.0 2359 6.0 352.0
83161 2013 12 1 13.0 2359 14.0 446.0
111296 2013 2 1 456.0 500 -4.0 652.0
136247 2013 3 1 4.0 2159 125.0 318.0
165081 2013 4 1 454.0 500 -6.0 636.0
193411 2013 5 1 9.0 1655 434.0 308.0
222207 2013 6 1 2.0 2359 3.0 341.0
250450 2013 7 1 1.0 2029 212.0 236.0
279875 2013 8 1 12.0 2130 162.0 257.0
309202 2013 9 1 9.0 2359 10.0 343.0
sched_arr_time arr_delay carrier flight tailnum origin dest \
0 819 11.0 UA 1545 N14228 EWR IAH
27004 648 -34.0 US 1877 N538UW EWR CLT
55893 345 7.0 B6 745 N568JB JFK PSE
83161 445 1.0 B6 745 N715JB JFK PSE
111296 648 4.0 US 1117 N197UW EWR CLT
136247 56 142.0 B6 11 N706JB JFK FLL
165081 640 -4.0 US 1843 N566UW EWR CLT
193411 2020 408.0 VX 413 N628VA JFK LAX
222207 350 -9.0 B6 739 N618JB JFK PSE
250450 2359 157.0 B6 915 N653JB JFK SFO
279875 14 163.0 B6 1371 N618JB LGA FLL
309202 340 3.0 B6 839 N663JB JFK BQN
air_time distance hour minute time_hour
0 227.0 1400 5 15 2013-01-01 10:00:00+00:00
27004 69.0 529 5 0 2013-10-01 09:00:00+00:00
55893 205.0 1617 23 59 2013-11-02 03:00:00+00:00
83161 195.0 1617 23 59 2013-12-02 04:00:00+00:00
111296 98.0 529 5 0 2013-02-01 10:00:00+00:00
136247 166.0 1069 21 59 2013-03-02 02:00:00+00:00
165081 84.0 529 5 0 2013-04-01 09:00:00+00:00
193411 341.0 2475 16 55 2013-05-01 20:00:00+00:00
222207 200.0 1617 23 59 2013-06-02 03:00:00+00:00
250450 315.0 2586 20 29 2013-07-02 00:00:00+00:00
279875 149.0 1076 21 30 2013-08-02 01:00:00+00:00
309202 196.0 1576 23 59 2013-09-02 03:00:00+00:00
12×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 10 1 447 500 -13.0 614
3 │ 2013 11 1 5 2359 6.0 352
4 │ 2013 12 1 13 2359 14.0 446
5 │ 2013 2 1 456 500 -4.0 652 ⋯
6 │ 2013 3 1 4 2159 125.0 318
7 │ 2013 4 1 454 500 -6.0 636
8 │ 2013 5 1 9 1655 434.0 308
9 │ 2013 6 1 2 2359 3.0 341 ⋯
10 │ 2013 7 1 1 2029 212.0 236
11 │ 2013 8 1 12 2130 162.0 257
12 │ 2013 9 1 9 2359 10.0 343
12 columns omitted
Sample rows
sample_n (flights, 10 , replace = TRUE )
# A tibble: 10 × 19
year month day dep_time sched_de…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 10 9 2155 2123 32 2327 2321 6 EV
2 2013 3 3 728 729 -1 1017 1026 -9 B6
3 2013 5 11 1431 1433 -2 1531 1540 -9 EV
4 2013 7 2 1315 1315 0 1534 1607 -33 UA
5 2013 6 24 609 600 9 710 727 -17 UA
6 2013 11 26 1254 1244 10 1419 1357 22 EV
7 2013 4 15 1503 1511 -8 1723 1705 18 EV
8 2013 3 26 1155 1157 -2 1448 1450 -2 B6
9 2013 3 21 1724 1720 4 1912 1910 2 AA
10 2013 10 29 856 900 -4 1233 1210 23 B6
# … with 9 more variables: flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
# time_hour <dttm>, and abbreviated variable names ¹sched_dep_time,
# ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
Randomly select fraction of rows:
sample_frac (flights, 0.1 , replace = TRUE )
# A tibble: 33,678 × 19
year month day dep_time sched_de…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 3 14 608 610 -2 915 918 -3 B6
2 2013 5 11 NA 1910 NA NA 2043 NA 9E
3 2013 1 2 2041 1942 59 2151 2106 45 EV
4 2013 5 16 1638 1409 149 1756 1517 159 B6
5 2013 2 6 1421 1400 21 1609 1559 10 EV
6 2013 3 8 917 910 7 1206 1032 94 B6
7 2013 11 29 723 730 -7 904 925 -21 DL
8 2013 11 10 2354 2359 -5 422 440 -18 B6
9 2013 7 2 1456 1500 -4 1731 1750 -19 AA
10 2013 2 12 1459 1500 -1 1759 1837 -38 DL
# … with 33,668 more rows, 9 more variables: flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>, and abbreviated variable names
# ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
Sample n=10 rows.
= 10 , axis = 0 , replace = True )
year month day dep_time sched_dep_time dep_delay arr_time \
79035 2013 11 26 608.0 605 3.0 727.0
94653 2013 12 13 859.0 900 -1.0 1226.0
25151 2013 1 29 2156.0 2159 -3.0 2300.0
188962 2013 4 26 754.0 755 -1.0 1040.0
46606 2013 10 22 650.0 700 -10.0 1000.0
62032 2013 11 7 1641.0 1645 -4.0 1913.0
280822 2013 8 1 NaN 1545 NaN NaN
56379 2013 11 1 1424.0 1335 49.0 1539.0
100616 2013 12 19 1903.0 1830 33.0 2126.0
87298 2013 12 5 848.0 850 -2.0 1225.0
sched_arr_time arr_delay carrier flight tailnum origin dest \
79035 730 -3.0 WN 1284 N266WN EWR MDW
94653 1206 20.0 B6 1701 N527JB JFK FLL
25151 2306 -6.0 EV 4322 N12175 EWR PWM
188962 1007 33.0 9E 3879 N826AY EWR CVG
46606 949 11.0 B6 683 N618JB JFK MCO
62032 1916 -3.0 DL 884 N315NB LGA DEN
280822 1906 NaN DL 1982 N918DE LGA MIA
56379 1500 39.0 WN 1 N796SW LGA MDW
100616 2107 19.0 DL 404 N3772H JFK ATL
87298 1132 53.0 UA 1643 N13138 EWR DEN
air_time distance hour minute time_hour
79035 125.0 711 6 5 2013-11-26 11:00:00+00:00
94653 159.0 1069 9 0 2013-12-13 14:00:00+00:00
25151 48.0 284 21 59 2013-01-30 02:00:00+00:00
188962 94.0 569 7 55 2013-04-26 11:00:00+00:00
46606 147.0 944 7 0 2013-10-22 11:00:00+00:00
62032 234.0 1620 16 45 2013-11-07 21:00:00+00:00
280822 NaN 1096 15 45 2013-08-01 19:00:00+00:00
56379 114.0 725 13 35 2013-11-01 17:00:00+00:00
100616 108.0 760 18 30 2013-12-19 23:00:00+00:00
87298 252.0 1605 8 50 2013-12-05 13:00:00+00:00
Sample 10% rows:
= 0.1 , replace = True )
year month day dep_time sched_dep_time dep_delay arr_time \
78527 2013 11 25 1352.0 1400 -8.0 1450.0
278201 2013 7 30 1034.0 1035 -1.0 1150.0
57430 2013 11 2 1725.0 1732 -7.0 1943.0
272771 2013 7 24 1636.0 1630 6.0 1844.0
29289 2013 10 3 1102.0 1110 -8.0 1410.0
... ... ... ... ... ... ... ...
290548 2013 8 12 828.0 830 -2.0 1011.0
300731 2013 8 22 1837.0 1722 75.0 1953.0
248165 2013 6 28 1313.0 1315 -2.0 1601.0
192837 2013 4 30 1156.0 1200 -4.0 1318.0
235947 2013 6 15 1723.0 1700 23.0 1838.0
sched_arr_time arr_delay carrier flight tailnum origin dest \
78527 1515 -25.0 US 2183 N756US LGA DCA
278201 1154 -4.0 B6 2602 N184JB JFK BUF
57430 1959 -16.0 FL 623 N603AT LGA ATL
272771 1839 5.0 DL 2231 N381DN LGA DTW
29289 1431 -21.0 9E 3493 N926XJ LGA SRQ
... ... ... ... ... ... ... ...
290548 1010 1.0 9E 3521 N604LR JFK ORD
300731 1858 55.0 B6 86 N216JB JFK ROC
248165 1558 3.0 B6 553 N206JB JFK PBI
192837 1310 8.0 US 2126 N959UW LGA BOS
235947 1845 -7.0 MQ 3216 N638MQ JFK ORF
air_time distance hour minute time_hour
78527 39.0 214 14 0 2013-11-25 19:00:00+00:00
278201 54.0 301 10 35 2013-07-30 14:00:00+00:00
57430 120.0 762 17 32 2013-11-02 21:00:00+00:00
272771 81.0 502 16 30 2013-07-24 20:00:00+00:00
29289 150.0 1047 11 10 2013-10-03 15:00:00+00:00
... ... ... ... ... ...
290548 120.0 740 8 30 2013-08-12 12:00:00+00:00
300731 51.0 264 17 22 2013-08-22 21:00:00+00:00
248165 142.0 1028 13 15 2013-06-28 17:00:00+00:00
192837 37.0 184 12 0 2013-04-30 16:00:00+00:00
235947 46.0 290 17 0 2013-06-15 21:00:00+00:00
[33678 rows x 19 columns]
I’m not sure whether there’s a native function in DataFrames.jl for sampling.
Sample 10 rows:
= StatsBase.sample (1 : nrow (flights), 10 , replace = true );: ]
10×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 11 18 1426 1429 -3.0 1632 ⋯
2 │ 2013 11 15 902 906 -4.0 1049
3 │ 2013 6 3 1433 1435 -2.0 1557
4 │ 2013 10 30 1527 1529 -2.0 1656
5 │ 2013 9 16 1801 1810 -9.0 2010 ⋯
6 │ 2013 5 10 1649 1415 154.0 1815
7 │ 2013 3 13 1506 1512 -6.0 1808
8 │ 2013 5 20 645 630 15.0 753
9 │ 2013 7 26 1709 1655 14.0 1959 ⋯
10 │ 2013 8 11 1454 1440 14.0 1624
12 columns omitted
Sample 10% rows:
= StatsBase.sample (1 : nrow (flights), round (Int , nrow (flights) * 0.1 ), = true );: ]
33678×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time s ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? I ⋯
───────┼────────────────────────────────────────────────────────────────────────
1 │ 2013 3 2 724 730 -6.0 832 ⋯
2 │ 2013 4 29 933 930 3.0 1214
3 │ 2013 9 18 815 815 0.0 941
4 │ 2013 7 26 812 815 -3.0 929
5 │ 2013 11 6 1923 1930 -7.0 2143 ⋯
6 │ 2013 9 28 1552 1545 7.0 1712
7 │ 2013 8 18 1646 1550 56.0 1818
8 │ 2013 10 26 812 815 -3.0 934
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
33672 │ 2013 12 23 1453 1326 87.0 1553 ⋯
33673 │ 2013 12 9 1824 1714 70.0 1938
33674 │ 2013 3 21 1717 1645 32.0 1933
33675 │ 2013 1 10 1759 1722 37.0 1929
33676 │ 2013 1 11 1446 1444 2.0 1743 ⋯
33677 │ 2013 6 21 1104 1107 -3.0 1206
33678 │ 2013 6 11 946 945 1.0 1102
12 columns and 33663 rows omitted
Select rows by position
# A tibble: 5 × 19
year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 1 1 517 515 2 830 819 11 UA
2 2013 1 1 533 529 4 850 830 20 UA
3 2013 1 1 542 540 2 923 850 33 AA
4 2013 1 1 544 545 -1 1004 1022 -18 B6
5 2013 1 1 554 600 -6 812 837 -25 DL
# … with 9 more variables: flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
# time_hour <dttm>, and abbreviated variable names ¹sched_dep_time,
# ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
slice_head (flights, n = 5 )
# A tibble: 5 × 19
year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 1 1 517 515 2 830 819 11 UA
2 2013 1 1 533 529 4 850 830 20 UA
3 2013 1 1 542 540 2 923 850 33 AA
4 2013 1 1 544 545 -1 1004 1022 -18 B6
5 2013 1 1 554 600 -6 812 837 -25 DL
# … with 9 more variables: flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
# time_hour <dttm>, and abbreviated variable names ¹sched_dep_time,
# ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
slice_tail (flights, n = 5 )
# A tibble: 5 × 19
year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 9 30 NA 1455 NA NA 1634 NA 9E
2 2013 9 30 NA 2200 NA NA 2312 NA 9E
3 2013 9 30 NA 1210 NA NA 1330 NA MQ
4 2013 9 30 NA 1159 NA NA 1344 NA MQ
5 2013 9 30 NA 840 NA NA 1020 NA MQ
# … with 9 more variables: flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
# time_hour <dttm>, and abbreviated variable names ¹sched_dep_time,
# ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
Top n rows with the highest values:
# deprecated: top_n(flights, 5, wt = time_hour) # This function is quick slice_max (flights, n = 5 , order_by = time_hour)
# A tibble: 5 × 19
year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 12 31 13 2359 14 439 437 2 B6
2 2013 12 31 18 2359 19 449 444 5 DL
3 2013 12 31 2328 2330 -2 412 409 3 B6
4 2013 12 31 2355 2359 -4 430 440 -10 B6
5 2013 12 31 2356 2359 -3 436 445 -9 B6
# … with 9 more variables: flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
# time_hour <dttm>, and abbreviated variable names ¹sched_dep_time,
# ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
Bottom n rows with lowest values:
# deprecated: top_n(flights, -5, wt = time_hour) # Why it takes REALLY long??? slice_max (flights, n = 5 , order_by = desc (time_hour)) # is fast
# A tibble: 6 × 19
year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 1 1 517 515 2 830 819 11 UA
2 2013 1 1 533 529 4 850 830 20 UA
3 2013 1 1 542 540 2 923 850 33 AA
4 2013 1 1 544 545 -1 1004 1022 -18 B6
5 2013 1 1 554 558 -4 740 728 12 UA
6 2013 1 1 559 559 0 702 706 -4 B6
# … with 9 more variables: flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
# time_hour <dttm>, and abbreviated variable names ¹sched_dep_time,
# ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
# slice_min(flights, n = 5, order_by = time_hour) # very slow
slice_* verbs apply to groups for grouped tibbles.
range (0 , 5 )]
year month day dep_time sched_dep_time dep_delay arr_time \
0 2013 1 1 517.0 515 2.0 830.0
1 2013 1 1 533.0 529 4.0 850.0
2 2013 1 1 542.0 540 2.0 923.0
3 2013 1 1 544.0 545 -1.0 1004.0
4 2013 1 1 554.0 600 -6.0 812.0
sched_arr_time arr_delay carrier flight tailnum origin dest air_time \
0 819 11.0 UA 1545 N14228 EWR IAH 227.0
1 830 20.0 UA 1714 N24211 LGA IAH 227.0
2 850 33.0 AA 1141 N619AA JFK MIA 160.0
3 1022 -18.0 B6 725 N804JB JFK BQN 183.0
4 837 -25.0 DL 461 N668DN LGA ATL 116.0
distance hour minute time_hour
0 1400 5 15 2013-01-01 10:00:00+00:00
1 1416 5 29 2013-01-01 10:00:00+00:00
2 1089 5 40 2013-01-01 10:00:00+00:00
3 1576 5 45 2013-01-01 10:00:00+00:00
4 762 6 0 2013-01-01 11:00:00+00:00
year month day dep_time sched_dep_time dep_delay arr_time \
0 2013 1 1 517.0 515 2.0 830.0
1 2013 1 1 533.0 529 4.0 850.0
2 2013 1 1 542.0 540 2.0 923.0
3 2013 1 1 544.0 545 -1.0 1004.0
4 2013 1 1 554.0 600 -6.0 812.0
sched_arr_time arr_delay carrier flight tailnum origin dest air_time \
0 819 11.0 UA 1545 N14228 EWR IAH 227.0
1 830 20.0 UA 1714 N24211 LGA IAH 227.0
2 850 33.0 AA 1141 N619AA JFK MIA 160.0
3 1022 -18.0 B6 725 N804JB JFK BQN 183.0
4 837 -25.0 DL 461 N668DN LGA ATL 116.0
distance hour minute time_hour
0 1400 5 15 2013-01-01 10:00:00+00:00
1 1416 5 29 2013-01-01 10:00:00+00:00
2 1089 5 40 2013-01-01 10:00:00+00:00
3 1576 5 45 2013-01-01 10:00:00+00:00
4 762 6 0 2013-01-01 11:00:00+00:00
year month day dep_time sched_dep_time dep_delay arr_time \
336771 2013 9 30 NaN 1455 NaN NaN
336772 2013 9 30 NaN 2200 NaN NaN
336773 2013 9 30 NaN 1210 NaN NaN
336774 2013 9 30 NaN 1159 NaN NaN
336775 2013 9 30 NaN 840 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest \
336771 1634 NaN 9E 3393 NaN JFK DCA
336772 2312 NaN 9E 3525 NaN LGA SYR
336773 1330 NaN MQ 3461 N535MQ LGA BNA
336774 1344 NaN MQ 3572 N511MQ LGA CLE
336775 1020 NaN MQ 3531 N839MQ LGA RDU
air_time distance hour minute time_hour
336771 NaN 213 14 55 2013-09-30 18:00:00+00:00
336772 NaN 198 22 0 2013-10-01 02:00:00+00:00
336773 NaN 764 12 10 2013-09-30 16:00:00+00:00
336774 NaN 419 11 59 2013-09-30 15:00:00+00:00
336775 NaN 431 8 40 2013-09-30 12:00:00+00:00
Top n rows with the highest values:
= 5 , columns = 'time_hour' )
year month day dep_time sched_dep_time dep_delay arr_time \
110520 2013 12 31 13.0 2359 14.0 439.0
110521 2013 12 31 18.0 2359 19.0 449.0
111276 2013 12 31 2328.0 2330 -2.0 412.0
111278 2013 12 31 2355.0 2359 -4.0 430.0
111279 2013 12 31 2356.0 2359 -3.0 436.0
sched_arr_time arr_delay carrier flight tailnum origin dest \
110520 437 2.0 B6 839 N566JB JFK BQN
110521 444 5.0 DL 412 N713TW JFK SJU
111276 409 3.0 B6 1389 N651JB EWR SJU
111278 440 -10.0 B6 1503 N509JB JFK SJU
111279 445 -9.0 B6 745 N665JB JFK PSE
air_time distance hour minute time_hour
110520 189.0 1576 23 59 2014-01-01 04:00:00+00:00
110521 192.0 1598 23 59 2014-01-01 04:00:00+00:00
111276 198.0 1608 23 30 2014-01-01 04:00:00+00:00
111278 195.0 1598 23 59 2014-01-01 04:00:00+00:00
111279 200.0 1617 23 59 2014-01-01 04:00:00+00:00
Bottom n rows with lowest values:
= 5 , columns = 'time_hour' )
year month day dep_time sched_dep_time dep_delay arr_time \
0 2013 1 1 517.0 515 2.0 830.0
1 2013 1 1 533.0 529 4.0 850.0
2 2013 1 1 542.0 540 2.0 923.0
3 2013 1 1 544.0 545 -1.0 1004.0
5 2013 1 1 554.0 558 -4.0 740.0
sched_arr_time arr_delay carrier flight tailnum origin dest air_time \
0 819 11.0 UA 1545 N14228 EWR IAH 227.0
1 830 20.0 UA 1714 N24211 LGA IAH 227.0
2 850 33.0 AA 1141 N619AA JFK MIA 160.0
3 1022 -18.0 B6 725 N804JB JFK BQN 183.0
5 728 12.0 UA 1696 N39463 EWR ORD 150.0
distance hour minute time_hour
0 1400 5 15 2013-01-01 10:00:00+00:00
1 1416 5 29 2013-01-01 10:00:00+00:00
2 1089 5 40 2013-01-01 10:00:00+00:00
3 1576 5 45 2013-01-01 10:00:00+00:00
5 719 5 58 2013-01-01 10:00:00+00:00
I don’t think nlargest and nsmallest apply to grouped DataFrame. But I may be wrong.
5×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
3 │ 2013 1 1 542 540 2.0 923
4 │ 2013 1 1 544 545 -1.0 1004
5 │ 2013 1 1 554 600 -6.0 812 ⋯
12 columns omitted
5×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
3 │ 2013 1 1 542 540 2.0 923
4 │ 2013 1 1 544 545 -1.0 1004
5 │ 2013 1 1 554 600 -6.0 812 ⋯
12 columns omitted
5×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 9 30 missing 1455 missing missing ⋯
2 │ 2013 9 30 missing 2200 missing missing
3 │ 2013 9 30 missing 1210 missing missing
4 │ 2013 9 30 missing 1159 missing missing
5 │ 2013 9 30 missing 840 missing missing ⋯
12 columns omitted
Top n rows with the highest values:
last (sort (flights, [: time_hour]), 5 )
5×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 12 31 13 2359 14.0 439 ⋯
2 │ 2013 12 31 18 2359 19.0 449
3 │ 2013 12 31 2328 2330 -2.0 412
4 │ 2013 12 31 2355 2359 -4.0 430
5 │ 2013 12 31 2356 2359 -3.0 436 ⋯
12 columns omitted
Bottom n rows with lowest values:
first (sort (flights, [: time_hour]), 5 )
5×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
3 │ 2013 1 1 542 540 2.0 923
4 │ 2013 1 1 544 545 -1.0 1004
5 │ 2013 1 1 554 558 -4.0 740 ⋯
12 columns omitted
Arrange rows with arrange()
arrange (flights, year, month, day)
# A tibble: 336,776 × 19
year month day dep_time sched_de…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 1 1 517 515 2 830 819 11 UA
2 2013 1 1 533 529 4 850 830 20 UA
3 2013 1 1 542 540 2 923 850 33 AA
4 2013 1 1 544 545 -1 1004 1022 -18 B6
5 2013 1 1 554 600 -6 812 837 -25 DL
6 2013 1 1 554 558 -4 740 728 12 UA
7 2013 1 1 555 600 -5 913 854 19 B6
8 2013 1 1 557 600 -3 709 723 -14 EV
9 2013 1 1 557 600 -3 838 846 -8 B6
10 2013 1 1 558 600 -2 753 745 8 AA
# … with 336,766 more rows, 9 more variables: flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>, and abbreviated variable names
# ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
Note input order matters!
arrange (flights, day, month, year)
# A tibble: 336,776 × 19
year month day dep_time sched_de…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 1 1 517 515 2 830 819 11 UA
2 2013 1 1 533 529 4 850 830 20 UA
3 2013 1 1 542 540 2 923 850 33 AA
4 2013 1 1 544 545 -1 1004 1022 -18 B6
5 2013 1 1 554 600 -6 812 837 -25 DL
6 2013 1 1 554 558 -4 740 728 12 UA
7 2013 1 1 555 600 -5 913 854 19 B6
8 2013 1 1 557 600 -3 709 723 -14 EV
9 2013 1 1 557 600 -3 838 846 -8 B6
10 2013 1 1 558 600 -2 753 745 8 AA
# … with 336,766 more rows, 9 more variables: flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>, and abbreviated variable names
# ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
Sort in descending order:
arrange (flights, desc (arr_delay)) %>% print (width = Inf )
# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 9 641 900 1301 1242 1530
2 2013 6 15 1432 1935 1137 1607 2120
3 2013 1 10 1121 1635 1126 1239 1810
4 2013 9 20 1139 1845 1014 1457 2210
5 2013 7 22 845 1600 1005 1044 1815
6 2013 4 10 1100 1900 960 1342 2211
7 2013 3 17 2321 810 911 135 1020
8 2013 7 22 2257 759 898 121 1026
9 2013 12 5 756 1700 896 1058 2020
10 2013 5 3 1133 2055 878 1250 2215
arr_delay carrier flight tailnum origin dest air_time distance hour minute
<dbl> <chr> <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 1272 HA 51 N384HA JFK HNL 640 4983 9 0
2 1127 MQ 3535 N504MQ JFK CMH 74 483 19 35
3 1109 MQ 3695 N517MQ EWR ORD 111 719 16 35
4 1007 AA 177 N338AA JFK SFO 354 2586 18 45
5 989 MQ 3075 N665MQ JFK CVG 96 589 16 0
6 931 DL 2391 N959DL JFK TPA 139 1005 19 0
7 915 DL 2119 N927DA LGA MSP 167 1020 8 10
8 895 DL 2047 N6716C LGA ATL 109 762 7 59
9 878 AA 172 N5DMAA EWR MIA 149 1085 17 0
10 875 MQ 3744 N523MQ EWR ORD 112 719 20 55
time_hour
<dttm>
1 2013-01-09 09:00:00
2 2013-06-15 19:00:00
3 2013-01-10 16:00:00
4 2013-09-20 18:00:00
5 2013-07-22 16:00:00
6 2013-04-10 19:00:00
7 2013-03-17 08:00:00
8 2013-07-22 07:00:00
9 2013-12-05 17:00:00
10 2013-05-03 20:00:00
# … with 336,766 more rows
By default, arrange ignores grouping in grouped tibbles. Set .by_group = TRUE to arrange within each group.
# What are the worst delays in each month? %>% group_by (month) %>% arrange (desc (arr_delay), .by_group = TRUE ) %>% print (width = Inf )
# A tibble: 336,776 × 19
# Groups: month [12]
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 9 641 900 1301 1242 1530
2 2013 1 10 1121 1635 1126 1239 1810
3 2013 1 1 848 1835 853 1001 1950
4 2013 1 13 1809 810 599 2054 1042
5 2013 1 16 1622 800 502 1911 1054
6 2013 1 23 1551 753 478 1812 1006
7 2013 1 1 2343 1724 379 314 1938
8 2013 1 10 1525 900 385 1713 1039
9 2013 1 25 15 1815 360 208 1958
10 2013 1 2 1607 1030 337 2003 1355
arr_delay carrier flight tailnum origin dest air_time distance hour minute
<dbl> <chr> <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 1272 HA 51 N384HA JFK HNL 640 4983 9 0
2 1109 MQ 3695 N517MQ EWR ORD 111 719 16 35
3 851 MQ 3944 N942MQ JFK BWI 41 184 18 35
4 612 DL 269 N322NB JFK ATL 116 760 8 10
5 497 B6 517 N661JB EWR MCO 144 937 8 0
6 486 DL 2119 N326NB LGA MSP 166 1020 7 53
7 456 EV 4321 N21197 EWR MCI 222 1092 17 24
8 394 UA 544 N419UA LGA ORD 123 733 9 0
9 370 9E 4019 N8646A JFK RIC 56 288 18 15
10 368 AA 179 N324AA JFK SFO 346 2586 10 30
time_hour
<dttm>
1 2013-01-09 09:00:00
2 2013-01-10 16:00:00
3 2013-01-01 18:00:00
4 2013-01-13 08:00:00
5 2013-01-16 08:00:00
6 2013-01-23 07:00:00
7 2013-01-01 17:00:00
8 2013-01-10 09:00:00
9 2013-01-25 18:00:00
10 2013-01-02 10:00:00
# … with 336,766 more rows
= 'arr_delay' )
year month day dep_time sched_dep_time dep_delay arr_time \
199668 2013 5 7 1715.0 1729 -14.0 1944.0
211124 2013 5 20 719.0 735 -16.0 951.0
198763 2013 5 6 1826.0 1830 -4.0 2045.0
195236 2013 5 2 1947.0 1949 -2.0 2209.0
196935 2013 5 4 1816.0 1820 -4.0 2017.0
... ... ... ... ... ... ... ...
336771 2013 9 30 NaN 1455 NaN NaN
336772 2013 9 30 NaN 2200 NaN NaN
336773 2013 9 30 NaN 1210 NaN NaN
336774 2013 9 30 NaN 1159 NaN NaN
336775 2013 9 30 NaN 840 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest \
199668 2110 -86.0 VX 193 N843VA EWR SFO
211124 1110 -79.0 VX 11 N840VA JFK SFO
198763 2200 -75.0 AA 269 N3KCAA JFK SEA
195236 2324 -75.0 UA 612 N851UA EWR LAX
196935 2131 -74.0 AS 7 N551AS EWR SEA
... ... ... ... ... ... ... ...
336771 1634 NaN 9E 3393 NaN JFK DCA
336772 2312 NaN 9E 3525 NaN LGA SYR
336773 1330 NaN MQ 3461 N535MQ LGA BNA
336774 1344 NaN MQ 3572 N511MQ LGA CLE
336775 1020 NaN MQ 3531 N839MQ LGA RDU
air_time distance hour minute time_hour
199668 315.0 2565 17 29 2013-05-07 21:00:00+00:00
211124 316.0 2586 7 35 2013-05-20 11:00:00+00:00
198763 289.0 2422 18 30 2013-05-06 22:00:00+00:00
195236 300.0 2454 19 49 2013-05-02 23:00:00+00:00
196935 281.0 2402 18 20 2013-05-04 22:00:00+00:00
... ... ... ... ... ...
336771 NaN 213 14 55 2013-09-30 18:00:00+00:00
336772 NaN 198 22 0 2013-10-01 02:00:00+00:00
336773 NaN 764 12 10 2013-09-30 16:00:00+00:00
336774 NaN 419 11 59 2013-09-30 15:00:00+00:00
336775 NaN 431 8 40 2013-09-30 12:00:00+00:00
[336776 rows x 19 columns]
Sort in descending order:
= 'arr_delay' ,= False
year month day dep_time sched_dep_time dep_delay arr_time \
7072 2013 1 9 641.0 900 1301.0 1242.0
235778 2013 6 15 1432.0 1935 1137.0 1607.0
8239 2013 1 10 1121.0 1635 1126.0 1239.0
327043 2013 9 20 1139.0 1845 1014.0 1457.0
270376 2013 7 22 845.0 1600 1005.0 1044.0
... ... ... ... ... ... ... ...
336771 2013 9 30 NaN 1455 NaN NaN
336772 2013 9 30 NaN 2200 NaN NaN
336773 2013 9 30 NaN 1210 NaN NaN
336774 2013 9 30 NaN 1159 NaN NaN
336775 2013 9 30 NaN 840 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest \
7072 1530 1272.0 HA 51 N384HA JFK HNL
235778 2120 1127.0 MQ 3535 N504MQ JFK CMH
8239 1810 1109.0 MQ 3695 N517MQ EWR ORD
327043 2210 1007.0 AA 177 N338AA JFK SFO
270376 1815 989.0 MQ 3075 N665MQ JFK CVG
... ... ... ... ... ... ... ...
336771 1634 NaN 9E 3393 NaN JFK DCA
336772 2312 NaN 9E 3525 NaN LGA SYR
336773 1330 NaN MQ 3461 N535MQ LGA BNA
336774 1344 NaN MQ 3572 N511MQ LGA CLE
336775 1020 NaN MQ 3531 N839MQ LGA RDU
air_time distance hour minute time_hour
7072 640.0 4983 9 0 2013-01-09 14:00:00+00:00
235778 74.0 483 19 35 2013-06-15 23:00:00+00:00
8239 111.0 719 16 35 2013-01-10 21:00:00+00:00
327043 354.0 2586 18 45 2013-09-20 22:00:00+00:00
270376 96.0 589 16 0 2013-07-22 20:00:00+00:00
... ... ... ... ... ...
336771 NaN 213 14 55 2013-09-30 18:00:00+00:00
336772 NaN 198 22 0 2013-10-01 02:00:00+00:00
336773 NaN 764 12 10 2013-09-30 16:00:00+00:00
336774 NaN 419 11 59 2013-09-30 15:00:00+00:00
336775 NaN 431 8 40 2013-09-30 12:00:00+00:00
[336776 rows x 19 columns]
To sort within groups (month)
= ['month' , 'arr_delay' ],= [True , False ]
year month day dep_time sched_dep_time dep_delay arr_time \
7072 2013 1 9 641.0 900 1301.0 1242.0
8239 2013 1 10 1121.0 1635 1126.0 1239.0
151 2013 1 1 848.0 1835 853.0 1001.0
11063 2013 1 13 1809.0 810 599.0 2054.0
13654 2013 1 16 1622.0 800 502.0 1911.0
... ... ... ... ... ... ... ...
111291 2013 12 31 NaN 705 NaN NaN
111292 2013 12 31 NaN 825 NaN NaN
111293 2013 12 31 NaN 1615 NaN NaN
111294 2013 12 31 NaN 600 NaN NaN
111295 2013 12 31 NaN 830 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest \
7072 1530 1272.0 HA 51 N384HA JFK HNL
8239 1810 1109.0 MQ 3695 N517MQ EWR ORD
151 1950 851.0 MQ 3944 N942MQ JFK BWI
11063 1042 612.0 DL 269 N322NB JFK ATL
13654 1054 497.0 B6 517 N661JB EWR MCO
... ... ... ... ... ... ... ...
111291 931 NaN UA 1729 NaN EWR DEN
111292 1029 NaN US 1831 NaN JFK CLT
111293 1800 NaN MQ 3301 N844MQ LGA RDU
111294 735 NaN UA 219 NaN EWR ORD
111295 1154 NaN UA 443 NaN JFK LAX
air_time distance hour minute time_hour
7072 640.0 4983 9 0 2013-01-09 14:00:00+00:00
8239 111.0 719 16 35 2013-01-10 21:00:00+00:00
151 41.0 184 18 35 2013-01-01 23:00:00+00:00
11063 116.0 760 8 10 2013-01-13 13:00:00+00:00
13654 144.0 937 8 0 2013-01-16 13:00:00+00:00
... ... ... ... ... ...
111291 NaN 1605 7 5 2013-12-31 12:00:00+00:00
111292 NaN 541 8 25 2013-12-31 13:00:00+00:00
111293 NaN 431 16 15 2013-12-31 21:00:00+00:00
111294 NaN 719 6 0 2013-12-31 11:00:00+00:00
111295 NaN 2475 8 30 2013-12-31 13:00:00+00:00
[336776 rows x 19 columns]
Sort in ascending order:
sort (flights, [: arr_delay])
336776×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 5 7 1715 1729 -14.0 1944 ⋯
2 │ 2013 5 20 719 735 -16.0 951
3 │ 2013 5 2 1947 1949 -2.0 2209
4 │ 2013 5 6 1826 1830 -4.0 2045
5 │ 2013 5 4 1816 1820 -4.0 2017 ⋯
6 │ 2013 5 2 1926 1929 -3.0 2157
7 │ 2013 5 6 1753 1755 -2.0 2004
8 │ 2013 5 7 2054 2055 -1.0 2317
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 30 559 600 -1.0 missing ⋯
336771 │ 2013 9 30 missing 1842 missing missing
336772 │ 2013 9 30 missing 1455 missing missing
336773 │ 2013 9 30 missing 2200 missing missing
336774 │ 2013 9 30 missing 1210 missing missing ⋯
336775 │ 2013 9 30 missing 1159 missing missing
336776 │ 2013 9 30 missing 840 missing missing
12 columns and 336761 rows omitted
Sort in descending order:
sort (flights, [: arr_delay], rev = true )
336776×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 1525 1530 -5.0 1934 ⋯
2 │ 2013 1 1 1528 1459 29.0 2002
3 │ 2013 1 1 1740 1745 -5.0 2158
4 │ 2013 1 1 1807 1738 29.0 2251
5 │ 2013 1 1 1939 1840 59.0 29 ⋯
6 │ 2013 1 1 1952 1930 22.0 2358
7 │ 2013 1 1 2016 1930 46.0 missing
8 │ 2013 1 1 missing 1630 missing missing
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 5 13 657 700 -3.0 908 ⋯
336771 │ 2013 5 2 1926 1929 -3.0 2157
336772 │ 2013 5 4 1816 1820 -4.0 2017
336773 │ 2013 5 2 1947 1949 -2.0 2209
336774 │ 2013 5 6 1826 1830 -4.0 2045 ⋯
336775 │ 2013 5 20 719 735 -16.0 951
336776 │ 2013 5 7 1715 1729 -14.0 1944
12 columns and 336761 rows omitted
To sort within groups (month):
sort (flights, [: month, order (: arr_delay, rev= true )])
336776×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 1525 1530 -5.0 1934 ⋯
2 │ 2013 1 1 1528 1459 29.0 2002
3 │ 2013 1 1 1740 1745 -5.0 2158
4 │ 2013 1 1 1807 1738 29.0 2251
5 │ 2013 1 1 1939 1840 59.0 29 ⋯
6 │ 2013 1 1 1952 1930 22.0 2358
7 │ 2013 1 1 2016 1930 46.0 missing
8 │ 2013 1 1 missing 1630 missing missing
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 12 28 625 630 -5.0 916 ⋯
336771 │ 2013 12 29 818 830 -12.0 1056
336772 │ 2013 12 29 1017 1025 -8.0 1304
336773 │ 2013 12 27 1622 1630 -8.0 1908
336774 │ 2013 12 27 1728 1729 -1.0 2011 ⋯
336775 │ 2013 12 27 1833 1836 -3.0 2050
336776 │ 2013 12 27 853 856 -3.0 1052
12 columns and 336761 rows omitted
Manipulate columns (variables)
Select columns with select()
Select columns by variable names:
select (flights, year, month, day)
# A tibble: 336,776 × 3
year month day
<int> <int> <int>
1 2013 1 1
2 2013 1 1
3 2013 1 1
4 2013 1 1
5 2013 1 1
6 2013 1 1
7 2013 1 1
8 2013 1 1
9 2013 1 1
10 2013 1 1
# … with 336,766 more rows
'year' , 'month' , 'day' ]]
year month day
0 2013 1 1
1 2013 1 1
2 2013 1 1
3 2013 1 1
4 2013 1 1
... ... ... ...
336771 2013 9 30
336772 2013 9 30
336773 2013 9 30
336774 2013 9 30
336775 2013 9 30
[336776 rows x 3 columns]
select (flights, [: year, : month, : day])
336776×3 DataFrame
Row │ year month day
│ Int64 Int64 Int64
────────┼─────────────────────
1 │ 2013 1 1
2 │ 2013 1 1
3 │ 2013 1 1
4 │ 2013 1 1
5 │ 2013 1 1
6 │ 2013 1 1
7 │ 2013 1 1
8 │ 2013 1 1
⋮ │ ⋮ ⋮ ⋮
336770 │ 2013 9 30
336771 │ 2013 9 30
336772 │ 2013 9 30
336773 │ 2013 9 30
336774 │ 2013 9 30
336775 │ 2013 9 30
336776 │ 2013 9 30
336761 rows omitted
Pull values of one column as a vector:
Not displayed because the vector is long.
# Following are same 'year' ]
# Return a vector # Return a vector "year" # Return a vector : year] # does not make a copy # Return a vector "year" ] # does not make a copy # Return a vector : , : year] # make a copy! # Return a vector : , "year" ] # make a copy!
Select columns between two variables:
select (flights, year: day)
# A tibble: 336,776 × 3
year month day
<int> <int> <int>
1 2013 1 1
2 2013 1 1
3 2013 1 1
4 2013 1 1
5 2013 1 1
6 2013 1 1
7 2013 1 1
8 2013 1 1
9 2013 1 1
10 2013 1 1
# … with 336,766 more rows
'year' :'day' ]
year month day
0 2013 1 1
1 2013 1 1
2 2013 1 1
3 2013 1 1
4 2013 1 1
... ... ... ...
336771 2013 9 30
336772 2013 9 30
336773 2013 9 30
336774 2013 9 30
336775 2013 9 30
[336776 rows x 3 columns]
select (flights, Between (: year, : day))
336776×3 DataFrame
Row │ year month day
│ Int64 Int64 Int64
────────┼─────────────────────
1 │ 2013 1 1
2 │ 2013 1 1
3 │ 2013 1 1
4 │ 2013 1 1
5 │ 2013 1 1
6 │ 2013 1 1
7 │ 2013 1 1
8 │ 2013 1 1
⋮ │ ⋮ ⋮ ⋮
336770 │ 2013 9 30
336771 │ 2013 9 30
336772 │ 2013 9 30
336773 │ 2013 9 30
336774 │ 2013 9 30
336775 │ 2013 9 30
336776 │ 2013 9 30
336761 rows omitted
Select all columns except those between two variables:
select (flights, - (year: day))
# A tibble: 336,776 × 16
dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum origin
<int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> <chr>
1 517 515 2 830 819 11 UA 1545 N14228 EWR
2 533 529 4 850 830 20 UA 1714 N24211 LGA
3 542 540 2 923 850 33 AA 1141 N619AA JFK
4 544 545 -1 1004 1022 -18 B6 725 N804JB JFK
5 554 600 -6 812 837 -25 DL 461 N668DN LGA
6 554 558 -4 740 728 12 UA 1696 N39463 EWR
7 555 600 -5 913 854 19 B6 507 N516JB EWR
8 557 600 -3 709 723 -14 EV 5708 N829AS LGA
9 557 600 -3 838 846 -8 B6 79 N593JB JFK
10 558 600 -2 753 745 8 AA 301 N3ALAA LGA
# … with 336,766 more rows, 6 more variables: dest <chr>, air_time <dbl>,
# distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated
# variable names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time,
# ⁵sched_arr_time, ⁶arr_delay
'year' :'day' ].columns, axis = 1 )
dep_time sched_dep_time dep_delay arr_time sched_arr_time \
0 517.0 515 2.0 830.0 819
1 533.0 529 4.0 850.0 830
2 542.0 540 2.0 923.0 850
3 544.0 545 -1.0 1004.0 1022
4 554.0 600 -6.0 812.0 837
... ... ... ... ... ...
336771 NaN 1455 NaN NaN 1634
336772 NaN 2200 NaN NaN 2312
336773 NaN 1210 NaN NaN 1330
336774 NaN 1159 NaN NaN 1344
336775 NaN 840 NaN NaN 1020
arr_delay carrier flight tailnum origin dest air_time distance \
0 11.0 UA 1545 N14228 EWR IAH 227.0 1400
1 20.0 UA 1714 N24211 LGA IAH 227.0 1416
2 33.0 AA 1141 N619AA JFK MIA 160.0 1089
3 -18.0 B6 725 N804JB JFK BQN 183.0 1576
4 -25.0 DL 461 N668DN LGA ATL 116.0 762
... ... ... ... ... ... ... ... ...
336771 NaN 9E 3393 NaN JFK DCA NaN 213
336772 NaN 9E 3525 NaN LGA SYR NaN 198
336773 NaN MQ 3461 N535MQ LGA BNA NaN 764
336774 NaN MQ 3572 N511MQ LGA CLE NaN 419
336775 NaN MQ 3531 N839MQ LGA RDU NaN 431
hour minute time_hour
0 5 15 2013-01-01 10:00:00+00:00
1 5 29 2013-01-01 10:00:00+00:00
2 5 40 2013-01-01 10:00:00+00:00
3 5 45 2013-01-01 10:00:00+00:00
4 6 0 2013-01-01 11:00:00+00:00
... ... ... ...
336771 14 55 2013-09-30 18:00:00+00:00
336772 22 0 2013-10-01 02:00:00+00:00
336773 12 10 2013-09-30 16:00:00+00:00
336774 11 59 2013-09-30 15:00:00+00:00
336775 8 40 2013-09-30 12:00:00+00:00
[336776 rows x 16 columns]
select (flights, Not (Between (: year, : day)))
336776×16 DataFrame
Row │ dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_d ⋯
│ Int64? Int64 Float64? Int64? Int64 Float ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 517 515 2.0 830 819 ⋯
2 │ 533 529 4.0 850 830
3 │ 542 540 2.0 923 850
4 │ 544 545 -1.0 1004 1022 -
5 │ 554 600 -6.0 812 837 - ⋯
6 │ 554 558 -4.0 740 728
7 │ 555 600 -5.0 913 854
8 │ 557 600 -3.0 709 723 -
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2349 2359 -10.0 325 350 - ⋯
336771 │ missing 1842 missing missing 2019 missi
336772 │ missing 1455 missing missing 1634 missi
336773 │ missing 2200 missing missing 2312 missi
336774 │ missing 1210 missing missing 1330 missi ⋯
336775 │ missing 1159 missing missing 1344 missi
336776 │ missing 840 missing missing 1020 missi
11 columns and 336761 rows omitted
Select columns by positions:
select (flights, seq (1 , 10 , by = 2 ))
# A tibble: 336,776 × 5
year day sched_dep_time arr_time arr_delay
<int> <int> <int> <int> <dbl>
1 2013 1 515 830 11
2 2013 1 529 850 20
3 2013 1 540 923 33
4 2013 1 545 1004 -18
5 2013 1 600 812 -25
6 2013 1 558 740 12
7 2013 1 600 913 19
8 2013 1 600 709 -14
9 2013 1 600 838 -8
10 2013 1 600 753 8
# … with 336,766 more rows
range (0 , 9 , 2 )]
year day sched_dep_time arr_time arr_delay
0 2013 1 515 830.0 11.0
1 2013 1 529 850.0 20.0
2 2013 1 540 923.0 33.0
3 2013 1 545 1004.0 -18.0
4 2013 1 600 812.0 -25.0
... ... ... ... ... ...
336771 2013 30 1455 NaN NaN
336772 2013 30 2200 NaN NaN
336773 2013 30 1210 NaN NaN
336774 2013 30 1159 NaN NaN
336775 2013 30 840 NaN NaN
[336776 rows x 5 columns]
336776×5 DataFrame
Row │ year day sched_dep_time arr_time arr_delay
│ Int64 Int64 Int64 Int64? Float64?
────────┼───────────────────────────────────────────────────
1 │ 2013 1 515 830 11.0
2 │ 2013 1 529 850 20.0
3 │ 2013 1 540 923 33.0
4 │ 2013 1 545 1004 -18.0
5 │ 2013 1 600 812 -25.0
6 │ 2013 1 558 740 12.0
7 │ 2013 1 600 913 19.0
8 │ 2013 1 600 709 -14.0
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮
336770 │ 2013 30 2359 325 -25.0
336771 │ 2013 30 1842 missing missing
336772 │ 2013 30 1455 missing missing
336773 │ 2013 30 2200 missing missing
336774 │ 2013 30 1210 missing missing
336775 │ 2013 30 1159 missing missing
336776 │ 2013 30 840 missing missing
336761 rows omitted
Move variables to the start of data frame:
select (flights, time_hour, air_time, everything ())
# A tibble: 336,776 × 19
time_hour air_t…¹ year month day dep_t…² sched…³ dep_d…⁴ arr_t…⁵
<dttm> <dbl> <int> <int> <int> <int> <int> <dbl> <int>
1 2013-01-01 05:00:00 227 2013 1 1 517 515 2 830
2 2013-01-01 05:00:00 227 2013 1 1 533 529 4 850
3 2013-01-01 05:00:00 160 2013 1 1 542 540 2 923
4 2013-01-01 05:00:00 183 2013 1 1 544 545 -1 1004
5 2013-01-01 06:00:00 116 2013 1 1 554 600 -6 812
6 2013-01-01 05:00:00 150 2013 1 1 554 558 -4 740
7 2013-01-01 06:00:00 158 2013 1 1 555 600 -5 913
8 2013-01-01 06:00:00 53 2013 1 1 557 600 -3 709
9 2013-01-01 06:00:00 140 2013 1 1 557 600 -3 838
10 2013-01-01 06:00:00 138 2013 1 1 558 600 -2 753
# … with 336,766 more rows, 10 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>, origin <chr>,
# dest <chr>, distance <dbl>, hour <dbl>, minute <dbl>, and abbreviated
# variable names ¹air_time, ²dep_time, ³sched_dep_time, ⁴dep_delay, ⁵arr_time
Not sure what’s the optimal way to do this.
# Note time_hour is missing in Python dataframe = ['arr_delay' , 'air_time' ]+ [x for x in flights.columns if x not in cols_to_move]]
arr_delay air_time year month day dep_time sched_dep_time \
0 11.0 227.0 2013 1 1 517.0 515
1 20.0 227.0 2013 1 1 533.0 529
2 33.0 160.0 2013 1 1 542.0 540
3 -18.0 183.0 2013 1 1 544.0 545
4 -25.0 116.0 2013 1 1 554.0 600
... ... ... ... ... ... ... ...
336771 NaN NaN 2013 9 30 NaN 1455
336772 NaN NaN 2013 9 30 NaN 2200
336773 NaN NaN 2013 9 30 NaN 1210
336774 NaN NaN 2013 9 30 NaN 1159
336775 NaN NaN 2013 9 30 NaN 840
dep_delay arr_time sched_arr_time carrier flight tailnum origin \
0 2.0 830.0 819 UA 1545 N14228 EWR
1 4.0 850.0 830 UA 1714 N24211 LGA
2 2.0 923.0 850 AA 1141 N619AA JFK
3 -1.0 1004.0 1022 B6 725 N804JB JFK
4 -6.0 812.0 837 DL 461 N668DN LGA
... ... ... ... ... ... ... ...
336771 NaN NaN 1634 9E 3393 NaN JFK
336772 NaN NaN 2312 9E 3525 NaN LGA
336773 NaN NaN 1330 MQ 3461 N535MQ LGA
336774 NaN NaN 1344 MQ 3572 N511MQ LGA
336775 NaN NaN 1020 MQ 3531 N839MQ LGA
dest distance hour minute time_hour
0 IAH 1400 5 15 2013-01-01 10:00:00+00:00
1 IAH 1416 5 29 2013-01-01 10:00:00+00:00
2 MIA 1089 5 40 2013-01-01 10:00:00+00:00
3 BQN 1576 5 45 2013-01-01 10:00:00+00:00
4 ATL 762 6 0 2013-01-01 11:00:00+00:00
... ... ... ... ... ...
336771 DCA 213 14 55 2013-09-30 18:00:00+00:00
336772 SYR 198 22 0 2013-10-01 02:00:00+00:00
336773 BNA 764 12 10 2013-09-30 16:00:00+00:00
336774 CLE 419 11 59 2013-09-30 15:00:00+00:00
336775 RDU 431 8 40 2013-09-30 12:00:00+00:00
[336776 rows x 19 columns]
select (flights, : time_hour, : air_time, Not ([: time_hour, : air_time]))
336776×19 DataFrame
Row │ time_hour air_time year month day dep_time sched ⋯
│ DateTime Float64? Int64 Int64 Int64 Int64? Int64 ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013-01-01T10:00:00 227.0 2013 1 1 517 ⋯
2 │ 2013-01-01T10:00:00 227.0 2013 1 1 533
3 │ 2013-01-01T10:00:00 160.0 2013 1 1 542
4 │ 2013-01-01T10:00:00 183.0 2013 1 1 544
5 │ 2013-01-01T11:00:00 116.0 2013 1 1 554 ⋯
6 │ 2013-01-01T10:00:00 150.0 2013 1 1 554
7 │ 2013-01-01T11:00:00 158.0 2013 1 1 555
8 │ 2013-01-01T11:00:00 53.0 2013 1 1 557
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013-10-01T03:00:00 196.0 2013 9 30 2349 ⋯
336771 │ 2013-09-30T22:00:00 missing 2013 9 30 missing
336772 │ 2013-09-30T18:00:00 missing 2013 9 30 missing
336773 │ 2013-10-01T02:00:00 missing 2013 9 30 missing
336774 │ 2013-09-30T16:00:00 missing 2013 9 30 missing ⋯
336775 │ 2013-09-30T15:00:00 missing 2013 9 30 missing
336776 │ 2013-09-30T12:00:00 missing 2013 9 30 missing
13 columns and 336761 rows omitted
Add new variables with mutate()
A tibble with fewer columns.
<- select (flights, year: day, ends_with ("delay" ), distance, air_time)
# A tibble: 336,776 × 7
year month day dep_delay arr_delay distance air_time
<int> <int> <int> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 2 11 1400 227
2 2013 1 1 4 20 1416 227
3 2013 1 1 2 33 1089 160
4 2013 1 1 -1 -18 1576 183
5 2013 1 1 -6 -25 762 116
6 2013 1 1 -4 12 719 150
7 2013 1 1 -5 19 1065 158
8 2013 1 1 -3 -14 229 53
9 2013 1 1 -3 -8 944 140
10 2013 1 1 -2 8 733 138
# … with 336,766 more rows
Is there better way?
import re= ['year' , 'month' , 'day' ] + list (filter (re.compile (".*delay" ).match, flights.columns)) + ['distance' , 'air_time' ]= flights.loc[:, cols]
year month day dep_delay arr_delay distance air_time
0 2013 1 1 2.0 11.0 1400 227.0
1 2013 1 1 4.0 20.0 1416 227.0
2 2013 1 1 2.0 33.0 1089 160.0
3 2013 1 1 -1.0 -18.0 1576 183.0
4 2013 1 1 -6.0 -25.0 762 116.0
... ... ... ... ... ... ... ...
336771 2013 9 30 NaN NaN 213 NaN
336772 2013 9 30 NaN NaN 198 NaN
336773 2013 9 30 NaN NaN 764 NaN
336774 2013 9 30 NaN NaN 419 NaN
336775 2013 9 30 NaN NaN 431 NaN
[336776 rows x 7 columns]
= select (flights, Between (: year, : day), r" .* delay $ ", : distance, :air_time )
336776×7 DataFrame
Row │ year month day dep_delay arr_delay distance air_time
│ Int64 Int64 Int64 Float64? Float64? Float64 Float64?
────────┼────────────────────────────────────────────────────────────────
1 │ 2013 1 1 2.0 11.0 1400.0 227.0
2 │ 2013 1 1 4.0 20.0 1416.0 227.0
3 │ 2013 1 1 2.0 33.0 1089.0 160.0
4 │ 2013 1 1 -1.0 -18.0 1576.0 183.0
5 │ 2013 1 1 -6.0 -25.0 762.0 116.0
6 │ 2013 1 1 -4.0 12.0 719.0 150.0
7 │ 2013 1 1 -5.0 19.0 1065.0 158.0
8 │ 2013 1 1 -3.0 -14.0 229.0 53.0
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
336770 │ 2013 9 30 -10.0 -25.0 1617.0 196.0
336771 │ 2013 9 30 missing missing 764.0 missing
336772 │ 2013 9 30 missing missing 213.0 missing
336773 │ 2013 9 30 missing missing 198.0 missing
336774 │ 2013 9 30 missing missing 764.0 missing
336775 │ 2013 9 30 missing missing 419.0 missing
336776 │ 2013 9 30 missing missing 431.0 missing
336761 rows omitted
336776×7 DataFrame
Row │ year month day dep_delay arr_delay distance air_time
│ Int64 Int64 Int64 Float64? Float64? Float64 Float64?
────────┼────────────────────────────────────────────────────────────────
1 │ 2013 1 1 2.0 11.0 1400.0 227.0
2 │ 2013 1 1 4.0 20.0 1416.0 227.0
3 │ 2013 1 1 2.0 33.0 1089.0 160.0
4 │ 2013 1 1 -1.0 -18.0 1576.0 183.0
5 │ 2013 1 1 -6.0 -25.0 762.0 116.0
6 │ 2013 1 1 -4.0 12.0 719.0 150.0
7 │ 2013 1 1 -5.0 19.0 1065.0 158.0
8 │ 2013 1 1 -3.0 -14.0 229.0 53.0
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
336770 │ 2013 9 30 -10.0 -25.0 1617.0 196.0
336771 │ 2013 9 30 missing missing 764.0 missing
336772 │ 2013 9 30 missing missing 213.0 missing
336773 │ 2013 9 30 missing missing 198.0 missing
336774 │ 2013 9 30 missing missing 764.0 missing
336775 │ 2013 9 30 missing missing 419.0 missing
336776 │ 2013 9 30 missing missing 431.0 missing
336761 rows omitted
Add variables gain and speed:
mutate (gain = arr_delay - dep_delay,speed = distance / air_time * 60
# A tibble: 336,776 × 9
year month day dep_delay arr_delay distance air_time gain speed
<int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 2 11 1400 227 9 370.
2 2013 1 1 4 20 1416 227 16 374.
3 2013 1 1 2 33 1089 160 31 408.
4 2013 1 1 -1 -18 1576 183 -17 517.
5 2013 1 1 -6 -25 762 116 -19 394.
6 2013 1 1 -4 12 719 150 16 288.
7 2013 1 1 -5 19 1065 158 24 404.
8 2013 1 1 -3 -14 229 53 -11 259.
9 2013 1 1 -3 -8 944 140 -5 405.
10 2013 1 1 -2 8 733 138 10 319.
# … with 336,766 more rows
'gain' ] = flights_sml['arr_delay' ] - flights_sml['dep_delay' ]'speed' ] = flights_sml['distance' ] / flights_sml['air_time' ] * 60
year month day dep_delay arr_delay distance air_time gain \
0 2013 1 1 2.0 11.0 1400 227.0 9.0
1 2013 1 1 4.0 20.0 1416 227.0 16.0
2 2013 1 1 2.0 33.0 1089 160.0 31.0
3 2013 1 1 -1.0 -18.0 1576 183.0 -17.0
4 2013 1 1 -6.0 -25.0 762 116.0 -19.0
... ... ... ... ... ... ... ... ...
336771 2013 9 30 NaN NaN 213 NaN NaN
336772 2013 9 30 NaN NaN 198 NaN NaN
336773 2013 9 30 NaN NaN 764 NaN NaN
336774 2013 9 30 NaN NaN 419 NaN NaN
336775 2013 9 30 NaN NaN 431 NaN NaN
speed
0 370.044053
1 374.273128
2 408.375000
3 516.721311
4 394.137931
... ...
336771 NaN
336772 NaN
336773 NaN
336774 NaN
336775 NaN
[336776 rows x 9 columns]
Julia analog is transform:
# Following are equivalent transform (flights_sml, [: arr_delay, : dep_delay] => (- ) => : gain)
336776×8 DataFrame
Row │ year month day dep_delay arr_delay distance air_time gain ⋯
│ Int64 Int64 Int64 Float64? Float64? Float64 Float64? Floa ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 2.0 11.0 1400.0 227.0 ⋯
2 │ 2013 1 1 4.0 20.0 1416.0 227.0
3 │ 2013 1 1 2.0 33.0 1089.0 160.0
4 │ 2013 1 1 -1.0 -18.0 1576.0 183.0
5 │ 2013 1 1 -6.0 -25.0 762.0 116.0 ⋯
6 │ 2013 1 1 -4.0 12.0 719.0 150.0
7 │ 2013 1 1 -5.0 19.0 1065.0 158.0
8 │ 2013 1 1 -3.0 -14.0 229.0 53.0
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 30 -10.0 -25.0 1617.0 196.0 ⋯
336771 │ 2013 9 30 missing missing 764.0 missing miss
336772 │ 2013 9 30 missing missing 213.0 missing miss
336773 │ 2013 9 30 missing missing 198.0 missing miss
336774 │ 2013 9 30 missing missing 764.0 missing miss ⋯
336775 │ 2013 9 30 missing missing 419.0 missing miss
336776 │ 2013 9 30 missing missing 431.0 missing miss
1 column and 336761 rows omitted
insertcols! (flights_sml, : gain => flights.arr_delay - flights.dep_delay)
336776×8 DataFrame
Row │ year month day dep_delay arr_delay distance air_time gain ⋯
│ Int64 Int64 Int64 Float64? Float64? Float64 Float64? Floa ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 2.0 11.0 1400.0 227.0 ⋯
2 │ 2013 1 1 4.0 20.0 1416.0 227.0
3 │ 2013 1 1 2.0 33.0 1089.0 160.0
4 │ 2013 1 1 -1.0 -18.0 1576.0 183.0
5 │ 2013 1 1 -6.0 -25.0 762.0 116.0 ⋯
6 │ 2013 1 1 -4.0 12.0 719.0 150.0
7 │ 2013 1 1 -5.0 19.0 1065.0 158.0
8 │ 2013 1 1 -3.0 -14.0 229.0 53.0
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 30 -10.0 -25.0 1617.0 196.0 ⋯
336771 │ 2013 9 30 missing missing 764.0 missing miss
336772 │ 2013 9 30 missing missing 213.0 missing miss
336773 │ 2013 9 30 missing missing 198.0 missing miss
336774 │ 2013 9 30 missing missing 764.0 missing miss ⋯
336775 │ 2013 9 30 missing missing 419.0 missing miss
336776 │ 2013 9 30 missing missing 431.0 missing miss
1 column and 336761 rows omitted
Refer to columns that you’ve just created:
mutate (flights_sml,gain = arr_delay - dep_delay,hours = air_time / 60 ,gain_per_hour = gain / hours
# A tibble: 336,776 × 10
year month day dep_delay arr_delay distance air_time gain hours gain_pe…¹
<int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 2 11 1400 227 9 3.78 2.38
2 2013 1 1 4 20 1416 227 16 3.78 4.23
3 2013 1 1 2 33 1089 160 31 2.67 11.6
4 2013 1 1 -1 -18 1576 183 -17 3.05 -5.57
5 2013 1 1 -6 -25 762 116 -19 1.93 -9.83
6 2013 1 1 -4 12 719 150 16 2.5 6.4
7 2013 1 1 -5 19 1065 158 24 2.63 9.11
8 2013 1 1 -3 -14 229 53 -11 0.883 -12.5
9 2013 1 1 -3 -8 944 140 -5 2.33 -2.14
10 2013 1 1 -2 8 733 138 10 2.3 4.35
# … with 336,766 more rows, and abbreviated variable name ¹gain_per_hour
Not sure how to refer to columns in the same command.
Not sure how to do this, except using two lines.
# Following are equivalent @pipe flights |> transform (: arr_delay, : dep_delay] => (- ) => : gain,: air_time] => (x -> x / 60 ) => : hours,|> transform (: gain, : hours] => ByRow (/ ) => : gain_per_hour
336776×22 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
3 │ 2013 1 1 542 540 2.0 923
4 │ 2013 1 1 544 545 -1.0 1004
5 │ 2013 1 1 554 600 -6.0 812 ⋯
6 │ 2013 1 1 554 558 -4.0 740
7 │ 2013 1 1 555 600 -5.0 913
8 │ 2013 1 1 557 600 -3.0 709
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 30 2349 2359 -10.0 325 ⋯
336771 │ 2013 9 30 missing 1842 missing missing
336772 │ 2013 9 30 missing 1455 missing missing
336773 │ 2013 9 30 missing 2200 missing missing
336774 │ 2013 9 30 missing 1210 missing missing ⋯
336775 │ 2013 9 30 missing 1159 missing missing
336776 │ 2013 9 30 missing 840 missing missing
15 columns and 336761 rows omitted
Only keep the new variables by transmute():
transmute (gain = arr_delay - dep_delay,hours = air_time / 60 ,gain_per_hour = gain / hours
# A tibble: 336,776 × 3
gain hours gain_per_hour
<dbl> <dbl> <dbl>
1 9 3.78 2.38
2 16 3.78 4.23
3 31 2.67 11.6
4 -17 3.05 -5.57
5 -19 1.93 -9.83
6 16 2.5 6.4
7 24 2.63 9.11
8 -11 0.883 -12.5
9 -5 2.33 -2.14
10 10 2.3 4.35
# … with 336,766 more rows
mutate_all(): apply funs to all columns.
mutate_all (data, funs (log (.), log2 (.)))
mutate_at(): apply funs to specific columns.
mutate_at (data, vars (- Species), funs (log (.)))
mutate_if(): apply funs of one type
mutate_if (data, is.numeric, funs (log (.)))
Summaries
Summaries with summarise()
summarise (flights, delay = mean (dep_delay, na.rm = TRUE ))
# A tibble: 1 × 1
delay
<dbl>
1 12.6
'dep_delay' : np.mean})
dep_delay 12.63907
dtype: float64
combine (flights, : dep_delay => (x -> mean (skipmissing (x))) => : delay)
1×1 DataFrame
Row │ delay
│ Float64
─────┼─────────
1 │ 12.6391
Convert a tibble into a grouped tibble:
<- group_by (flights, year, month, day) %>% print (width = Inf )
# A tibble: 336,776 × 19
# Groups: year, month, day [365]
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
arr_delay carrier flight tailnum origin dest air_time distance hour minute
<dbl> <chr> <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 11 UA 1545 N14228 EWR IAH 227 1400 5 15
2 20 UA 1714 N24211 LGA IAH 227 1416 5 29
3 33 AA 1141 N619AA JFK MIA 160 1089 5 40
4 -18 B6 725 N804JB JFK BQN 183 1576 5 45
5 -25 DL 461 N668DN LGA ATL 116 762 6 0
6 12 UA 1696 N39463 EWR ORD 150 719 5 58
7 19 B6 507 N516JB EWR FLL 158 1065 6 0
8 -14 EV 5708 N829AS LGA IAD 53 229 6 0
9 -8 B6 79 N593JB JFK MCO 140 944 6 0
10 8 AA 301 N3ALAA LGA ORD 138 733 6 0
time_hour
<dttm>
1 2013-01-01 05:00:00
2 2013-01-01 05:00:00
3 2013-01-01 05:00:00
4 2013-01-01 05:00:00
5 2013-01-01 06:00:00
6 2013-01-01 05:00:00
7 2013-01-01 06:00:00
8 2013-01-01 06:00:00
9 2013-01-01 06:00:00
10 2013-01-01 06:00:00
# … with 336,766 more rows
= flights.groupby(['year' , 'month' , 'day' ])
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x12b5b0610>
= groupby (flights, [: year, : month, : day])
GroupedDataFrame with 365 groups based on keys: year, month, day
First Group (842 rows): year = 2013, month = 1, day = 1
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
841 │ 2013 1 1 missing 1500 missing missing
842 │ 2013 1 1 missing 600 missing missing
12 columns and 838 rows omitted
⋮
Last Group (776 rows): year = 2013, month = 12, day = 31
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 12 31 13 2359 14.0 439 ⋯
2 │ 2013 12 31 18 2359 19.0 449
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
776 │ 2013 12 31 missing 830 missing missing
12 columns and 773 rows omitted
GroupedDataFrame with 365 groups based on keys: year, month, day
First Group (842 rows): year = 2013, month = 1, day = 1
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
841 │ 2013 1 1 missing 1500 missing missing
842 │ 2013 1 1 missing 600 missing missing
12 columns and 838 rows omitted
⋮
Last Group (776 rows): year = 2013, month = 12, day = 31
Row │ year month day dep_time sched_dep_time dep_delay arr_time sch ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? Int ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ 2013 12 31 13 2359 14.0 439 ⋯
2 │ 2013 12 31 18 2359 19.0 449
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
776 │ 2013 12 31 missing 830 missing missing
12 columns and 773 rows omitted
summarise (by_day, delay = mean (dep_delay, na.rm = TRUE ))
# A tibble: 365 × 4
# Groups: year, month [12]
year month day delay
<int> <int> <int> <dbl>
1 2013 1 1 11.5
2 2013 1 2 13.9
3 2013 1 3 11.0
4 2013 1 4 8.95
5 2013 1 5 5.73
6 2013 1 6 7.15
7 2013 1 7 5.42
8 2013 1 8 2.55
9 2013 1 9 2.28
10 2013 1 10 2.84
# … with 355 more rows
Pipe
Consider following analysis (find destinations excluding HNL that have >20 flights, and calculate the average distances and arrival delay):
<- group_by (flights, dest)<- summarise (by_dest, count = n (),dist = mean (distance, na.rm = TRUE ),delay = mean (arr_delay, na.rm = TRUE )<- filter (delay, count > 20 , dest != "HNL" )
# A tibble: 96 × 4
dest count dist delay
<chr> <int> <dbl> <dbl>
1 ABQ 254 1826 4.38
2 ACK 265 199 4.85
3 ALB 439 143 14.4
4 ATL 17215 757. 11.3
5 AUS 2439 1514. 6.02
6 AVL 275 584. 8.00
7 BDL 443 116 7.05
8 BGR 375 378 8.03
9 BHM 297 866. 16.9
10 BNA 6333 758. 11.8
# … with 86 more rows
Cleaner code using pipe %>%:
<- flights %>% group_by (dest) %>% summarise (count = n (),dist = mean (distance, na.rm = TRUE ),delay = mean (arr_delay, na.rm = TRUE )%>% filter (count > 20 , dest != "HNL" )
# A tibble: 96 × 4
dest count dist delay
<chr> <int> <dbl> <dbl>
1 ABQ 254 1826 4.38
2 ACK 265 199 4.85
3 ALB 439 143 14.4
4 ATL 17215 757. 11.3
5 AUS 2439 1514. 6.02
6 AVL 275 584. 8.00
7 BDL 443 116 7.05
8 BGR 375 378 8.03
9 BHM 297 866. 16.9
10 BNA 6333 758. 11.8
# … with 86 more rows
ggplot2 accepts pipe too.
%>% ggplot (mapping = aes (x = dist, y = delay)) + geom_point (aes (size = count), alpha = 1 / 3 ) + geom_smooth (se = FALSE ) + labs (x = "Distance from NYC (miles)" ,y = "Arrival delay (mins)" )
Other summary functions
Location: mean(x), median(x).
# Equivalent code using filter # not_cancelled <- flights %>% # filter(!is.na(dep_delay), !is.na(arr_delay)) %>% # print(width = Inf) <- flights %>% drop_na (dep_delay, arr_delay) %>% print (width = Inf )
# A tibble: 327,346 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
arr_delay carrier flight tailnum origin dest air_time distance hour minute
<dbl> <chr> <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 11 UA 1545 N14228 EWR IAH 227 1400 5 15
2 20 UA 1714 N24211 LGA IAH 227 1416 5 29
3 33 AA 1141 N619AA JFK MIA 160 1089 5 40
4 -18 B6 725 N804JB JFK BQN 183 1576 5 45
5 -25 DL 461 N668DN LGA ATL 116 762 6 0
6 12 UA 1696 N39463 EWR ORD 150 719 5 58
7 19 B6 507 N516JB EWR FLL 158 1065 6 0
8 -14 EV 5708 N829AS LGA IAD 53 229 6 0
9 -8 B6 79 N593JB JFK MCO 140 944 6 0
10 8 AA 301 N3ALAA LGA ORD 138 733 6 0
time_hour
<dttm>
1 2013-01-01 05:00:00
2 2013-01-01 05:00:00
3 2013-01-01 05:00:00
4 2013-01-01 05:00:00
5 2013-01-01 06:00:00
6 2013-01-01 05:00:00
7 2013-01-01 06:00:00
8 2013-01-01 06:00:00
9 2013-01-01 06:00:00
10 2013-01-01 06:00:00
# … with 327,336 more rows
%>% group_by (year, month, day) %>% summarise (avg_delay1 = mean (arr_delay),avg_delay2 = mean (arr_delay[arr_delay > 0 ]) # the average positive delay
# A tibble: 365 × 5
# Groups: year, month [12]
year month day avg_delay1 avg_delay2
<int> <int> <int> <dbl> <dbl>
1 2013 1 1 12.7 32.5
2 2013 1 2 12.7 32.0
3 2013 1 3 5.73 27.7
4 2013 1 4 -1.93 28.3
5 2013 1 5 -1.53 22.6
6 2013 1 6 4.24 24.4
7 2013 1 7 -4.95 27.8
8 2013 1 8 -3.23 20.8
9 2013 1 9 -0.264 25.6
10 2013 1 10 -5.90 27.3
# … with 355 more rows
= flights.dropna(subset = ['dep_delay' , 'arr_delay' ])
year month day dep_time sched_dep_time dep_delay arr_time \
0 2013 1 1 517.0 515 2.0 830.0
1 2013 1 1 533.0 529 4.0 850.0
2 2013 1 1 542.0 540 2.0 923.0
3 2013 1 1 544.0 545 -1.0 1004.0
4 2013 1 1 554.0 600 -6.0 812.0
... ... ... ... ... ... ... ...
336765 2013 9 30 2240.0 2245 -5.0 2334.0
336766 2013 9 30 2240.0 2250 -10.0 2347.0
336767 2013 9 30 2241.0 2246 -5.0 2345.0
336768 2013 9 30 2307.0 2255 12.0 2359.0
336769 2013 9 30 2349.0 2359 -10.0 325.0
sched_arr_time arr_delay carrier flight tailnum origin dest \
0 819 11.0 UA 1545 N14228 EWR IAH
1 830 20.0 UA 1714 N24211 LGA IAH
2 850 33.0 AA 1141 N619AA JFK MIA
3 1022 -18.0 B6 725 N804JB JFK BQN
4 837 -25.0 DL 461 N668DN LGA ATL
... ... ... ... ... ... ... ...
336765 2351 -17.0 B6 1816 N354JB JFK SYR
336766 7 -20.0 B6 2002 N281JB JFK BUF
336767 1 -16.0 B6 486 N346JB JFK ROC
336768 2358 1.0 B6 718 N565JB JFK BOS
336769 350 -25.0 B6 745 N516JB JFK PSE
air_time distance hour minute time_hour
0 227.0 1400 5 15 2013-01-01 10:00:00+00:00
1 227.0 1416 5 29 2013-01-01 10:00:00+00:00
2 160.0 1089 5 40 2013-01-01 10:00:00+00:00
3 183.0 1576 5 45 2013-01-01 10:00:00+00:00
4 116.0 762 6 0 2013-01-01 11:00:00+00:00
... ... ... ... ... ...
336765 41.0 209 22 45 2013-10-01 02:00:00+00:00
336766 52.0 301 22 50 2013-10-01 02:00:00+00:00
336767 47.0 264 22 46 2013-10-01 02:00:00+00:00
336768 33.0 187 22 55 2013-10-01 02:00:00+00:00
336769 196.0 1617 23 59 2013-10-01 03:00:00+00:00
[327346 rows x 19 columns]
'year' , 'month' , 'day' ]).agg(= ('arr_delay' , np.mean), = ('arr_delay' , lambda x: np.mean(x[x > 0 ]))
avg_delay1 avg_delay2
year month day
2013 1 1 12.651023 32.481562
2 12.692888 32.029907
3 5.733333 27.660870
4 -1.932819 28.309764
5 -1.525802 22.558824
6 4.236429 24.372703
7 -4.947312 27.761317
8 -3.227578 20.789091
9 -0.264278 25.634146
10 -5.898816 27.345455
11 -4.762268 26.159836
12 -13.016153 23.471698
13 14.931846 52.548913
14 3.640303 22.444444
15 0.425653 19.710027
16 34.247362 46.083458
17 6.492896 25.602679
18 1.841758 25.053824
19 -8.526080 24.289062
20 3.740077 29.029126
21 6.315965 32.243590
22 12.276836 33.883227
23 6.917793 33.051813
24 15.427313 42.088235
25 27.098976 55.736944
26 0.751118 29.058333
27 -1.308933 36.024793
28 9.319720 38.703608
29 -6.555811 30.133333
30 25.910804 57.428894
31 32.602854 51.590444
2 1 7.165198 30.290865
2 -4.788774 26.194595
3 0.025189 28.443299
4 7.507625 33.155172
5 6.766249 23.292735
6 -1.282511 29.103203
7 2.069189 26.704735
8 24.228571 35.454810
9 6.639175 37.007874
10 6.659176 38.445455
11 36.290094 62.482014
12 -2.144796 26.017182
13 0.026637 22.653740
14 4.777311 26.404651
15 0.769556 24.400524
16 0.203804 29.846405
17 -1.108434 35.627820
18 -2.730074 31.022989
19 12.819849 38.548807
20 3.049303 33.492537
21 7.915598 28.701493
22 10.978655 32.619522
23 14.711957 35.622871
24 1.093211 30.911184
25 1.371822 30.538682
26 1.715719 29.851064
27 31.252492 59.044828
28 -9.168940 23.614173
3 1 -0.690678 35.070796
2 -3.257294 32.088462
3 -6.398015 28.093385
4 -2.333333 28.114286
5 -3.888532 28.861345
6 6.972187 46.834437
7 16.230420 44.491342
8 85.862155 97.485315
9 -7.023936 34.135593
10 -2.080931 35.546125
11 -0.844969 27.080357
12 22.556049 50.529297
13 -3.333333 26.852201
14 3.667347 33.248082
15 0.590722 36.420245
16 11.131406 30.976019
17 6.551225 25.390909
18 41.291892 64.746457
19 26.489201 44.734921
20 2.374086 28.238845
21 3.508230 30.382653
22 3.284979 33.024457
23 13.767105 36.159036
24 11.166479 39.157407
25 10.370370 44.251208
26 -7.690476 21.831169
27 -6.323409 25.738318
28 -6.454918 32.087156
29 -9.594845 29.128834
30 -13.737598 28.849057
31 -0.762332 30.641577
4 1 10.847758 35.018828
2 4.581633 31.492308
3 0.103239 21.008000
4 5.278119 28.138085
5 5.644535 28.078261
6 -6.324641 27.707182
7 -4.072767 23.301653
8 -6.421053 24.801802
9 0.383090 32.686957
10 38.412311 94.130641
11 20.499475 47.626168
12 36.048140 56.411765
13 4.370757 25.724928
14 6.862637 31.294118
15 0.112348 26.695652
16 2.969664 46.575092
17 9.867089 40.985258
18 36.028481 64.895175
19 47.911697 80.048780
20 6.482759 31.100575
21 4.371460 28.240409
22 37.812166 56.491971
23 22.952329 40.163462
24 23.461373 50.996219
25 33.681250 45.829333
26 21.372188 42.631579
27 -12.046358 27.902985
28 -5.185919 26.915709
29 -3.382805 35.463768
30 -10.514166 23.260465
5 1 -8.381497 23.833333
2 -7.252317 31.076596
3 4.230530 42.539945
4 -8.537940 35.557377
5 -9.772026 30.853933
6 -7.578029 30.901141
7 -14.367089 24.167630
8 39.609183 69.049153
9 11.840415 36.572549
10 9.017562 37.834821
11 22.773826 61.501425
12 -6.227222 23.460076
13 -6.364198 29.882979
14 -11.105485 30.681818
15 -2.029598 34.597865
16 4.196939 34.097884
17 1.093878 29.060274
18 -10.738606 30.571429
19 19.513333 55.668817
20 5.846473 39.297030
21 4.079114 30.686420
22 27.593853 56.271881
23 61.970899 88.501792
24 24.257415 48.242583
25 0.053867 34.650655
26 -11.027473 19.185714
27 -9.673514 28.415301
28 1.101344 33.385075
29 0.267635 25.632432
30 -0.161389 38.012780
31 -4.627593 34.295082
6 1 -11.861148 26.272727
2 26.075518 72.118687
3 23.010460 49.567857
4 -0.390167 25.123494
5 -3.104384 30.104089
6 0.926272 25.843575
7 27.973481 52.932862
8 -3.540155 34.458937
9 -2.321903 27.858696
10 28.022293 57.427549
11 2.135135 36.368116
12 -0.101784 25.011494
13 63.753689 77.495957
14 18.910603 48.978346
15 -4.268939 37.066667
16 -0.941048 27.618893
17 29.360287 59.349040
18 37.648026 63.436242
19 7.245632 25.152475
20 -7.135765 20.145833
21 -3.197769 33.905797
22 -5.814907 31.156250
23 7.666667 43.331565
24 51.176808 92.093985
25 41.513684 73.197347
26 27.317410 59.994253
27 44.783296 88.440546
28 44.976852 78.172414
29 11.073325 39.922460
30 43.510278 75.887218
7 1 58.280502 76.901146
2 14.966486 42.913223
3 17.257467 48.211155
4 -12.099591 26.457364
5 -8.844743 33.886076
6 -7.516046 36.117647
7 40.306378 86.342213
8 29.648847 62.889908
9 31.334365 71.164773
10 59.626478 110.093439
11 16.524678 44.407484
12 20.116989 47.355993
13 13.539241 42.950980
14 -8.483766 42.163462
15 -9.598385 23.768061
16 3.467413 32.411330
17 4.868154 38.806701
18 12.832132 51.722477
19 11.723644 46.004545
20 8.832908 38.854342
21 15.459579 45.089087
22 62.763403 102.343470
23 44.959821 69.958132
24 14.073171 34.338156
25 17.404082 42.024390
26 10.337398 31.212355
27 0.248756 34.088462
28 49.831776 86.632163
29 11.453988 36.544699
30 -1.347870 28.543478
31 -0.892354 27.344937
8 1 35.989259 56.319508
2 8.565884 33.083512
3 9.414880 33.488000
4 4.085963 29.500000
5 2.009027 27.671916
6 -2.051724 27.094463
7 8.192153 31.287785
8 55.481163 78.624638
9 43.313641 62.330914
10 4.804483 29.857558
11 6.603896 29.613426
12 7.590313 26.316103
13 29.825107 44.047757
14 13.804656 29.067769
15 1.643863 27.269129
16 -1.842265 27.611285
17 -7.209781 25.130000
18 -1.126932 28.290429
19 -6.434211 22.300000
20 -8.207317 24.676596
21 -9.823649 22.323810
22 29.976744 53.612903
23 -0.666328 26.029674
24 -13.894942 32.000000
25 -15.030000 30.555556
26 -13.246660 27.606936
27 -11.759916 29.491713
28 35.203074 75.326848
29 -0.692387 28.875706
30 -12.035639 37.154762
31 -9.907738 31.934959
9 1 -9.390449 34.632353
2 45.518430 102.811364
3 -3.319194 27.251701
4 -15.092850 25.413793
5 -15.540373 26.259259
6 -17.895010 27.282609
7 -20.349854 23.984615
8 -11.545455 22.047120
9 -11.701417 20.015075
10 -9.033438 29.628141
11 7.982475 49.561308
12 58.912418 100.024540
13 13.457819 38.092885
14 -14.703377 30.863636
15 -9.751964 23.060773
16 -3.620549 20.321918
17 -10.257829 17.824859
18 -12.139319 36.620968
19 2.814508 46.939103
20 -4.093878 40.828571
21 -4.934783 29.631868
22 -1.705357 26.658703
23 -4.345491 24.832168
24 -9.909378 16.851648
25 -5.546680 19.596154
26 -4.643145 20.578231
27 -7.593939 21.831967
28 -16.371852 22.186916
29 -8.478022 27.164319
30 -11.641988 25.601227
10 1 -18.959375 24.242424
2 -13.080164 19.128571
3 4.260606 33.699739
4 -4.868421 26.890977
5 -9.113703 31.014815
6 -5.759300 23.773279
7 39.017260 72.483304
8 -6.169792 21.547893
9 -5.874871 24.808765
10 10.574359 36.680672
11 18.922995 51.251037
12 -9.684993 30.144000
13 -2.464365 25.470000
14 -4.509165 21.857651
15 -3.469045 25.148649
16 -3.857585 19.110368
17 6.635996 30.467849
18 3.928355 25.672289
19 -1.076358 17.848249
20 -1.563457 18.818462
21 -1.755826 16.853107
22 0.003122 21.531073
23 4.535052 21.614256
24 0.208925 20.438830
25 7.619919 32.589286
26 0.735988 27.076596
27 -5.429360 30.230088
28 -2.207354 22.406832
29 -3.220481 21.645062
30 -4.075335 22.381757
31 0.911572 24.745042
11 1 11.268162 34.353191
2 -2.871492 16.882609
3 -3.916667 24.677419
4 3.461934 20.141079
5 -5.169615 19.446970
6 -4.185685 21.406130
7 13.168050 31.615101
8 0.319714 21.318052
9 -8.877980 15.695035
10 1.540965 28.296296
11 -4.524004 24.914062
12 10.111111 29.271914
13 -10.976362 22.168889
14 -8.560529 22.403141
15 -4.681263 17.946996
16 -7.066104 23.722581
17 20.591014 53.404545
18 0.636458 28.200000
19 -2.766839 19.267101
20 -3.144764 24.118033
21 0.212487 21.065104
22 9.184662 30.304950
23 3.813514 23.990881
24 5.837472 35.022099
25 -5.129274 23.016260
26 6.232487 26.987041
27 17.534289 38.413445
28 -3.097792 31.231214
29 -12.180303 20.621359
30 -11.900468 26.166667
12 1 -0.976507 32.912752
2 0.450902 31.554878
3 2.222798 24.459259
4 -0.222222 28.406433
5 51.666255 80.835714
6 21.119469 37.510888
7 5.057057 27.187075
8 36.911801 56.160000
9 42.575556 53.073826
10 44.508796 52.194401
11 10.902439 24.905594
12 5.339937 23.463203
13 0.163032 22.141210
14 46.397504 59.978022
15 15.870098 38.986784
16 7.370681 27.813853
17 55.871856 60.467949
18 11.079832 26.595027
19 9.006211 31.040084
20 13.820166 35.249049
21 12.456929 36.855392
22 23.899549 45.648746
23 32.226042 50.033973
24 -1.043883 21.169611
25 -1.899301 30.095000
26 7.174194 34.548694
27 -0.148803 29.046832
28 -3.259533 25.607692
29 18.763825 47.256356
30 10.057712 31.243802
31 6.212121 24.455959
= dropmissing (flights, [: dep_delay, : arr_delay])
327346×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64 Int64? ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
3 │ 2013 1 1 542 540 2.0 923
4 │ 2013 1 1 544 545 -1.0 1004
5 │ 2013 1 1 554 600 -6.0 812 ⋯
6 │ 2013 1 1 554 558 -4.0 740
7 │ 2013 1 1 555 600 -5.0 913
8 │ 2013 1 1 557 600 -3.0 709
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
327340 │ 2013 9 30 2235 2001 154.0 59 ⋯
327341 │ 2013 9 30 2237 2245 -8.0 2345
327342 │ 2013 9 30 2240 2245 -5.0 2334
327343 │ 2013 9 30 2240 2250 -10.0 2347
327344 │ 2013 9 30 2241 2246 -5.0 2345 ⋯
327345 │ 2013 9 30 2307 2255 12.0 2359
327346 │ 2013 9 30 2349 2359 -10.0 325
12 columns and 327331 rows omitted
327346×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64 Int64? ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
3 │ 2013 1 1 542 540 2.0 923
4 │ 2013 1 1 544 545 -1.0 1004
5 │ 2013 1 1 554 600 -6.0 812 ⋯
6 │ 2013 1 1 554 558 -4.0 740
7 │ 2013 1 1 555 600 -5.0 913
8 │ 2013 1 1 557 600 -3.0 709
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
327340 │ 2013 9 30 2235 2001 154.0 59 ⋯
327341 │ 2013 9 30 2237 2245 -8.0 2345
327342 │ 2013 9 30 2240 2245 -5.0 2334
327343 │ 2013 9 30 2240 2250 -10.0 2347
327344 │ 2013 9 30 2241 2246 -5.0 2345 ⋯
327345 │ 2013 9 30 2307 2255 12.0 2359
327346 │ 2013 9 30 2349 2359 -10.0 325
12 columns and 327331 rows omitted
@pipe not_cancelled |> groupby (_, [: year, : month, : day]) |> combine (: arr_delay => (x -> [(mean (x), mean (skipmissing (x[x .>= 0 ])))]) => [: avg_delay1, : avg_delay2]
365×5 DataFrame
Row │ year month day avg_delay1 avg_delay2
│ Int64 Int64 Int64 Float64 Float64
─────┼─────────────────────────────────────────────
1 │ 2013 1 1 12.651 31.5907
2 │ 2013 1 2 12.6929 30.9314
3 │ 2013 1 3 5.73333 26.2351
4 │ 2013 1 4 -1.93282 27.1226
5 │ 2013 1 5 -1.5258 20.9727
6 │ 2013 1 6 4.23643 22.9284
7 │ 2013 1 7 -4.94731 25.8467
8 │ 2013 1 8 -3.22758 19.5788
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮
359 │ 2013 12 25 -1.8993 29.0773
360 │ 2013 12 26 7.17419 33.0568
361 │ 2013 12 27 -0.148803 27.1054
362 │ 2013 12 28 -3.25953 24.4779
363 │ 2013 12 29 18.7638 46.5658
364 │ 2013 12 30 10.0577 29.4776
365 │ 2013 12 31 6.21212 23.1941
350 rows omitted
Spread: sd(x), IQR(x), mad(x).
# destinations with largest variation in distance %>% group_by (dest) %>% summarise (distance_sd = sd (distance)) %>% arrange (desc (distance_sd))
# A tibble: 104 × 2
dest distance_sd
<chr> <dbl>
1 EGE 10.5
2 SAN 10.4
3 SFO 10.2
4 HNL 10.0
5 SEA 9.98
6 LAS 9.91
7 PDX 9.87
8 PHX 9.86
9 LAX 9.66
10 IND 9.46
# … with 94 more rows
'dest' ]).agg(= ('distance' , np.std)'distance_sd' , ascending = False )
distance_sd
dest
EGE 10.549066
SAN 10.346588
SFO 10.216858
HNL 10.001783
SEA 9.979116
LAS 9.913856
PDX 9.880313
PHX 9.856062
LAX 9.657222
IND 9.455668
SAT 9.000096
CVG 8.992937
MEM 8.497715
HOU 8.476723
MCI 8.387283
AUS 8.318982
DFW 8.305072
CLE 8.282101
TYS 8.004084
IAH 8.001671
DEN 7.981494
STL 7.899533
BNA 7.814711
ORD 7.731902
PIT 7.731472
BUF 7.724076
DTW 7.581811
ROC 7.452263
SDF 7.367790
SLC 7.363589
GSO 7.352531
MSP 7.296561
SBN 7.229569
XNA 7.194400
ATL 7.155615
MSY 7.088342
CMH 7.071074
MDW 7.000700
DAY 6.988557
BWI 6.920632
MKE 6.918848
BOS 6.878423
CLT 6.824532
IAD 6.774477
RIC 6.497803
MSN 6.319128
DSM 6.275483
PWM 5.633014
DCA 5.588415
JAC 5.537749
RDU 5.378799
SYR 5.305292
STT 5.291656
GSP 5.248836
PBI 5.166350
CHS 5.141765
TPA 5.104954
MCO 5.079727
MHT 4.870863
TVC 4.705253
MIA 4.607839
RSW 4.589385
CAE 4.587971
FLL 4.492772
JAX 4.452836
OMA 4.415946
BQN 4.239051
ORF 4.043022
SAV 3.897944
SJU 3.869986
GRR 3.092497
AVL 3.000553
SRQ 2.929607
MYR 2.880434
PHL 2.696727
BTV 2.538673
BHM 0.058026
SMF 0.000000
SJC 0.000000
BDL 0.000000
BGR 0.000000
SNA 0.000000
TUL 0.000000
ALB 0.000000
ANC 0.000000
EYW 0.000000
PVD 0.000000
CAK 0.000000
HDN 0.000000
CRW 0.000000
ILM 0.000000
LGB 0.000000
ACK 0.000000
CHO 0.000000
MTJ 0.000000
PSP 0.000000
MVY 0.000000
OAK 0.000000
OKC 0.000000
BZN 0.000000
BUR 0.000000
PSE 0.000000
ABQ 0.000000
LEX NaN
LGA NaN
@pipe flights |> groupby (_, : dest) |> combine (_, : distance => std => : distance_sd) |> sort (_, : distance_sd, rev = true )
105×2 DataFrame
Row │ dest distance_sd
│ String Float64
─────┼─────────────────────
1 │ LEX NaN
2 │ LGA NaN
3 │ EGE 10.5491
4 │ SAN 10.3466
5 │ SFO 10.2169
6 │ HNL 10.0018
7 │ SEA 9.97912
8 │ LAS 9.91386
⋮ │ ⋮ ⋮
99 │ ACK 0.0
100 │ BGR 0.0
101 │ ABQ 0.0
102 │ ILM 0.0
103 │ MVY 0.0
104 │ CHO 0.0
105 │ ANC 0.0
90 rows omitted
Rank: min(x), quantile(x, 0.25), max(x).
# Earliest and latest flights on each day? %>% group_by (year, month, day) %>% summarise (first = min (dep_time),last = max (dep_time)
# A tibble: 365 × 5
# Groups: year, month [12]
year month day first last
<int> <int> <int> <int> <int>
1 2013 1 1 517 2356
2 2013 1 2 42 2354
3 2013 1 3 32 2349
4 2013 1 4 25 2358
5 2013 1 5 14 2357
6 2013 1 6 16 2355
7 2013 1 7 49 2359
8 2013 1 8 454 2351
9 2013 1 9 2 2252
10 2013 1 10 3 2320
# … with 355 more rows
'year' , 'month' , 'day' ]).agg(= ('dep_time' , np.min ),= ('dep_time' , np.max )
first last
year month day
2013 1 1 517.0 2356.0
2 42.0 2354.0
3 32.0 2349.0
4 25.0 2358.0
5 14.0 2357.0
6 16.0 2355.0
7 49.0 2359.0
8 454.0 2351.0
9 2.0 2252.0
10 3.0 2320.0
11 11.0 2304.0
12 30.0 2359.0
13 1.0 2359.0
14 453.0 2353.0
15 453.0 2356.0
16 2.0 2358.0
17 453.0 2352.0
18 455.0 2359.0
19 456.0 2359.0
20 525.0 2356.0
21 455.0 2352.0
22 5.0 2358.0
23 158.0 2358.0
24 37.0 2350.0
25 15.0 2359.0
26 107.0 2352.0
27 523.0 2355.0
28 10.0 2356.0
29 448.0 2354.0
30 3.0 2354.0
31 1.0 2354.0
2 1 456.0 2355.0
2 3.0 2359.0
3 31.0 2352.0
4 453.0 2351.0
5 450.0 2355.0
6 6.0 2349.0
7 27.0 2400.0
8 458.0 1728.0
9 901.0 2358.0
10 455.0 2359.0
11 1.0 2400.0
12 17.0 2358.0
13 4.0 2353.0
14 7.0 2358.0
15 3.0 2358.0
16 4.0 2357.0
17 25.0 2356.0
18 7.0 2347.0
19 3.0 2355.0
20 10.0 2353.0
21 20.0 2356.0
22 9.0 2359.0
23 18.0 2355.0
24 1.0 2353.0
25 19.0 2357.0
26 6.0 2356.0
27 25.0 2348.0
28 457.0 2359.0
3 1 4.0 2357.0
2 43.0 2356.0
3 509.0 2353.0
4 11.0 2353.0
5 505.0 2351.0
6 4.0 2356.0
7 7.0 2351.0
8 1.0 2359.0
9 53.0 2345.0
10 6.0 2354.0
11 14.0 2355.0
12 2.0 2359.0
13 103.0 2355.0
14 9.0 2355.0
15 11.0 2400.0
16 37.0 2356.0
17 17.0 2321.0
18 1.0 2357.0
19 1.0 2357.0
20 31.0 2358.0
21 4.0 2352.0
22 37.0 2400.0
23 18.0 2349.0
24 2.0 2357.0
25 13.0 2400.0
26 18.0 2355.0
27 10.0 2359.0
28 4.0 2355.0
29 453.0 2357.0
30 6.0 2355.0
31 51.0 2358.0
4 1 454.0 2358.0
2 9.0 2400.0
3 2.0 2355.0
4 14.0 2400.0
5 1.0 2354.0
6 453.0 2359.0
7 30.0 2358.0
8 454.0 2355.0
9 449.0 2356.0
10 1.0 2357.0
11 25.0 2353.0
12 2.0 2357.0
13 59.0 2355.0
14 16.0 2357.0
15 2.0 2358.0
16 454.0 2359.0
17 8.0 2357.0
18 2.0 2358.0
19 11.0 2359.0
20 7.0 2400.0
21 8.0 2357.0
22 2.0 2352.0
23 4.0 2352.0
24 30.0 2358.0
25 5.0 2356.0
26 22.0 2358.0
27 453.0 2351.0
28 452.0 2352.0
29 2.0 2346.0
30 455.0 2351.0
5 1 9.0 2356.0
2 3.0 2352.0
3 32.0 2359.0
4 456.0 2359.0
5 446.0 2355.0
6 450.0 2359.0
7 2.0 2356.0
8 2.0 2358.0
9 9.0 2356.0
10 3.0 2325.0
11 2.0 2355.0
12 3.0 2359.0
13 16.0 2349.0
14 455.0 2357.0
15 48.0 2358.0
16 8.0 2358.0
17 11.0 2357.0
18 7.0 2356.0
19 2.0 2346.0
20 21.0 2357.0
21 110.0 2400.0
22 1.0 2356.0
23 4.0 2354.0
24 10.0 2358.0
25 1.0 2355.0
26 4.0 2358.0
27 455.0 2358.0
28 22.0 2356.0
29 457.0 2352.0
30 453.0 2358.0
31 33.0 2355.0
6 1 2.0 2359.0
2 14.0 2357.0
3 3.0 2353.0
4 452.0 2355.0
5 23.0 2359.0
6 454.0 2359.0
7 16.0 2359.0
8 2.0 2358.0
9 453.0 2356.0
10 7.0 2352.0
11 455.0 2358.0
12 5.0 2355.0
13 3.0 2355.0
14 24.0 2358.0
15 456.0 2356.0
16 14.0 2355.0
17 2.0 2400.0
18 3.0 2358.0
19 7.0 2357.0
20 1.0 2356.0
21 9.0 2354.0
22 3.0 2359.0
23 7.0 2354.0
24 1.0 2359.0
25 1.0 2357.0
26 13.0 2353.0
27 10.0 2359.0
28 2.0 2359.0
29 11.0 2342.0
30 12.0 2359.0
7 1 1.0 2359.0
2 12.0 2349.0
3 28.0 2359.0
4 11.0 2357.0
5 38.0 2358.0
6 32.0 2333.0
7 4.0 2400.0
8 2.0 2353.0
9 17.0 2359.0
10 17.0 2357.0
11 5.0 2357.0
12 5.0 2358.0
13 19.0 2400.0
14 6.0 2358.0
15 9.0 2357.0
16 19.0 2356.0
17 2.0 2400.0
18 9.0 2356.0
19 24.0 2354.0
20 6.0 2324.0
21 11.0 2356.0
22 1.0 2359.0
23 4.0 2355.0
24 6.0 2357.0
25 6.0 2357.0
26 9.0 2355.0
27 1.0 2358.0
28 1.0 2400.0
29 5.0 2359.0
30 3.0 2329.0
31 10.0 2352.0
8 1 12.0 2358.0
2 6.0 2357.0
3 2.0 2357.0
4 3.0 2321.0
5 8.0 2337.0
6 24.0 2358.0
7 453.0 2358.0
8 10.0 2359.0
9 4.0 2359.0
10 13.0 2400.0
11 4.0 2352.0
12 12.0 2358.0
13 208.0 2359.0
14 7.0 2338.0
15 1.0 2359.0
16 23.0 2358.0
17 7.0 2354.0
18 13.0 2359.0
19 1.0 2358.0
20 54.0 2400.0
21 10.0 2353.0
22 9.0 2350.0
23 9.0 2328.0
24 24.0 2359.0
25 3.0 2351.0
26 13.0 2258.0
27 8.0 2350.0
28 10.0 2358.0
29 21.0 2357.0
30 450.0 2359.0
31 455.0 2359.0
9 1 9.0 2352.0
2 8.0 2400.0
3 457.0 2357.0
4 446.0 2258.0
5 450.0 2352.0
6 8.0 2341.0
7 452.0 2246.0
8 509.0 2358.0
9 451.0 2354.0
10 453.0 2347.0
11 11.0 2351.0
12 2.0 2400.0
13 3.0 2352.0
14 453.0 2349.0
15 509.0 2351.0
16 453.0 2346.0
17 450.0 2352.0
18 450.0 2349.0
19 10.0 2353.0
20 9.0 2349.0
21 8.0 2306.0
22 518.0 2350.0
23 455.0 2342.0
24 455.0 2348.0
25 451.0 2358.0
26 451.0 2349.0
27 453.0 2346.0
28 451.0 2351.0
29 521.0 2356.0
30 453.0 2349.0
10 1 447.0 2349.0
2 449.0 2341.0
3 453.0 2355.0
4 7.0 2343.0
5 453.0 2354.0
6 519.0 2346.0
7 6.0 2356.0
8 141.0 2349.0
9 452.0 2346.0
10 457.0 2358.0
11 8.0 2359.0
12 457.0 2354.0
13 15.0 2352.0
14 451.0 2347.0
15 456.0 2355.0
16 454.0 2357.0
17 453.0 2357.0
18 9.0 2317.0
19 454.0 2356.0
20 517.0 2349.0
21 453.0 2356.0
22 454.0 2343.0
23 454.0 2355.0
24 453.0 2347.0
25 13.0 2353.0
26 451.0 2356.0
27 16.0 2352.0
28 453.0 2357.0
29 456.0 2353.0
30 455.0 2400.0
31 458.0 2357.0
11 1 5.0 2353.0
2 453.0 2358.0
3 519.0 2358.0
4 11.0 2357.0
5 4.0 2359.0
6 457.0 2355.0
7 457.0 2358.0
8 457.0 2357.0
9 52.0 2355.0
10 147.0 2354.0
11 453.0 2355.0
12 455.0 2356.0
13 1.0 2355.0
14 453.0 2359.0
15 3.0 2354.0
16 455.0 2359.0
17 3.0 2359.0
18 11.0 2355.0
19 59.0 2356.0
20 455.0 2355.0
21 6.0 2351.0
22 6.0 2351.0
23 504.0 2356.0
24 22.0 2358.0
25 5.0 2355.0
26 458.0 2357.0
27 28.0 2400.0
28 514.0 2356.0
29 518.0 2353.0
30 11.0 2354.0
12 1 13.0 2354.0
2 12.0 2358.0
3 457.0 2358.0
4 457.0 2355.0
5 16.0 2400.0
6 6.0 2357.0
7 3.0 2358.0
8 16.0 2354.0
9 11.0 2400.0
10 7.0 2348.0
11 459.0 2359.0
12 2.0 2356.0
13 15.0 2400.0
14 3.0 2359.0
15 5.0 2359.0
16 1.0 2332.0
17 4.0 2358.0
18 500.0 2358.0
19 17.0 2400.0
20 1.0 2358.0
21 2.0 2357.0
22 7.0 2358.0
23 11.0 2354.0
24 9.0 2358.0
25 456.0 2357.0
26 1.0 2355.0
27 2.0 2351.0
28 7.0 2358.0
29 3.0 2400.0
30 1.0 2356.0
31 13.0 2356.0
@pipe not_cancelled |> groupby (_, [: year, : month, : day]) |> combine (_, : dep_time => (x -> [extrema (x)]) => [: first, : last])
365×5 DataFrame
Row │ year month day first last
│ Int64 Int64 Int64 Int64 Int64
─────┼───────────────────────────────────
1 │ 2013 1 1 517 2356
2 │ 2013 1 2 42 2354
3 │ 2013 1 3 32 2349
4 │ 2013 1 4 25 2358
5 │ 2013 1 5 14 2357
6 │ 2013 1 6 16 2355
7 │ 2013 1 7 49 2359
8 │ 2013 1 8 454 2351
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮
359 │ 2013 12 25 456 2357
360 │ 2013 12 26 1 2355
361 │ 2013 12 27 2 2351
362 │ 2013 12 28 7 2358
363 │ 2013 12 29 3 2400
364 │ 2013 12 30 1 2356
365 │ 2013 12 31 13 2356
350 rows omitted
Position: first(x), nth(x, 2), last(x). Note unless the variable is sorted, first is different from min and last is different from max.
%>% group_by (year, month, day) %>% summarise (first_dep = first (dep_time), last_dep = last (dep_time)
# A tibble: 365 × 5
# Groups: year, month [12]
year month day first_dep last_dep
<int> <int> <int> <int> <int>
1 2013 1 1 517 2356
2 2013 1 2 42 2354
3 2013 1 3 32 2349
4 2013 1 4 25 2358
5 2013 1 5 14 2357
6 2013 1 6 16 2355
7 2013 1 7 49 2359
8 2013 1 8 454 2351
9 2013 1 9 2 2252
10 2013 1 10 3 2320
# … with 355 more rows
'year' , 'month' , 'day' ]).agg(= ('dep_time' , lambda x: x.iloc[0 ]),= ('dep_time' , lambda x: x.iloc[- 1 ]),
first_dep last_dep
year month day
2013 1 1 517.0 2356.0
2 42.0 2354.0
3 32.0 2349.0
4 25.0 2358.0
5 14.0 2357.0
6 16.0 2355.0
7 49.0 2359.0
8 454.0 2351.0
9 2.0 2252.0
10 3.0 2320.0
11 11.0 2304.0
12 30.0 2359.0
13 1.0 2359.0
14 453.0 2353.0
15 453.0 2356.0
16 2.0 2358.0
17 453.0 2352.0
18 455.0 2359.0
19 456.0 2359.0
20 525.0 2356.0
21 455.0 2352.0
22 5.0 2358.0
23 158.0 2358.0
24 37.0 2350.0
25 15.0 2359.0
26 107.0 2352.0
27 523.0 2355.0
28 10.0 2356.0
29 448.0 2354.0
30 3.0 2354.0
31 1.0 2354.0
2 1 456.0 2355.0
2 3.0 2359.0
3 31.0 2352.0
4 453.0 2351.0
5 450.0 2355.0
6 6.0 2349.0
7 27.0 2400.0
8 458.0 1728.0
9 901.0 2358.0
10 455.0 2359.0
11 1.0 2400.0
12 17.0 2358.0
13 4.0 2353.0
14 7.0 2358.0
15 3.0 2358.0
16 4.0 2357.0
17 25.0 2356.0
18 7.0 2347.0
19 3.0 2355.0
20 10.0 2353.0
21 20.0 2356.0
22 9.0 2359.0
23 18.0 2355.0
24 1.0 2353.0
25 19.0 2357.0
26 6.0 2356.0
27 25.0 2348.0
28 457.0 2359.0
3 1 4.0 2357.0
2 43.0 2356.0
3 509.0 2353.0
4 11.0 2353.0
5 505.0 2351.0
6 4.0 2356.0
7 7.0 2351.0
8 1.0 2359.0
9 53.0 2345.0
10 6.0 2354.0
11 14.0 2355.0
12 2.0 2359.0
13 103.0 2355.0
14 9.0 2355.0
15 11.0 2400.0
16 37.0 2356.0
17 17.0 2321.0
18 1.0 2357.0
19 1.0 2357.0
20 31.0 2358.0
21 4.0 2352.0
22 37.0 2400.0
23 18.0 2349.0
24 2.0 2357.0
25 13.0 2400.0
26 18.0 2355.0
27 10.0 2359.0
28 4.0 2355.0
29 453.0 2357.0
30 6.0 2355.0
31 51.0 2358.0
4 1 454.0 2358.0
2 9.0 2400.0
3 2.0 2355.0
4 14.0 2400.0
5 1.0 2354.0
6 453.0 2359.0
7 30.0 2358.0
8 454.0 2355.0
9 449.0 2356.0
10 1.0 2357.0
11 25.0 2353.0
12 2.0 2357.0
13 59.0 2355.0
14 16.0 2357.0
15 2.0 2358.0
16 454.0 2359.0
17 8.0 2357.0
18 2.0 2358.0
19 11.0 2359.0
20 7.0 2400.0
21 8.0 2357.0
22 2.0 2352.0
23 4.0 2352.0
24 30.0 2358.0
25 5.0 2356.0
26 22.0 2358.0
27 453.0 2351.0
28 452.0 2352.0
29 2.0 2346.0
30 455.0 2351.0
5 1 9.0 2356.0
2 3.0 2352.0
3 32.0 2359.0
4 456.0 2359.0
5 446.0 2355.0
6 450.0 2359.0
7 2.0 2356.0
8 2.0 2358.0
9 9.0 2356.0
10 3.0 2325.0
11 2.0 2355.0
12 3.0 2359.0
13 16.0 2349.0
14 455.0 2357.0
15 48.0 2358.0
16 8.0 2358.0
17 11.0 2357.0
18 7.0 2356.0
19 2.0 2346.0
20 21.0 2357.0
21 110.0 2400.0
22 1.0 2356.0
23 4.0 2354.0
24 10.0 2358.0
25 1.0 2355.0
26 4.0 2358.0
27 455.0 2358.0
28 22.0 2356.0
29 457.0 2352.0
30 453.0 2358.0
31 33.0 2355.0
6 1 2.0 2359.0
2 14.0 2357.0
3 3.0 2353.0
4 452.0 2355.0
5 23.0 2359.0
6 454.0 2359.0
7 16.0 2359.0
8 2.0 2358.0
9 453.0 2356.0
10 7.0 2352.0
11 455.0 2358.0
12 5.0 2355.0
13 3.0 2355.0
14 24.0 2358.0
15 456.0 2356.0
16 14.0 2355.0
17 2.0 2400.0
18 3.0 2358.0
19 7.0 2357.0
20 1.0 2356.0
21 9.0 2354.0
22 3.0 2359.0
23 7.0 2354.0
24 1.0 2359.0
25 1.0 2357.0
26 13.0 2353.0
27 10.0 2359.0
28 2.0 2359.0
29 11.0 2342.0
30 12.0 2359.0
7 1 1.0 2359.0
2 12.0 2349.0
3 28.0 2359.0
4 11.0 2357.0
5 38.0 2358.0
6 32.0 2333.0
7 4.0 2400.0
8 2.0 2353.0
9 17.0 2359.0
10 17.0 2357.0
11 5.0 2357.0
12 5.0 2358.0
13 19.0 2400.0
14 6.0 2358.0
15 9.0 2357.0
16 19.0 2356.0
17 2.0 2400.0
18 9.0 2356.0
19 24.0 2354.0
20 6.0 2324.0
21 11.0 2356.0
22 1.0 2359.0
23 4.0 2355.0
24 6.0 2357.0
25 6.0 2357.0
26 9.0 2355.0
27 1.0 2358.0
28 1.0 2400.0
29 5.0 2359.0
30 3.0 2329.0
31 10.0 2352.0
8 1 12.0 2358.0
2 6.0 2357.0
3 2.0 2357.0
4 3.0 2321.0
5 8.0 2337.0
6 24.0 2358.0
7 453.0 2358.0
8 10.0 2359.0
9 4.0 2359.0
10 13.0 2400.0
11 4.0 2352.0
12 12.0 2358.0
13 208.0 2359.0
14 7.0 2338.0
15 1.0 2359.0
16 23.0 2358.0
17 7.0 2354.0
18 13.0 2359.0
19 1.0 2358.0
20 54.0 2400.0
21 10.0 2353.0
22 9.0 2350.0
23 9.0 2328.0
24 24.0 2359.0
25 3.0 2351.0
26 13.0 2258.0
27 8.0 2350.0
28 10.0 2358.0
29 21.0 2357.0
30 450.0 2359.0
31 455.0 2359.0
9 1 9.0 2352.0
2 8.0 2400.0
3 457.0 2357.0
4 446.0 2258.0
5 450.0 2352.0
6 8.0 2341.0
7 452.0 2246.0
8 509.0 2358.0
9 451.0 2354.0
10 453.0 2347.0
11 11.0 2351.0
12 2.0 2400.0
13 3.0 2352.0
14 453.0 2349.0
15 509.0 2351.0
16 453.0 2346.0
17 450.0 2352.0
18 450.0 2349.0
19 10.0 2353.0
20 9.0 2349.0
21 8.0 2306.0
22 518.0 2350.0
23 455.0 2342.0
24 455.0 2348.0
25 451.0 2358.0
26 451.0 2349.0
27 453.0 2346.0
28 451.0 2351.0
29 521.0 2356.0
30 453.0 2349.0
10 1 447.0 2349.0
2 449.0 2341.0
3 453.0 2355.0
4 7.0 2343.0
5 453.0 2354.0
6 519.0 2346.0
7 6.0 2356.0
8 141.0 2349.0
9 452.0 2346.0
10 457.0 2358.0
11 8.0 2359.0
12 457.0 2354.0
13 15.0 2352.0
14 451.0 2347.0
15 456.0 2355.0
16 454.0 2357.0
17 453.0 2357.0
18 9.0 2317.0
19 454.0 2356.0
20 517.0 2349.0
21 453.0 2356.0
22 454.0 2343.0
23 454.0 2355.0
24 453.0 2347.0
25 13.0 2353.0
26 451.0 2356.0
27 16.0 2352.0
28 453.0 2357.0
29 456.0 2353.0
30 455.0 2400.0
31 458.0 2357.0
11 1 5.0 2353.0
2 453.0 2358.0
3 519.0 2358.0
4 11.0 2357.0
5 4.0 2359.0
6 457.0 2355.0
7 457.0 2358.0
8 457.0 2357.0
9 52.0 2355.0
10 147.0 2354.0
11 453.0 2355.0
12 455.0 2356.0
13 1.0 2355.0
14 453.0 2359.0
15 3.0 2354.0
16 455.0 2359.0
17 3.0 2359.0
18 11.0 2355.0
19 59.0 2356.0
20 455.0 2355.0
21 6.0 2351.0
22 6.0 2351.0
23 504.0 2356.0
24 22.0 2358.0
25 5.0 2355.0
26 458.0 2357.0
27 28.0 2400.0
28 514.0 2356.0
29 518.0 2353.0
30 11.0 2354.0
12 1 13.0 2354.0
2 12.0 2358.0
3 457.0 2358.0
4 457.0 2355.0
5 16.0 2400.0
6 6.0 2357.0
7 3.0 2358.0
8 16.0 2354.0
9 11.0 2400.0
10 7.0 2348.0
11 459.0 2359.0
12 2.0 2356.0
13 15.0 2400.0
14 3.0 2359.0
15 5.0 2359.0
16 1.0 2332.0
17 4.0 2358.0
18 500.0 2358.0
19 17.0 2400.0
20 1.0 2358.0
21 2.0 2357.0
22 7.0 2358.0
23 11.0 2354.0
24 9.0 2358.0
25 456.0 2357.0
26 1.0 2355.0
27 2.0 2351.0
28 7.0 2358.0
29 3.0 2400.0
30 1.0 2356.0
31 13.0 2356.0
@pipe not_cancelled |> groupby (_, [: year, : month, : day]) |> combine (: dep_time => first => : first_dep,: dep_time => last => : last_dep
365×5 DataFrame
Row │ year month day first_dep last_dep
│ Int64 Int64 Int64 Int64 Int64
─────┼──────────────────────────────────────────
1 │ 2013 1 1 517 2356
2 │ 2013 1 2 42 2354
3 │ 2013 1 3 32 2349
4 │ 2013 1 4 25 2358
5 │ 2013 1 5 14 2357
6 │ 2013 1 6 16 2355
7 │ 2013 1 7 49 2359
8 │ 2013 1 8 454 2351
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮
359 │ 2013 12 25 456 2357
360 │ 2013 12 26 1 2355
361 │ 2013 12 27 2 2351
362 │ 2013 12 28 7 2358
363 │ 2013 12 29 3 2400
364 │ 2013 12 30 1 2356
365 │ 2013 12 31 13 2356
350 rows omitted
Count: n(x), sum(!is.na(x)), n_distinct(x).
# Which destinations have the most carriers? %>% group_by (dest) %>% summarise (carriers = n_distinct (carrier)) %>% arrange (desc (carriers))
# A tibble: 104 × 2
dest carriers
<chr> <int>
1 ATL 7
2 BOS 7
3 CLT 7
4 ORD 7
5 TPA 7
6 AUS 6
7 DCA 6
8 DTW 6
9 IAD 6
10 MSP 6
# … with 94 more rows
Similarly
# which destination has most flights from NYC? %>% count (dest) %>% arrange (desc (n))
# A tibble: 104 × 2
dest n
<chr> <int>
1 ATL 16837
2 ORD 16566
3 LAX 16026
4 BOS 15022
5 MCO 13967
6 CLT 13674
7 SFO 13173
8 FLL 11897
9 MIA 11593
10 DCA 9111
# … with 94 more rows
'dest' ).agg(= ('carrier' , lambda x: x.nunique(dropna = True ))'carriers' , ascending = False )
carriers
dest
ORD 7
CLT 7
ATL 7
BOS 7
TPA 7
DTW 6
PIT 6
STL 6
DCA 6
AUS 6
MSY 6
MSP 6
IAD 6
SFO 5
RDU 5
CLE 5
PHX 5
SEA 5
DEN 5
PHL 5
PBI 5
LAS 5
LAX 5
BNA 5
IND 5
SAN 4
JAX 4
FLL 4
RSW 4
MCO 4
MKE 4
DFW 4
CVG 4
SRQ 4
CHS 4
SJU 4
BUF 4
BWI 4
ORF 3
MIA 3
MEM 3
SYR 3
OMA 3
STT 3
BTV 3
MCI 3
PDX 3
CMH 3
PWM 3
SDF 3
ROC 3
SAT 3
MSN 2
SJC 2
MVY 2
RIC 2
TVC 2
TYS 2
SLC 2
XNA 2
MHT 2
HOU 2
AVL 2
BDL 2
BQN 2
CAE 2
DAY 2
DSM 2
GRR 2
GSO 2
GSP 2
HNL 2
EGE 2
IAH 2
JAC 2
CAK 1
ALB 1
ANC 1
TUL 1
MTJ 1
ACK 1
BGR 1
BHM 1
MYR 1
SNA 1
SMF 1
BUR 1
BZN 1
OAK 1
CHO 1
HDN 1
CRW 1
SBN 1
SAV 1
OKC 1
LGB 1
MDW 1
EYW 1
LEX 1
ILM 1
PVD 1
PSP 1
PSE 1
ABQ 1
@pipe not_cancelled |> groupby (_, : dest) |> combine (_, : carrier => length ∘ unique => : carriers) |> sort (_, : carriers, rev = true )
104×2 DataFrame
Row │ dest carriers
│ String Int64
─────┼──────────────────
1 │ ATL 7
2 │ ORD 7
3 │ TPA 7
4 │ BOS 7
5 │ CLT 7
6 │ IAD 6
7 │ MSP 6
8 │ DTW 6
⋮ │ ⋮ ⋮
98 │ BGR 1
99 │ ABQ 1
100 │ ILM 1
101 │ SBN 1
102 │ LEX 1
103 │ CHO 1
104 │ ANC 1
89 rows omitted
Example: which aircraft flew most (in distance) in 2013?
%>% count (tailnum, wt = distance) %>% arrange (desc (n))
# A tibble: 4,037 × 2
tailnum n
<chr> <dbl>
1 N328AA 929090
2 N338AA 921172
3 N335AA 902271
4 N327AA 900482
5 N323AA 839468
6 N319AA 837924
7 N336AA 833136
8 N329AA 825826
9 N324AA 786159
10 N339AA 783648
# … with 4,027 more rows
'tailnum' ).agg(= ('distance' , sum )'total_distance' , ascending = False )
total_distance
tailnum
N328AA 929090
N338AA 921172
N335AA 902271
N327AA 900482
N323AA 839468
... ...
N762SK 419
N824AS 296
N881AS 292
N746SK 229
N505SW 185
[4037 rows x 1 columns]
@pipe not_cancelled |> groupby (_, : tailnum) |> combine (_, : distance => sum ∘ skipmissing => : total_distance) |> sort (_, : total_distance, rev = true )
4037×2 DataFrame
Row │ tailnum total_distance
│ String? Float64
──────┼─────────────────────────
1 │ N328AA 929090.0
2 │ N338AA 921172.0
3 │ N335AA 902271.0
4 │ N327AA 900482.0
5 │ N323AA 839468.0
6 │ N319AA 837924.0
7 │ N336AA 833136.0
8 │ N329AA 825826.0
⋮ │ ⋮ ⋮
4031 │ N772SK 419.0
4032 │ N776SK 419.0
4033 │ N785SK 419.0
4034 │ N824AS 296.0
4035 │ N881AS 292.0
4036 │ N746SK 229.0
4037 │ N505SW 185.0
4022 rows omitted
Example: How many flights left before 5am? (these usually indicate delayed flights from the previous day)
%>% group_by (year, month, day) %>% summarise (n_early = sum (dep_time < 500 )) %>% arrange (desc (n_early))
# A tibble: 365 × 4
# Groups: year, month [12]
year month day n_early
<int> <int> <int> <int>
1 2013 6 28 32
2 2013 4 10 30
3 2013 7 28 30
4 2013 3 18 29
5 2013 7 7 29
6 2013 7 10 27
7 2013 6 27 25
8 2013 6 13 24
9 2013 3 8 22
10 2013 7 22 22
# … with 355 more rows
'year' , 'month' , 'day' ]).agg(= ('dep_time' , lambda x: sum (x < 500 ))'n_early' , ascending = False )
n_early
year month day
2013 6 28 32
7 28 30
4 10 30
7 7 29
3 18 29
7 10 27
6 27 25
13 24
7 22 22
3 8 22
8 8 22
6 24 21
9 12 21
4 19 20
5 23 15
12 17 15
5 8 14
7 1 14
2 11 14
8 9 13
1 13
3 12 13
7 8 12
6 25 12
4 22 12
6 18 12
7 23 11
5 22 11
6 2 10
4 18 10
7 19 10
6 26 10
7 12 9
5 19 9
6 30 9
3 7 9
7 2 9
1 13 9
31 9
12 23 9
5 9
8 22 9
9 2 9
7 17 8
4 17 8
5 10 8
4 23 8
8 28 8
5 11 8
7 21 8
10 7 7
12 8 7
14 7
7 16 7
18 7
2 19 7
4 12 7
12 27 7
6 10 7
29 7
3 17 6
6 23 6
5 20 6
11 17 6
3 24 6
7 3 6
4 24 6
1 25 6
12 16 6
2 27 6
7 11 6
12 30 6
2 15 6
12 21 5
12 5
6 7 5
8 11 5
12 10 5
6 17 5
8 16 5
5 2 5
12 9 5
7 13 5
9 5
6 5
3 10 5
2 23 5
5 16 4
12 22 4
4 29 4
8 5 4
6 20 4
21 4
22 4
11 21 4
7 31 4
9 20 4
11 4
8 26 4
23 4
21 4
7 20 4
25 4
8 14 4
7 27 4
10 11 4
12 31 4
3 6 4
1 3 4
4 5 4
3 19 4
1 4
2 26 4
24 4
3 26 4
4 14 4
11 4
8 6 3
12 13 3
3 16 3
1 11 3
8 4 3
3 21 3
23 3
6 14 3
8 12 3
3 25 3
28 3
8 3 3
6 16 3
8 10 3
3 15 3
7 15 3
3 11 3
7 26 3
2 16 3
17 3
18 3
20 3
7 24 3
2 22 3
7 14 3
12 7 3
1 3
1 16 3
7 30 3
4 3
1 2 3
8 17 3
1 10 3
2 14 3
5 26 3
1 4 3
11 1 3
4 3 3
5 3 3
12 26 3
19 3
1 24 3
5 24 3
25 3
8 29 3
1 5 3
12 29 3
4 25 3
1 9 3
4 13 3
7 29 2
9 19 2
11 30 2
4 2
2 7 2
8 20 2
12 2 2
1 22 2
9 21 2
10 25 2
4 2
18 2
8 2
11 5 2
9 6 2
1 23 2
11 24 2
1 30 2
28 2
2 13 2
11 19 2
8 15 2
2 2 2
4 15 2
8 13 2
11 18 2
9 2
8 27 2
1 26 2
2 6 2
9 1 2
11 15 2
13 2
8 19 2
2 2
11 22 2
8 25 2
2 21 2
3 30 2
5 31 2
12 15 2
5 28 2
3 31 2
4 2 2
5 18 2
17 2
15 2
1 7 2
5 13 2
12 2
1 6 2
5 9 2
4 7 2
5 7 2
12 24 2
5 1 2
12 28 2
4 26 2
21 2
20 2
6 1 2
4 4 2
10 13 2
2 28 2
3 4 2
12 6 2
3 13 2
6 3 2
3 14 2
20 2
22 2
6 19 2
3 2 2
7 5 2
6 12 2
5 2
3 27 2
10 19 1
14 1
15 1
31 1
12 1
30 1
16 1
17 1
29 1
21 1
28 1
27 1
12 4 1
10 26 1
12 25 1
10 23 1
22 1
24 1
1 17 1
11 2 1
16 1
12 11 1
11 20 1
1 12 1
14 1
8 1
12 20 1
1 15 1
18 1
11 25 1
6 1
12 3 1
11 26 1
14 1
27 1
12 1
11 1
10 1
8 1
7 1
4 16 1
1 19 1
8 24 1
6 8 1
9 1
11 1
15 1
3 9 1
2 25 1
12 1
10 1
8 1
8 7 1
2 5 1
4 1
3 1
10 10 1
8 18 1
3 29 1
6 6 1
4 1
5 5 1
4 27 1
28 1
9 1
30 1
8 1
5 4 1
6 1
30 1
4 6 1
5 14 1
21 1
4 1 1
5 27 1
29 1
1 29 1
2 1 1
9 14 1
28 1
26 1
25 1
24 1
23 1
30 1
1 21 1
9 18 1
8 30 1
9 17 1
16 1
10 1 1
2 1
9 27 1
13 1
10 1
10 3 1
9 9 1
10 5 1
9 7 1
5 1
4 1
10 9 1
9 3 1
8 31 1
10 20 0
6 0
1 20 0
9 29 0
1 27 0
11 3 0
12 18 0
9 22 0
15 0
3 5 0
3 0
2 9 0
11 29 0
28 0
9 8 0
11 23 0
1 1 0
@pipe not_cancelled |> groupby (_, [: year, : month, : day]) |> combine (_, : dep_time => (x -> sum (skipmissing (x .< 500 ))) => : n_early) |> sort (_, : n_early, rev = true )
365×4 DataFrame
Row │ year month day n_early
│ Int64 Int64 Int64 Int64
─────┼──────────────────────────────
1 │ 2013 6 28 32
2 │ 2013 4 10 30
3 │ 2013 7 28 30
4 │ 2013 3 18 29
5 │ 2013 7 7 29
6 │ 2013 7 10 27
7 │ 2013 6 27 25
8 │ 2013 6 13 24
⋮ │ ⋮ ⋮ ⋮ ⋮
359 │ 2013 10 6 0
360 │ 2013 10 20 0
361 │ 2013 11 3 0
362 │ 2013 11 23 0
363 │ 2013 11 28 0
364 │ 2013 11 29 0
365 │ 2013 12 18 0
350 rows omitted
Example: What proportion of flights are delayed by more than an hour?
%>% group_by (year, month, day) %>% summarise (hour_perc = mean (arr_delay > 60 )) %>% arrange (desc (hour_perc))
# A tibble: 365 × 4
# Groups: year, month [12]
year month day hour_perc
<int> <int> <int> <dbl>
1 2013 3 8 0.525
2 2013 6 13 0.402
3 2013 7 1 0.401
4 2013 7 22 0.366
5 2013 5 23 0.361
6 2013 8 8 0.361
7 2013 9 12 0.350
8 2013 12 17 0.339
9 2013 7 10 0.332
10 2013 6 24 0.323
# … with 355 more rows
'year' , 'month' , 'day' ]).agg(= ('arr_delay' , lambda x: np.mean(x > 60 ))'hour_perc' , ascending = False )
hour_perc
year month day
2013 3 8 0.525063
6 13 0.401816
7 1 0.401368
22 0.365967
5 23 0.361111
8 8 0.360603
9 12 0.350327
12 17 0.338922
7 10 0.332151
6 24 0.322618
7 28 0.311916
23 0.311384
8 9 0.309345
6 28 0.298611
30 0.293833
25 0.292632
9 2 0.286564
7 7 0.285877
10 7 0.285868
6 27 0.279910
12 5 0.276885
4 19 0.272936
8 28 0.270033
5 8 0.269877
12 10 0.269283
7 9 0.263158
4 22 0.259338
12 9 0.257778
14 0.254902
6 18 0.245614
4 10 0.243902
12 8 0.242236
3 18 0.241081
2 11 0.240566
4 18 0.239451
12 0.237418
7 8 0.233753
8 1 0.233083
6 10 0.227176
2 27 0.224806
6 17 0.224156
2 0.218027
26 0.217622
1 31 0.216409
8 22 0.214588
1 30 0.203518
12 23 0.200000
4 25 0.197917
5 19 0.195556
6 7 0.193370
1 16 0.191090
5 22 0.188804
3 19 0.182505
5 24 0.180085
3 12 0.179800
5 11 0.176387
8 13 0.174893
1 25 0.174061
6 3 0.170502
12 22 0.167043
7 12 0.164802
4 11 0.163694
23 0.161430
10 11 0.157219
4 24 0.156652
7 3 0.153450
12 29 0.148618
4 26 0.148262
1 13 0.147460
7 18 0.147271
6 14 0.145530
11 17 0.145161
3 7 0.144154
7 2 0.137297
25 0.133673
13 0.131646
2 8 0.125275
3 25 0.122334
7 21 0.121816
9 11 0.121577
7 11 0.119099
12 6 0.118363
1 24 0.114537
12 15 0.112745
10 10 0.109744
6 29 0.108723
11 27 0.108495
7 19 0.107472
3 6 0.107459
2 23 0.105978
19 0.102481
11 1 0.100427
3 24 0.100112
9 13 0.099794
12 20 0.099792
7 24 0.098577
4 1 0.098019
6 23 0.097588
5 10 0.097107
7 20 0.096939
12 21 0.096130
1 22 0.094915
11 7 0.092324
1 28 0.092182
3 23 0.090789
7 29 0.088957
5 20 0.088174
9 0.088083
1 2 0.085129
9 19 0.084974
2 10 0.083645
22 0.081110
4 17 0.080169
2 4 0.077342
12 26 0.076344
6 11 0.075884
2 9 0.075601
7 17 0.075051
5 3 0.074766
7 26 0.074187
8 14 0.073887
11 12 0.072690
12 30 0.072403
1 1 0.072202
10 25 0.071138
11 24 0.071106
2 1 0.070485
5 30 0.070480
8 2 0.070480
1 23 0.069820
4 2 0.068367
3 16 0.068331
12 19 0.067288
8 3 0.066835
10 3 0.066667
11 22 0.066599
1 21 0.066519
3 14 0.066327
4 16 0.066089
9 0.065762
8 7 0.065392
5 16 0.064286
3 15 0.063918
7 16 0.063136
10 17 0.062690
3 22 0.061728
4 14 0.061538
12 11 0.060445
1 20 0.058899
2 21 0.058761
8 10 0.058531
4 20 0.058355
3 1 0.058263
1 3 0.056667
5 21 0.055907
1 27 0.055831
17 0.055738
2 20 0.055734
3 21 0.055556
12 16 0.055497
4 4 0.055215
2 25 0.054025
3 10 0.053215
6 8 0.053109
12 27 0.053070
8 11 0.053030
2 26 0.052397
8 4 0.052231
7 14 0.051948
5 15 0.051797
4 0.051491
12 18 0.051471
2 0.051102
5 28 0.050672
8 12 0.050454
3 31 0.050448
4 21 0.050109
5 0.050051
7 27 0.049751
5 25 0.049724
3 17 0.048998
6 21 0.048682
19 0.048304
2 17 0.048193
9 20 0.047959
1 6 0.047045
3 20 0.047022
4 13 0.046997
2 5 0.046750
15 0.046512
3 2 0.046419
10 18 0.046418
5 17 0.045918
11 26 0.045685
5 31 0.045643
4 15 0.044534
2 14 0.044118
3 0.044081
4 29 0.044012
3 9 0.043883
8 16 0.043478
12 31 0.043478
8 15 0.043260
11 10 0.042649
2 7 0.042162
8 5 0.042126
2 16 0.042120
12 7 0.042042
7 30 0.041582
8 29 0.041152
3 4 0.040752
12 12 0.040667
3 0.040415
2 6 0.040359
24 0.040276
3 11 0.040041
1 4 0.039648
11 28 0.039432
2 18 0.039320
6 16 0.039301
9 3 0.039236
12 4 0.039153
1 0.038815
8 18 0.038631
6 0.038540
3 13 0.038422
10 31 0.038210
12 28 0.038130
5 6 0.037988
10 15 0.037775
12 25 0.037762
9 21 0.037681
5 2 0.037075
10 26 0.036873
6 12 0.036726
3 3 0.036384
7 31 0.036217
6 22 0.036025
5 13 0.036008
1 26 0.035768
8 30 0.035639
6 4 0.035565
11 18 0.035417
6 15 0.035354
6 0.035306
1 18 0.035165
5 0.034868
8 23 0.034588
10 27 0.034216
2 12 0.033937
3 28 0.033811
9 22 0.033482
7 6 0.033376
1 7 0.033333
5 29 0.033195
7 5 0.033007
2 2 0.032496
11 23 0.032432
9 10 0.032393
1 29 0.032221
3 5 0.032154
10 4 0.031377
6 5 0.031315
8 31 0.031250
2 13 0.031077
6 9 0.030973
8 17 0.030888
11 11 0.030644
5 14 0.030591
10 22 0.030177
13 0.030067
4 28 0.029703
11 8 0.029622
9 23 0.029382
29 0.027473
1 15 0.027242
14 0.027086
12 13 0.026999
10 12 0.026746
5 5 0.026432
7 15 0.026236
2 28 0.026233
11 19 0.025907
5 12 0.025872
9 18 0.025800
10 23 0.025773
11 3 0.025556
10 28 0.025536
8 20 0.025407
10 24 0.025355
9 1 0.025281
10 20 0.025164
1 11 0.025082
5 27 0.024865
10 5 0.024781
4 3 0.024291
10 8 0.023958
11 4 0.023663
4 6 0.023468
8 24 0.023346
25 0.023333
4 7 0.023153
8 27 0.022965
11 6 0.022822
5 18 0.022788
8 26 0.022610
12 24 0.022606
11 16 0.022504
9 15 0.022447
11 25 0.022436
10 6 0.021882
5 1 0.021830
10 9 0.021717
1 8 0.021300
9 27 0.021212
4 27 0.021192
1 19 0.020864
3 26 0.020704
11 2 0.020679
10 30 0.020640
4 8 0.020640
3 29 0.020619
9 14 0.020558
11 20 0.020534
3 27 0.020534
7 4 0.020464
11 14 0.020346
1 9 0.020157
11 30 0.019906
3 30 0.019582
8 19 0.019231
9 26 0.019153
11 21 0.019134
4 30 0.018888
9 8 0.018847
10 29 0.018809
14 0.018330
1 10 0.018299
11 13 0.017472
9 16 0.017294
10 21 0.017224
9 25 0.016598
10 19 0.016153
11 5 0.015609
9 30 0.015213
6 20 0.015198
1 0.014686
9 5 0.014493
10 16 0.014448
8 21 0.014271
11 15 0.014257
9 9 0.014170
4 0.013874
5 7 0.013713
11 29 0.013636
5 26 0.010989
9 28 0.010370
1 12 0.010279
9 7 0.010204
17 0.009395
10 1 0.009375
2 0.009250
9 6 0.008316
24 0.007376
11 9 0.007013
@pipe not_cancelled |> groupby (_, [: year, : month, : day]) |> combine (_, : arr_delay => (x -> mean (skipmissing (x .> 60 ))) => : hour_perc) |> sort (_, : hour_perc, rev = true )
365×4 DataFrame
Row │ year month day hour_perc
│ Int64 Int64 Int64 Float64
─────┼─────────────────────────────────
1 │ 2013 3 8 0.525063
2 │ 2013 6 13 0.401816
3 │ 2013 7 1 0.401368
4 │ 2013 7 22 0.365967
5 │ 2013 5 23 0.361111
6 │ 2013 8 8 0.360603
7 │ 2013 9 12 0.350327
8 │ 2013 12 17 0.338922
⋮ │ ⋮ ⋮ ⋮ ⋮
359 │ 2013 9 7 0.0102041
360 │ 2013 9 17 0.00939457
361 │ 2013 10 1 0.009375
362 │ 2013 10 2 0.00924974
363 │ 2013 9 6 0.00831601
364 │ 2013 9 24 0.00737619
365 │ 2013 11 9 0.00701262
350 rows omitted
Grouped mutates (and filters)
Recall the flights_sml tibble created earlier:
# A tibble: 336,776 × 7
year month day dep_delay arr_delay distance air_time
<int> <int> <int> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 2 11 1400 227
2 2013 1 1 4 20 1416 227
3 2013 1 1 2 33 1089 160
4 2013 1 1 -1 -18 1576 183
5 2013 1 1 -6 -25 762 116
6 2013 1 1 -4 12 719 150
7 2013 1 1 -5 19 1065 158
8 2013 1 1 -3 -14 229 53
9 2013 1 1 -3 -8 944 140
10 2013 1 1 -2 8 733 138
# … with 336,766 more rows
year month day dep_delay arr_delay distance air_time gain \
0 2013 1 1 2.0 11.0 1400 227.0 9.0
1 2013 1 1 4.0 20.0 1416 227.0 16.0
2 2013 1 1 2.0 33.0 1089 160.0 31.0
3 2013 1 1 -1.0 -18.0 1576 183.0 -17.0
4 2013 1 1 -6.0 -25.0 762 116.0 -19.0
... ... ... ... ... ... ... ... ...
336771 2013 9 30 NaN NaN 213 NaN NaN
336772 2013 9 30 NaN NaN 198 NaN NaN
336773 2013 9 30 NaN NaN 764 NaN NaN
336774 2013 9 30 NaN NaN 419 NaN NaN
336775 2013 9 30 NaN NaN 431 NaN NaN
speed
0 370.044053
1 374.273128
2 408.375000
3 516.721311
4 394.137931
... ...
336771 NaN
336772 NaN
336773 NaN
336774 NaN
336775 NaN
[336776 rows x 9 columns]
336776×8 DataFrame
Row │ year month day dep_delay arr_delay distance air_time gain ⋯
│ Int64 Int64 Int64 Float64? Float64? Float64 Float64? Floa ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 2.0 11.0 1400.0 227.0 ⋯
2 │ 2013 1 1 4.0 20.0 1416.0 227.0
3 │ 2013 1 1 2.0 33.0 1089.0 160.0
4 │ 2013 1 1 -1.0 -18.0 1576.0 183.0
5 │ 2013 1 1 -6.0 -25.0 762.0 116.0 ⋯
6 │ 2013 1 1 -4.0 12.0 719.0 150.0
7 │ 2013 1 1 -5.0 19.0 1065.0 158.0
8 │ 2013 1 1 -3.0 -14.0 229.0 53.0
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 30 -10.0 -25.0 1617.0 196.0 ⋯
336771 │ 2013 9 30 missing missing 764.0 missing miss
336772 │ 2013 9 30 missing missing 213.0 missing miss
336773 │ 2013 9 30 missing missing 198.0 missing miss
336774 │ 2013 9 30 missing missing 764.0 missing miss ⋯
336775 │ 2013 9 30 missing missing 419.0 missing miss
336776 │ 2013 9 30 missing missing 431.0 missing miss
1 column and 336761 rows omitted
Find the worst members of each group:
%>% group_by (year, month, day) %>% filter (rank (desc (arr_delay)) < 10 )
# A tibble: 3,306 × 7
# Groups: year, month, day [365]
year month day dep_delay arr_delay distance air_time
<int> <int> <int> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 853 851 184 41
2 2013 1 1 290 338 1134 213
3 2013 1 1 260 263 266 46
4 2013 1 1 157 174 213 60
5 2013 1 1 216 222 708 121
6 2013 1 1 255 250 589 115
7 2013 1 1 285 246 1085 146
8 2013 1 1 192 191 199 44
9 2013 1 1 379 456 1092 222
10 2013 1 2 224 207 550 94
# … with 3,296 more rows
'year' , 'month' , 'day' ]'arr_delay' ].nlargest(= 10
year month day
2013 1 1 151 851.0
834 456.0
649 338.0
673 263.0
801 250.0
...
12 31 111017 155.0
110962 142.0
110653 140.0
111217 136.0
111144 122.0
Name: arr_delay, Length: 3650, dtype: float64
@pipe flights_sml |> dropmissing (_, : arr_delay) |> groupby (_, [: year, : month, : day]) |> combine (: arr_delay => (x -> x[x .>= partialsort (x, 10 , rev = true )])
3697×4 DataFrame
Row │ year month day arr_delay_function
│ Int64 Int64 Int64 Float64
──────┼─────────────────────────────────────────
1 │ 2013 1 1 851.0
2 │ 2013 1 1 338.0
3 │ 2013 1 1 263.0
4 │ 2013 1 1 166.0
5 │ 2013 1 1 174.0
6 │ 2013 1 1 222.0
7 │ 2013 1 1 250.0
8 │ 2013 1 1 246.0
⋮ │ ⋮ ⋮ ⋮ ⋮
3691 │ 2013 12 31 155.0
3692 │ 2013 12 31 231.0
3693 │ 2013 12 31 122.0
3694 │ 2013 12 31 222.0
3695 │ 2013 12 31 188.0
3696 │ 2013 12 31 136.0
3697 │ 2013 12 31 195.0
3682 rows omitted
Find all groups bigger than a threshold:
<- flights %>% group_by (dest) %>% filter (n () > 365 ) %>% print (width = Inf )
# A tibble: 332,577 × 19
# Groups: dest [77]
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
arr_delay carrier flight tailnum origin dest air_time distance hour minute
<dbl> <chr> <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 11 UA 1545 N14228 EWR IAH 227 1400 5 15
2 20 UA 1714 N24211 LGA IAH 227 1416 5 29
3 33 AA 1141 N619AA JFK MIA 160 1089 5 40
4 -18 B6 725 N804JB JFK BQN 183 1576 5 45
5 -25 DL 461 N668DN LGA ATL 116 762 6 0
6 12 UA 1696 N39463 EWR ORD 150 719 5 58
7 19 B6 507 N516JB EWR FLL 158 1065 6 0
8 -14 EV 5708 N829AS LGA IAD 53 229 6 0
9 -8 B6 79 N593JB JFK MCO 140 944 6 0
10 8 AA 301 N3ALAA LGA ORD 138 733 6 0
time_hour
<dttm>
1 2013-01-01 05:00:00
2 2013-01-01 05:00:00
3 2013-01-01 05:00:00
4 2013-01-01 05:00:00
5 2013-01-01 06:00:00
6 2013-01-01 05:00:00
7 2013-01-01 06:00:00
8 2013-01-01 06:00:00
9 2013-01-01 06:00:00
10 2013-01-01 06:00:00
# … with 332,567 more rows
= flights.groupby('dest' ).filter (lambda x: len (x) > 365 )
year month day dep_time sched_dep_time dep_delay arr_time \
0 2013 1 1 517.0 515 2.0 830.0
1 2013 1 1 533.0 529 4.0 850.0
2 2013 1 1 542.0 540 2.0 923.0
3 2013 1 1 544.0 545 -1.0 1004.0
4 2013 1 1 554.0 600 -6.0 812.0
... ... ... ... ... ... ... ...
336771 2013 9 30 NaN 1455 NaN NaN
336772 2013 9 30 NaN 2200 NaN NaN
336773 2013 9 30 NaN 1210 NaN NaN
336774 2013 9 30 NaN 1159 NaN NaN
336775 2013 9 30 NaN 840 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest \
0 819 11.0 UA 1545 N14228 EWR IAH
1 830 20.0 UA 1714 N24211 LGA IAH
2 850 33.0 AA 1141 N619AA JFK MIA
3 1022 -18.0 B6 725 N804JB JFK BQN
4 837 -25.0 DL 461 N668DN LGA ATL
... ... ... ... ... ... ... ...
336771 1634 NaN 9E 3393 NaN JFK DCA
336772 2312 NaN 9E 3525 NaN LGA SYR
336773 1330 NaN MQ 3461 N535MQ LGA BNA
336774 1344 NaN MQ 3572 N511MQ LGA CLE
336775 1020 NaN MQ 3531 N839MQ LGA RDU
air_time distance hour minute time_hour
0 227.0 1400 5 15 2013-01-01 10:00:00+00:00
1 227.0 1416 5 29 2013-01-01 10:00:00+00:00
2 160.0 1089 5 40 2013-01-01 10:00:00+00:00
3 183.0 1576 5 45 2013-01-01 10:00:00+00:00
4 116.0 762 6 0 2013-01-01 11:00:00+00:00
... ... ... ... ... ...
336771 NaN 213 14 55 2013-09-30 18:00:00+00:00
336772 NaN 198 22 0 2013-10-01 02:00:00+00:00
336773 NaN 764 12 10 2013-09-30 16:00:00+00:00
336774 NaN 419 11 59 2013-09-30 15:00:00+00:00
336775 NaN 431 8 40 2013-09-30 12:00:00+00:00
[332577 rows x 19 columns]
= @pipe flights |> groupby (_, : dest) |> combine (_) do sdfnrow (sdf) > 365 ? sdf : DataFrame ()end
332577×19 DataFrame
Row │ dest year month day dep_time sched_dep_time dep_delay ar ⋯
│ String Int64 Int64 Int64 Int64? Int64 Float64? In ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ IAH 2013 1 1 517 515 2.0 ⋯
2 │ IAH 2013 1 1 533 529 4.0
3 │ IAH 2013 1 1 623 627 -4.0
4 │ IAH 2013 1 1 728 732 -4.0
5 │ IAH 2013 1 1 739 739 0.0 ⋯
6 │ IAH 2013 1 1 908 908 0.0
7 │ IAH 2013 1 1 1028 1026 2.0
8 │ IAH 2013 1 1 1044 1045 -1.0
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
332571 │ BGR 2013 9 27 2319 2205 74.0 ⋯
332572 │ BGR 2013 9 28 1125 1130 -5.0
332573 │ BGR 2013 9 28 1804 1810 -6.0
332574 │ BGR 2013 9 29 1056 1100 -4.0
332575 │ BGR 2013 9 29 2203 2205 -2.0 ⋯
332576 │ BGR 2013 9 30 1057 1100 -3.0
332577 │ BGR 2013 9 30 2203 2205 -2.0
12 columns and 332562 rows omitted
332577×19 DataFrame
Row │ dest year month day dep_time sched_dep_time dep_delay ar ⋯
│ String Int64 Int64 Int64 Int64? Int64 Float64? In ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ IAH 2013 1 1 517 515 2.0 ⋯
2 │ IAH 2013 1 1 533 529 4.0
3 │ IAH 2013 1 1 623 627 -4.0
4 │ IAH 2013 1 1 728 732 -4.0
5 │ IAH 2013 1 1 739 739 0.0 ⋯
6 │ IAH 2013 1 1 908 908 0.0
7 │ IAH 2013 1 1 1028 1026 2.0
8 │ IAH 2013 1 1 1044 1045 -1.0
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
332571 │ BGR 2013 9 27 2319 2205 74.0 ⋯
332572 │ BGR 2013 9 28 1125 1130 -5.0
332573 │ BGR 2013 9 28 1804 1810 -6.0
332574 │ BGR 2013 9 29 1056 1100 -4.0
332575 │ BGR 2013 9 29 2203 2205 -2.0 ⋯
332576 │ BGR 2013 9 30 1057 1100 -3.0
332577 │ BGR 2013 9 30 2203 2205 -2.0
12 columns and 332562 rows omitted
Standardise to compute per group metrics:
= popular_dests %>% filter (arr_delay > 0 ) %>% mutate (prop_delay = arr_delay / sum (arr_delay)) %>% select (year: day, dest, arr_delay, prop_delay) %>% print (width = Inf )
# A tibble: 131,106 × 6
# Groups: dest [77]
year month day dest arr_delay prop_delay
<int> <int> <int> <chr> <dbl> <dbl>
1 2013 1 1 IAH 11 0.000111
2 2013 1 1 IAH 20 0.000201
3 2013 1 1 MIA 33 0.000235
4 2013 1 1 ORD 12 0.0000424
5 2013 1 1 FLL 19 0.0000938
6 2013 1 1 ORD 8 0.0000283
7 2013 1 1 LAX 7 0.0000344
8 2013 1 1 DFW 31 0.000282
9 2013 1 1 ATL 12 0.0000400
10 2013 1 1 DTW 16 0.000116
# … with 131,096 more rows
'arr_delay' ] > 0 ].groupby('dest' apply (lambda x: x['arr_delay' ] / x['arr_delay' ].sum ()
dest
ALB 569 0.004175
784 0.004593
1536 0.007411
1757 0.008559
2425 0.004175
...
XNA 325031 0.006818
326901 0.001737
330832 0.000386
332101 0.007204
335551 0.000257
Name: arr_delay, Length: 131106, dtype: float64
@pipe popular_dests |> dropmissing (_, : arr_delay) |> subset (_, : arr_delay => x -> x .> 0 ) |> groupby (_, : dest) |> combine (_, : arr_delay => (x -> x ./ sum (x)) => : prop_delay)
131106×2 DataFrame
Row │ dest prop_delay
│ String Float64
────────┼─────────────────────
1 │ IAH 0.000110674
2 │ IAH 0.000201225
3 │ IAH 1.00613e-5
4 │ IAH 3.01838e-5
5 │ IAH 0.000261593
6 │ IAH 9.05515e-5
7 │ IAH 0.000110674
8 │ IAH 1.00613e-5
⋮ │ ⋮ ⋮
131100 │ BGR 0.000432277
131101 │ BGR 0.0054755
131102 │ BGR 0.00273775
131103 │ BGR 0.00345821
131104 │ BGR 0.00907781
131105 │ BGR 0.0018732
131106 │ BGR 0.00115274
131091 rows omitted
Combine tables
nycflights13 package has >1 tables:
We already know a lot about flights:
%>% print (width = Inf )
# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
arr_delay carrier flight tailnum origin dest air_time distance hour minute
<dbl> <chr> <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 11 UA 1545 N14228 EWR IAH 227 1400 5 15
2 20 UA 1714 N24211 LGA IAH 227 1416 5 29
3 33 AA 1141 N619AA JFK MIA 160 1089 5 40
4 -18 B6 725 N804JB JFK BQN 183 1576 5 45
5 -25 DL 461 N668DN LGA ATL 116 762 6 0
6 12 UA 1696 N39463 EWR ORD 150 719 5 58
7 19 B6 507 N516JB EWR FLL 158 1065 6 0
8 -14 EV 5708 N829AS LGA IAD 53 229 6 0
9 -8 B6 79 N593JB JFK MCO 140 944 6 0
10 8 AA 301 N3ALAA LGA ORD 138 733 6 0
time_hour
<dttm>
1 2013-01-01 05:00:00
2 2013-01-01 05:00:00
3 2013-01-01 05:00:00
4 2013-01-01 05:00:00
5 2013-01-01 06:00:00
6 2013-01-01 05:00:00
7 2013-01-01 06:00:00
8 2013-01-01 06:00:00
9 2013-01-01 06:00:00
10 2013-01-01 06:00:00
# … with 336,766 more rows
year month day dep_time sched_dep_time dep_delay arr_time \
0 2013 1 1 517.0 515 2.0 830.0
1 2013 1 1 533.0 529 4.0 850.0
2 2013 1 1 542.0 540 2.0 923.0
3 2013 1 1 544.0 545 -1.0 1004.0
4 2013 1 1 554.0 600 -6.0 812.0
... ... ... ... ... ... ... ...
336771 2013 9 30 NaN 1455 NaN NaN
336772 2013 9 30 NaN 2200 NaN NaN
336773 2013 9 30 NaN 1210 NaN NaN
336774 2013 9 30 NaN 1159 NaN NaN
336775 2013 9 30 NaN 840 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest \
0 819 11.0 UA 1545 N14228 EWR IAH
1 830 20.0 UA 1714 N24211 LGA IAH
2 850 33.0 AA 1141 N619AA JFK MIA
3 1022 -18.0 B6 725 N804JB JFK BQN
4 837 -25.0 DL 461 N668DN LGA ATL
... ... ... ... ... ... ... ...
336771 1634 NaN 9E 3393 NaN JFK DCA
336772 2312 NaN 9E 3525 NaN LGA SYR
336773 1330 NaN MQ 3461 N535MQ LGA BNA
336774 1344 NaN MQ 3572 N511MQ LGA CLE
336775 1020 NaN MQ 3531 N839MQ LGA RDU
air_time distance hour minute time_hour
0 227.0 1400 5 15 2013-01-01 10:00:00+00:00
1 227.0 1416 5 29 2013-01-01 10:00:00+00:00
2 160.0 1089 5 40 2013-01-01 10:00:00+00:00
3 183.0 1576 5 45 2013-01-01 10:00:00+00:00
4 116.0 762 6 0 2013-01-01 11:00:00+00:00
... ... ... ... ... ...
336771 NaN 213 14 55 2013-09-30 18:00:00+00:00
336772 NaN 198 22 0 2013-10-01 02:00:00+00:00
336773 NaN 764 12 10 2013-09-30 16:00:00+00:00
336774 NaN 419 11 59 2013-09-30 15:00:00+00:00
336775 NaN 431 8 40 2013-09-30 12:00:00+00:00
[336776 rows x 19 columns]
336776×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 517 515 2.0 830 ⋯
2 │ 2013 1 1 533 529 4.0 850
3 │ 2013 1 1 542 540 2.0 923
4 │ 2013 1 1 544 545 -1.0 1004
5 │ 2013 1 1 554 600 -6.0 812 ⋯
6 │ 2013 1 1 554 558 -4.0 740
7 │ 2013 1 1 555 600 -5.0 913
8 │ 2013 1 1 557 600 -3.0 709
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 30 2349 2359 -10.0 325 ⋯
336771 │ 2013 9 30 missing 1842 missing missing
336772 │ 2013 9 30 missing 1455 missing missing
336773 │ 2013 9 30 missing 2200 missing missing
336774 │ 2013 9 30 missing 1210 missing missing ⋯
336775 │ 2013 9 30 missing 1159 missing missing
336776 │ 2013 9 30 missing 840 missing missing
12 columns and 336761 rows omitted
# A tibble: 16 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
11 OO SkyWest Airlines Inc.
12 UA United Air Lines Inc.
13 US US Airways Inc.
14 VX Virgin America
15 WN Southwest Airlines Co.
16 YV Mesa Airlines Inc.
from nycflights13 import airlines
carrier name
0 9E Endeavor Air Inc.
1 AA American Airlines Inc.
2 AS Alaska Airlines Inc.
3 B6 JetBlue Airways
4 DL Delta Air Lines Inc.
5 EV ExpressJet Airlines Inc.
6 F9 Frontier Airlines Inc.
7 FL AirTran Airways Corporation
8 HA Hawaiian Airlines Inc.
9 MQ Envoy Air
10 OO SkyWest Airlines Inc.
11 UA United Air Lines Inc.
12 US US Airways Inc.
13 VX Virgin America
14 WN Southwest Airlines Co.
15 YV Mesa Airlines Inc.
= rcopy (R"airlines" )
16×2 DataFrame
Row │ carrier name
│ String String
─────┼──────────────────────────────────────
1 │ 9E Endeavor Air Inc.
2 │ AA American Airlines Inc.
3 │ AS Alaska Airlines Inc.
4 │ B6 JetBlue Airways
5 │ DL Delta Air Lines Inc.
6 │ EV ExpressJet Airlines Inc.
7 │ F9 Frontier Airlines Inc.
8 │ FL AirTran Airways Corporation
9 │ HA Hawaiian Airlines Inc.
10 │ MQ Envoy Air
11 │ OO SkyWest Airlines Inc.
12 │ UA United Air Lines Inc.
13 │ US US Airways Inc.
14 │ VX Virgin America
15 │ WN Southwest Airlines Co.
16 │ YV Mesa Airlines Inc.
# A tibble: 1,458 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/…
2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/…
3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/…
4 06N Randall Airport 41.4 -74.4 523 -5 A America/…
5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/…
6 0A9 Elizabethton Municipal Airport 36.4 -82.2 1593 -5 A America/…
7 0G6 Williams County Airport 41.5 -84.5 730 -5 A America/…
8 0G7 Finger Lakes Regional Airport 42.9 -76.8 492 -5 A America/…
9 0P2 Shoestring Aviation Airfield 39.8 -76.6 1000 -5 U America/…
10 0S9 Jefferson County Intl 48.1 -123. 108 -8 A America/…
# … with 1,448 more rows
from nycflights13 import airports
faa name lat lon alt tz dst \
0 04G Lansdowne Airport 41.130472 -80.619583 1044 -5 A
1 06A Moton Field Municipal Airport 32.460572 -85.680028 264 -6 A
2 06C Schaumburg Regional 41.989341 -88.101243 801 -6 A
3 06N Randall Airport 41.431912 -74.391561 523 -5 A
4 09J Jekyll Island Airport 31.074472 -81.427778 11 -5 A
... ... ... ... ... ... .. ..
1453 ZUN Black Rock 35.083228 -108.791778 6454 -7 A
1454 ZVE New Haven Rail Station 41.298669 -72.925992 7 -5 A
1455 ZWI Wilmington Amtrak Station 39.736667 -75.551667 0 -5 A
1456 ZWU Washington Union Station 38.897460 -77.006430 76 -5 A
1457 ZYP Penn Station 40.750500 -73.993500 35 -5 A
tzone
0 America/New_York
1 America/Chicago
2 America/Chicago
3 America/New_York
4 America/New_York
... ...
1453 America/Denver
1454 America/New_York
1455 America/New_York
1456 America/New_York
1457 America/New_York
[1458 rows x 8 columns]
= rcopy (R"airports" )
1458×8 DataFrame
Row │ faa name lat lon alt t ⋯
│ String String Float64 Float64 Float64 F ⋯
──────┼─────────────────────────────────────────────────────────────────────────
1 │ 04G Lansdowne Airport 41.1305 -80.6196 1044.0 ⋯
2 │ 06A Moton Field Municipal Airport 32.4606 -85.68 264.0
3 │ 06C Schaumburg Regional 41.9893 -88.1012 801.0
4 │ 06N Randall Airport 41.4319 -74.3916 523.0
5 │ 09J Jekyll Island Airport 31.0745 -81.4278 11.0 ⋯
6 │ 0A9 Elizabethton Municipal Airport 36.3712 -82.1734 1593.0
7 │ 0G6 Williams County Airport 41.4673 -84.5068 730.0
8 │ 0G7 Finger Lakes Regional Airport 42.8836 -76.7812 492.0
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
1452 │ ZTF Stamford Amtrak Station 41.0469 -73.5415 0.0 ⋯
1453 │ ZTY Boston Back Bay Station 42.3478 -71.075 20.0
1454 │ ZUN Black Rock 35.0832 -108.792 6454.0
1455 │ ZVE New Haven Rail Station 41.2987 -72.926 7.0
1456 │ ZWI Wilmington Amtrak Station 39.7367 -75.5517 0.0 ⋯
1457 │ ZWU Washington Union Station 38.8975 -77.0064 76.0
1458 │ ZYP Penn Station 40.7505 -73.9935 35.0
3 columns and 1443 rows omitted
# A tibble: 3,322 × 9
tailnum year type manuf…¹ model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi engi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi engi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
# … with 3,312 more rows, and abbreviated variable name ¹manufacturer
from nycflights13 import planes
tailnum year type manufacturer \
0 N10156 2004.0 Fixed wing multi engine EMBRAER
1 N102UW 1998.0 Fixed wing multi engine AIRBUS INDUSTRIE
2 N103US 1999.0 Fixed wing multi engine AIRBUS INDUSTRIE
3 N104UW 1999.0 Fixed wing multi engine AIRBUS INDUSTRIE
4 N10575 2002.0 Fixed wing multi engine EMBRAER
... ... ... ... ...
3317 N997AT 2002.0 Fixed wing multi engine BOEING
3318 N997DL 1992.0 Fixed wing multi engine MCDONNELL DOUGLAS AIRCRAFT CO
3319 N998AT 2002.0 Fixed wing multi engine BOEING
3320 N998DL 1992.0 Fixed wing multi engine MCDONNELL DOUGLAS CORPORATION
3321 N999DN 1992.0 Fixed wing multi engine MCDONNELL DOUGLAS CORPORATION
model engines seats speed engine
0 EMB-145XR 2 55 NaN Turbo-fan
1 A320-214 2 182 NaN Turbo-fan
2 A320-214 2 182 NaN Turbo-fan
3 A320-214 2 182 NaN Turbo-fan
4 EMB-145LR 2 55 NaN Turbo-fan
... ... ... ... ... ...
3317 717-200 2 100 NaN Turbo-fan
3318 MD-88 2 142 NaN Turbo-fan
3319 717-200 2 100 NaN Turbo-fan
3320 MD-88 2 142 NaN Turbo-jet
3321 MD-88 2 142 NaN Turbo-jet
[3322 rows x 9 columns]
= rcopy (R"planes" )
3322×9 DataFrame
Row │ tailnum year type manufacturer ⋯
│ String Int64? String String ⋯
──────┼─────────────────────────────────────────────────────────────────────────
1 │ N10156 2004 Fixed wing multi engine EMBRAER ⋯
2 │ N102UW 1998 Fixed wing multi engine AIRBUS INDUSTRIE
3 │ N103US 1999 Fixed wing multi engine AIRBUS INDUSTRIE
4 │ N104UW 1999 Fixed wing multi engine AIRBUS INDUSTRIE
5 │ N10575 2002 Fixed wing multi engine EMBRAER ⋯
6 │ N105UW 1999 Fixed wing multi engine AIRBUS INDUSTRIE
7 │ N107US 1999 Fixed wing multi engine AIRBUS INDUSTRIE
8 │ N108UW 1999 Fixed wing multi engine AIRBUS INDUSTRIE
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋱
3316 │ N996AT 2002 Fixed wing multi engine BOEING ⋯
3317 │ N996DL 1991 Fixed wing multi engine MCDONNELL DOUGLAS AIRCRAFT C
3318 │ N997AT 2002 Fixed wing multi engine BOEING
3319 │ N997DL 1992 Fixed wing multi engine MCDONNELL DOUGLAS AIRCRAFT C
3320 │ N998AT 2002 Fixed wing multi engine BOEING ⋯
3321 │ N998DL 1992 Fixed wing multi engine MCDONNELL DOUGLAS CORPORATIO
3322 │ N999DN 1992 Fixed wing multi engine MCDONNELL DOUGLAS CORPORATIO
6 columns and 3307 rows omitted
%>% print (width = Inf )
# A tibble: 26,115 × 15
origin year month day hour temp dewp humid wind_dir wind_speed
<chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4
2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06
3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5
4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7
5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7
6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5
7 EWR 2013 1 1 7 39.0 28.0 64.4 240 15.0
8 EWR 2013 1 1 8 39.9 28.0 62.2 250 10.4
9 EWR 2013 1 1 9 39.9 28.0 62.2 260 15.0
10 EWR 2013 1 1 10 41 28.0 59.6 260 13.8
wind_gust precip pressure visib time_hour
<dbl> <dbl> <dbl> <dbl> <dttm>
1 NA 0 1012 10 2013-01-01 01:00:00
2 NA 0 1012. 10 2013-01-01 02:00:00
3 NA 0 1012. 10 2013-01-01 03:00:00
4 NA 0 1012. 10 2013-01-01 04:00:00
5 NA 0 1012. 10 2013-01-01 05:00:00
6 NA 0 1012. 10 2013-01-01 06:00:00
7 NA 0 1012. 10 2013-01-01 07:00:00
8 NA 0 1012. 10 2013-01-01 08:00:00
9 NA 0 1013. 10 2013-01-01 09:00:00
10 NA 0 1012. 10 2013-01-01 10:00:00
# … with 26,105 more rows
from nycflights13 import weather
origin year month day hour temp dewp humid wind_dir \
0 EWR 2013 1 1 1 39.02 26.06 59.37 270.0
1 EWR 2013 1 1 2 39.02 26.96 61.63 250.0
2 EWR 2013 1 1 3 39.02 28.04 64.43 240.0
3 EWR 2013 1 1 4 39.92 28.04 62.21 250.0
4 EWR 2013 1 1 5 39.02 28.04 64.43 260.0
... ... ... ... ... ... ... ... ... ...
26110 LGA 2013 12 30 14 35.96 19.94 51.78 340.0
26111 LGA 2013 12 30 15 33.98 17.06 49.51 330.0
26112 LGA 2013 12 30 16 32.00 15.08 49.19 340.0
26113 LGA 2013 12 30 17 30.92 12.92 46.74 320.0
26114 LGA 2013 12 30 18 28.94 10.94 46.41 330.0
wind_speed wind_gust precip pressure visib time_hour
0 10.35702 NaN 0.0 1012.0 10.0 2013-01-01T06:00:00Z
1 8.05546 NaN 0.0 1012.3 10.0 2013-01-01T07:00:00Z
2 11.50780 NaN 0.0 1012.5 10.0 2013-01-01T08:00:00Z
3 12.65858 NaN 0.0 1012.2 10.0 2013-01-01T09:00:00Z
4 12.65858 NaN 0.0 1011.9 10.0 2013-01-01T10:00:00Z
... ... ... ... ... ... ...
26110 13.80936 21.86482 0.0 1017.1 10.0 2013-12-30T19:00:00Z
26111 17.26170 21.86482 0.0 1018.8 10.0 2013-12-30T20:00:00Z
26112 14.96014 23.01560 0.0 1019.5 10.0 2013-12-30T21:00:00Z
26113 17.26170 NaN 0.0 1019.9 10.0 2013-12-30T22:00:00Z
26114 18.41248 NaN 0.0 1020.9 10.0 2013-12-30T23:00:00Z
[26115 rows x 15 columns]
= rcopy (R"weather" )
26115×15 DataFrame
Row │ origin year month day hour temp dewp humid win ⋯
│ String Int64 Int64 Int64 Int64 Float64? Float64? Float64? Flo ⋯
───────┼────────────────────────────────────────────────────────────────────────
1 │ EWR 2013 1 1 1 39.02 26.06 59.37 ⋯
2 │ EWR 2013 1 1 2 39.02 26.96 61.63
3 │ EWR 2013 1 1 3 39.02 28.04 64.43
4 │ EWR 2013 1 1 4 39.92 28.04 62.21
5 │ EWR 2013 1 1 5 39.02 28.04 64.43 ⋯
6 │ EWR 2013 1 1 6 37.94 28.04 67.21
7 │ EWR 2013 1 1 7 39.02 28.04 64.43
8 │ EWR 2013 1 1 8 39.92 28.04 62.21
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
26109 │ LGA 2013 12 30 12 37.94 23.0 54.51 ⋯
26110 │ LGA 2013 12 30 13 37.04 21.92 53.97
26111 │ LGA 2013 12 30 14 35.96 19.94 51.78
26112 │ LGA 2013 12 30 15 33.98 17.06 49.51
26113 │ LGA 2013 12 30 16 32.0 15.08 49.19 ⋯
26114 │ LGA 2013 12 30 17 30.92 12.92 46.74
26115 │ LGA 2013 12 30 18 28.94 10.94 46.41
7 columns and 26100 rows omitted
Combine variables (columns)
Demo tables
<- tribble (~ key, ~ val_x,1 , "x1" ,2 , "x2" ,3 , "x3"
# A tibble: 3 × 2
key val_x
<dbl> <chr>
1 1 x1
2 2 x2
3 3 x3
<- tribble (~ key, ~ val_y,1 , "y1" ,2 , "y2" ,4 , "y3"
# A tibble: 3 × 2
key val_y
<dbl> <chr>
1 1 y1
2 2 y2
3 4 y3
= pd.DataFrame({'key' : [1 , 2 , 4 ],'val_x' : ['x1' , 'x2' , 'x3' ]
key val_x
0 1 x1
1 2 x2
2 4 x3
= pd.DataFrame({'key' : [1 , 2 , 3 ],'val_y' : ['y1' , 'y2' , 'y3' ]
key val_x
0 1 x1
1 2 x2
2 4 x3
= DataFrame (= 1 : 3 ,= ["x1" , "x2" , "x3" ]
3×2 DataFrame
Row │ key val_x
│ Int64 String
─────┼───────────────
1 │ 1 x1
2 │ 2 x2
3 │ 3 x3
= DataFrame (= [1 , 2 , 4 ],= ["y1" , "y2" , "y3" ]
3×2 DataFrame
Row │ key val_y
│ Int64 String
─────┼───────────────
1 │ 1 y1
2 │ 2 y2
3 │ 4 y3
Inner join
An inner join matches pairs of observations whenever their keys are equal:
inner_join (x, y, by = "key" )
# A tibble: 2 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
Same as
%>% inner_join (y, by = "key" )
'key' ), on = 'key' , how = 'inner' )
key val_x val_y
0 1 x1 y1
1 2 x2 y2
innerjoin (x, y, on = : key)
2×3 DataFrame
Row │ key val_x val_y
│ Int64 String String
─────┼───────────────────────
1 │ 1 x1 y1
2 │ 2 x2 y2
Outer join
left_join (x, y, by = "key" )
# A tibble: 3 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
'key' ), on = 'key' , how = 'left' )
key val_x val_y
0 1 x1 y1
1 2 x2 y2
2 4 x3 NaN
leftjoin (x, y, on = : key)
3×3 DataFrame
Row │ key val_x val_y
│ Int64 String String?
─────┼────────────────────────
1 │ 1 x1 y1
2 │ 2 x2 y2
3 │ 3 x3 missing
- A **right join** keeps all observations in `y`.
right_join (x, y, by = "key" )
# A tibble: 3 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 4 <NA> y3
'key' ), on = 'key' , how = 'right' )
key val_x val_y
0.0 1 x1 y1
1.0 2 x2 y2
NaN 3 NaN y3
rightjoin (x, y, on = : key)
3×3 DataFrame
Row │ key val_x val_y
│ Int64 String? String
─────┼────────────────────────
1 │ 1 x1 y1
2 │ 2 x2 y2
3 │ 4 missing y3
- A **full join** keeps all observations in `x` or `y`.
full_join (x, y, by = "key" )
# A tibble: 4 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
4 4 <NA> y3
'key' ), on = 'key' , how = 'outer' )
key val_x val_y
0.0 1 x1 y1
1.0 2 x2 y2
2.0 4 x3 NaN
NaN 3 NaN y3
outerjoin (x, y, on = : key)
4×3 DataFrame
Row │ key val_x val_y
│ Int64 String? String?
─────┼─────────────────────────
1 │ 1 x1 y1
2 │ 2 x2 y2
3 │ 3 x3 missing
4 │ 4 missing y3
Duplicate keys
<- tribble (~ key, ~ val_x,1 , "x1" ,2 , "x2" ,2 , "x3" ,1 , "x4"
# A tibble: 4 × 2
key val_x
<dbl> <chr>
1 1 x1
2 2 x2
3 2 x3
4 1 x4
<- tribble (~ key, ~ val_y,1 , "y1" ,2 , "y2"
# A tibble: 2 × 2
key val_y
<dbl> <chr>
1 1 y1
2 2 y2
left_join (x, y, by = "key" )
# A tibble: 4 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 2 x3 y2
4 1 x4 y1
= pd.DataFrame({'key' : [1 , 2 , 2 , 1 ],'val_x' : ["x1" , "x2" , "x3" , "x4" ]
key val_x
0 1 x1
1 2 x2
2 2 x3
3 1 x4
= pd.DataFrame({'key' : [1 , 2 ],'val_y' : ["y1" , "y2" ]'key' ), on = 'key' , how = 'left' )
key val_x val_y
0 1 x1 y1
1 2 x2 y2
2 2 x3 y2
3 1 x4 y1
= DataFrame (= [1 , 2 , 2 , 1 ],= ["x1" , "x2" , "x3" , "x4" ]
4×2 DataFrame
Row │ key val_x
│ Int64 String
─────┼───────────────
1 │ 1 x1
2 │ 2 x2
3 │ 2 x3
4 │ 1 x4
= DataFrame (= [1 , 2 ],= ["y1" , "y2" ]
2×2 DataFrame
Row │ key val_y
│ Int64 String
─────┼───────────────
1 │ 1 y1
2 │ 2 y2
leftjoin (x, y, on = : key)
4×3 DataFrame
Row │ key val_x val_y
│ Int64 String String?
─────┼────────────────────────
1 │ 1 x1 y1
2 │ 2 x2 y2
3 │ 2 x3 y2
4 │ 1 x4 y1
<- tribble (~ key, ~ val_x,1 , "x1" ,2 , "x2" ,2 , "x3" ,3 , "x4" <- tribble (~ key, ~ val_y,1 , "y1" ,2 , "y2" ,2 , "y3" ,3 , "y4" left_join (x, y, by = "key" )
# A tibble: 6 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 2 x2 y3
4 2 x3 y2
5 2 x3 y3
6 3 x4 y4
= pd.DataFrame({'key' : [1 , 2 , 2 , 3 ],'val_x' : ["x1" , "x2" , "x3" , "x4" ]
key val_x
0 1 x1
1 2 x2
2 2 x3
3 3 x4
= pd.DataFrame({'key' : [1 , 2 , 2 , 3 ],'val_y' : ["y1" , "y2" , "y3" , "y4" ]
key val_y
0 1 y1
1 2 y2
2 2 y3
3 3 y4
'key' ), on = 'key' , how = 'left' )
key val_x val_y
0 1 x1 y1
1 2 x2 y2
1 2 x2 y3
2 2 x3 y2
2 2 x3 y3
3 3 x4 y4
= DataFrame (= [1 , 2 , 2 , 3 ],= ["x1" , "x2" , "x3" , "x4" ]
4×2 DataFrame
Row │ key val_x
│ Int64 String
─────┼───────────────
1 │ 1 x1
2 │ 2 x2
3 │ 2 x3
4 │ 3 x4
= DataFrame (= [1 , 2 , 2 , 3 ],= ["y1" , "y2" , "y3" , "y4" ]
4×2 DataFrame
Row │ key val_y
│ Int64 String
─────┼───────────────
1 │ 1 y1
2 │ 2 y2
3 │ 2 y3
4 │ 3 y4
leftjoin (x, y, on = : key)
6×3 DataFrame
Row │ key val_x val_y
│ Int64 String String?
─────┼────────────────────────
1 │ 1 x1 y1
2 │ 2 x2 y2
3 │ 2 x3 y2
4 │ 2 x2 y3
5 │ 2 x3 y3
6 │ 3 x4 y4
Let’s create a narrower table from the flights data:
<- flights %>% select (year: day, hour, origin, dest, tailnum, carrier) %>% print (width = Inf )
# A tibble: 336,776 × 8
year month day hour origin dest tailnum carrier
<int> <int> <int> <dbl> <chr> <chr> <chr> <chr>
1 2013 1 1 5 EWR IAH N14228 UA
2 2013 1 1 5 LGA IAH N24211 UA
3 2013 1 1 5 JFK MIA N619AA AA
4 2013 1 1 5 JFK BQN N804JB B6
5 2013 1 1 6 LGA ATL N668DN DL
6 2013 1 1 5 EWR ORD N39463 UA
7 2013 1 1 6 EWR FLL N516JB B6
8 2013 1 1 6 LGA IAD N829AS EV
9 2013 1 1 6 JFK MCO N593JB B6
10 2013 1 1 6 LGA ORD N3ALAA AA
# … with 336,766 more rows
= flights[['year' , 'month' , 'day' , 'hour' , 'origin' , 'dest' , 'tailnum' , 'carrier' ]]
year month day hour origin dest tailnum carrier
0 2013 1 1 5 EWR IAH N14228 UA
1 2013 1 1 5 LGA IAH N24211 UA
2 2013 1 1 5 JFK MIA N619AA AA
3 2013 1 1 5 JFK BQN N804JB B6
4 2013 1 1 6 LGA ATL N668DN DL
... ... ... ... ... ... ... ... ...
336771 2013 9 30 14 JFK DCA NaN 9E
336772 2013 9 30 22 LGA SYR NaN 9E
336773 2013 9 30 12 LGA BNA N535MQ MQ
336774 2013 9 30 11 LGA CLE N511MQ MQ
336775 2013 9 30 8 LGA RDU N839MQ MQ
[336776 rows x 8 columns]
= select (Between (: year, : day), : hour, : origin, : dest, : tailnum, : carrier
336776×8 DataFrame
Row │ year month day hour origin dest tailnum carrier
│ Int64 Int64 Int64 Float64 String String String? String
────────┼────────────────────────────────────────────────────────────────
1 │ 2013 1 1 5.0 EWR IAH N14228 UA
2 │ 2013 1 1 5.0 LGA IAH N24211 UA
3 │ 2013 1 1 5.0 JFK MIA N619AA AA
4 │ 2013 1 1 5.0 JFK BQN N804JB B6
5 │ 2013 1 1 6.0 LGA ATL N668DN DL
6 │ 2013 1 1 5.0 EWR ORD N39463 UA
7 │ 2013 1 1 6.0 EWR FLL N516JB B6
8 │ 2013 1 1 6.0 LGA IAD N829AS EV
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
336770 │ 2013 9 30 23.0 JFK PSE N516JB B6
336771 │ 2013 9 30 18.0 LGA BNA N740EV EV
336772 │ 2013 9 30 14.0 JFK DCA missing 9E
336773 │ 2013 9 30 22.0 LGA SYR missing 9E
336774 │ 2013 9 30 12.0 LGA BNA N535MQ MQ
336775 │ 2013 9 30 11.0 LGA CLE N511MQ MQ
336776 │ 2013 9 30 8.0 LGA RDU N839MQ MQ
336761 rows omitted
We want to merge with the weather table:
# A tibble: 26,115 × 15
origin year month day hour temp dewp humid wind_dir wind_speed wind_g…¹
<chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4 NA
2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06 NA
3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5 NA
4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7 NA
5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7 NA
6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5 NA
7 EWR 2013 1 1 7 39.0 28.0 64.4 240 15.0 NA
8 EWR 2013 1 1 8 39.9 28.0 62.2 250 10.4 NA
9 EWR 2013 1 1 9 39.9 28.0 62.2 260 15.0 NA
10 EWR 2013 1 1 10 41 28.0 59.6 260 13.8 NA
# … with 26,105 more rows, 4 more variables: precip <dbl>, pressure <dbl>,
# visib <dbl>, time_hour <dttm>, and abbreviated variable name ¹wind_gust
origin year month day hour temp dewp humid wind_dir \
0 EWR 2013 1 1 1 39.02 26.06 59.37 270.0
1 EWR 2013 1 1 2 39.02 26.96 61.63 250.0
2 EWR 2013 1 1 3 39.02 28.04 64.43 240.0
3 EWR 2013 1 1 4 39.92 28.04 62.21 250.0
4 EWR 2013 1 1 5 39.02 28.04 64.43 260.0
... ... ... ... ... ... ... ... ... ...
26110 LGA 2013 12 30 14 35.96 19.94 51.78 340.0
26111 LGA 2013 12 30 15 33.98 17.06 49.51 330.0
26112 LGA 2013 12 30 16 32.00 15.08 49.19 340.0
26113 LGA 2013 12 30 17 30.92 12.92 46.74 320.0
26114 LGA 2013 12 30 18 28.94 10.94 46.41 330.0
wind_speed wind_gust precip pressure visib time_hour
0 10.35702 NaN 0.0 1012.0 10.0 2013-01-01T06:00:00Z
1 8.05546 NaN 0.0 1012.3 10.0 2013-01-01T07:00:00Z
2 11.50780 NaN 0.0 1012.5 10.0 2013-01-01T08:00:00Z
3 12.65858 NaN 0.0 1012.2 10.0 2013-01-01T09:00:00Z
4 12.65858 NaN 0.0 1011.9 10.0 2013-01-01T10:00:00Z
... ... ... ... ... ... ...
26110 13.80936 21.86482 0.0 1017.1 10.0 2013-12-30T19:00:00Z
26111 17.26170 21.86482 0.0 1018.8 10.0 2013-12-30T20:00:00Z
26112 14.96014 23.01560 0.0 1019.5 10.0 2013-12-30T21:00:00Z
26113 17.26170 NaN 0.0 1019.9 10.0 2013-12-30T22:00:00Z
26114 18.41248 NaN 0.0 1020.9 10.0 2013-12-30T23:00:00Z
[26115 rows x 15 columns]
26115×15 DataFrame
Row │ origin year month day hour temp dewp humid win ⋯
│ String Int64 Int64 Int64 Int64 Float64? Float64? Float64? Flo ⋯
───────┼────────────────────────────────────────────────────────────────────────
1 │ EWR 2013 1 1 1 39.02 26.06 59.37 ⋯
2 │ EWR 2013 1 1 2 39.02 26.96 61.63
3 │ EWR 2013 1 1 3 39.02 28.04 64.43
4 │ EWR 2013 1 1 4 39.92 28.04 62.21
5 │ EWR 2013 1 1 5 39.02 28.04 64.43 ⋯
6 │ EWR 2013 1 1 6 37.94 28.04 67.21
7 │ EWR 2013 1 1 7 39.02 28.04 64.43
8 │ EWR 2013 1 1 8 39.92 28.04 62.21
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
26109 │ LGA 2013 12 30 12 37.94 23.0 54.51 ⋯
26110 │ LGA 2013 12 30 13 37.04 21.92 53.97
26111 │ LGA 2013 12 30 14 35.96 19.94 51.78
26112 │ LGA 2013 12 30 15 33.98 17.06 49.51
26113 │ LGA 2013 12 30 16 32.0 15.08 49.19 ⋯
26114 │ LGA 2013 12 30 17 30.92 12.92 46.74
26115 │ LGA 2013 12 30 18 28.94 10.94 46.41
7 columns and 26100 rows omitted
Defining the key columns
by = NULL (default): use all variables that appear in both tables:
# same as: flights2 %>% left_join(weather) left_join (flights2, weather)
# A tibble: 336,776 × 18
year month day hour origin dest tailnum carrier temp dewp humid
<int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
1 2013 1 1 5 EWR IAH N14228 UA 39.0 28.0 64.4
2 2013 1 1 5 LGA IAH N24211 UA 39.9 25.0 54.8
3 2013 1 1 5 JFK MIA N619AA AA 39.0 27.0 61.6
4 2013 1 1 5 JFK BQN N804JB B6 39.0 27.0 61.6
5 2013 1 1 6 LGA ATL N668DN DL 39.9 25.0 54.8
6 2013 1 1 5 EWR ORD N39463 UA 39.0 28.0 64.4
7 2013 1 1 6 EWR FLL N516JB B6 37.9 28.0 67.2
8 2013 1 1 6 LGA IAD N829AS EV 39.9 25.0 54.8
9 2013 1 1 6 JFK MCO N593JB B6 37.9 27.0 64.3
10 2013 1 1 6 LGA ORD N3ALAA AA 39.9 25.0 54.8
# … with 336,766 more rows, and 7 more variables: wind_dir <dbl>,
# wind_speed <dbl>, wind_gust <dbl>, precip <dbl>, pressure <dbl>,
# visib <dbl>, time_hour <dttm>
by = "x": use the common variable x:
# same as: flights2 %>% left_join(weather) left_join (flights2, planes, by = "tailnum" )
# A tibble: 336,776 × 16
year.x month day hour origin dest tailnum carrier year.y type manuf…¹
<int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <int> <chr> <chr>
1 2013 1 1 5 EWR IAH N14228 UA 1999 Fixed w… BOEING
2 2013 1 1 5 LGA IAH N24211 UA 1998 Fixed w… BOEING
3 2013 1 1 5 JFK MIA N619AA AA 1990 Fixed w… BOEING
4 2013 1 1 5 JFK BQN N804JB B6 2012 Fixed w… AIRBUS
5 2013 1 1 6 LGA ATL N668DN DL 1991 Fixed w… BOEING
6 2013 1 1 5 EWR ORD N39463 UA 2012 Fixed w… BOEING
7 2013 1 1 6 EWR FLL N516JB B6 2000 Fixed w… AIRBUS…
8 2013 1 1 6 LGA IAD N829AS EV 1998 Fixed w… CANADA…
9 2013 1 1 6 JFK MCO N593JB B6 2004 Fixed w… AIRBUS
10 2013 1 1 6 LGA ORD N3ALAA AA NA <NA> <NA>
# … with 336,766 more rows, 5 more variables: model <chr>, engines <int>,
# seats <int>, speed <int>, engine <chr>, and abbreviated variable name
# ¹manufacturer
by = c("a" = "b"): match variable a in table x to the variable b in table y.
# same as: flights2 %>% left_join(weather) left_join (flights2, airports, by = c ("dest" = "faa" ))
# A tibble: 336,776 × 15
year month day hour origin dest tailnum carrier name lat lon alt
<int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
1 2013 1 1 5 EWR IAH N14228 UA Georg… 30.0 -95.3 97
2 2013 1 1 5 LGA IAH N24211 UA Georg… 30.0 -95.3 97
3 2013 1 1 5 JFK MIA N619AA AA Miami… 25.8 -80.3 8
4 2013 1 1 5 JFK BQN N804JB B6 <NA> NA NA NA
5 2013 1 1 6 LGA ATL N668DN DL Harts… 33.6 -84.4 1026
6 2013 1 1 5 EWR ORD N39463 UA Chica… 42.0 -87.9 668
7 2013 1 1 6 EWR FLL N516JB B6 Fort … 26.1 -80.2 9
8 2013 1 1 6 LGA IAD N829AS EV Washi… 38.9 -77.5 313
9 2013 1 1 6 JFK MCO N593JB B6 Orlan… 28.4 -81.3 96
10 2013 1 1 6 LGA ORD N3ALAA AA Chica… 42.0 -87.9 668
# … with 336,766 more rows, and 3 more variables: tz <dbl>, dst <chr>,
# tzone <chr>
Match multiple keys using multi-index:
= ['origin' , 'year' , 'month' , 'day' , 'hour' ]= keys,= 'left' )
year month day hour origin dest tailnum carrier temp dewp \
0 2013 1 1 5 EWR IAH N14228 UA 39.02 28.04
1 2013 1 1 5 LGA IAH N24211 UA 39.92 24.98
2 2013 1 1 5 JFK MIA N619AA AA 39.02 26.96
3 2013 1 1 5 JFK BQN N804JB B6 39.02 26.96
4 2013 1 1 6 LGA ATL N668DN DL 39.92 24.98
... ... ... ... ... ... ... ... ... ... ...
336771 2013 9 30 14 JFK DCA NaN 9E 68.00 55.04
336772 2013 9 30 22 LGA SYR NaN 9E 64.94 53.06
336773 2013 9 30 12 LGA BNA N535MQ MQ 69.08 48.02
336774 2013 9 30 11 LGA CLE N511MQ MQ 66.92 48.92
336775 2013 9 30 8 LGA RDU N839MQ MQ 60.98 51.08
humid wind_dir wind_speed wind_gust precip pressure visib \
0 64.43 260.0 12.65858 NaN 0.0 1011.9 10.0
1 54.81 250.0 14.96014 21.86482 0.0 1011.4 10.0
2 61.63 260.0 14.96014 NaN 0.0 1012.1 10.0
3 61.63 260.0 14.96014 NaN 0.0 1012.1 10.0
4 54.81 260.0 16.11092 23.01560 0.0 1011.7 10.0
... ... ... ... ... ... ... ...
336771 63.21 190.0 11.50780 NaN 0.0 1016.6 10.0
336772 65.37 200.0 6.90468 NaN 0.0 1015.8 10.0
336773 46.99 70.0 5.75390 NaN 0.0 1016.7 10.0
336774 52.35 70.0 8.05546 NaN 0.0 1017.5 10.0
336775 69.86 NaN 5.75390 NaN 0.0 1018.6 10.0
time_hour
0 2013-01-01T10:00:00Z
1 2013-01-01T10:00:00Z
2 2013-01-01T10:00:00Z
3 2013-01-01T10:00:00Z
4 2013-01-01T11:00:00Z
... ...
336771 2013-09-30T18:00:00Z
336772 2013-10-01T02:00:00Z
336773 2013-09-30T16:00:00Z
336774 2013-09-30T15:00:00Z
336775 2013-09-30T12:00:00Z
[336776 rows x 18 columns]
Match the common variable tailnum:
'tailnum' ), = 'tailnum' , = 'left' ,= '_x' ,= '_y'
year_x month day hour origin dest tailnum carrier year_y \
0 2013 1 1 5 EWR IAH N14228 UA 1999.0
1 2013 1 1 5 LGA IAH N24211 UA 1998.0
2 2013 1 1 5 JFK MIA N619AA AA 1990.0
3 2013 1 1 5 JFK BQN N804JB B6 2012.0
4 2013 1 1 6 LGA ATL N668DN DL 1991.0
... ... ... ... ... ... ... ... ... ...
336771 2013 9 30 14 JFK DCA NaN 9E NaN
336772 2013 9 30 22 LGA SYR NaN 9E NaN
336773 2013 9 30 12 LGA BNA N535MQ MQ NaN
336774 2013 9 30 11 LGA CLE N511MQ MQ NaN
336775 2013 9 30 8 LGA RDU N839MQ MQ NaN
type manufacturer model engines seats speed \
0 Fixed wing multi engine BOEING 737-824 2.0 149.0 NaN
1 Fixed wing multi engine BOEING 737-824 2.0 149.0 NaN
2 Fixed wing multi engine BOEING 757-223 2.0 178.0 NaN
3 Fixed wing multi engine AIRBUS A320-232 2.0 200.0 NaN
4 Fixed wing multi engine BOEING 757-232 2.0 178.0 NaN
... ... ... ... ... ... ...
336771 NaN NaN NaN NaN NaN NaN
336772 NaN NaN NaN NaN NaN NaN
336773 NaN NaN NaN NaN NaN NaN
336774 NaN NaN NaN NaN NaN NaN
336775 NaN NaN NaN NaN NaN NaN
engine
0 Turbo-fan
1 Turbo-fan
2 Turbo-fan
3 Turbo-fan
4 Turbo-fan
... ...
336771 NaN
336772 NaN
336773 NaN
336774 NaN
336775 NaN
[336776 rows x 16 columns]
Match variable a in table x to the variable b in table y.
'dest' 'faa' ), = 'left'
year month day hour origin tailnum carrier \
ABQ 2013 10 1 20 JFK N554JB B6
ABQ 2013 10 2 20 JFK N607JB B6
ABQ 2013 10 3 20 JFK N591JB B6
ABQ 2013 10 4 20 JFK N662JB B6
ABQ 2013 10 5 19 JFK N580JB B6
.. ... ... ... ... ... ... ...
XNA 2013 9 29 17 LGA N725MQ MQ
XNA 2013 9 30 7 LGA N735MQ MQ
XNA 2013 9 30 8 EWR N14117 EV
XNA 2013 9 30 15 LGA N725MQ MQ
XNA 2013 9 30 17 LGA N720MQ MQ
name lat lon alt tz \
ABQ Albuquerque International Sunport 35.040222 -106.609194 5355.0 -7.0
ABQ Albuquerque International Sunport 35.040222 -106.609194 5355.0 -7.0
ABQ Albuquerque International Sunport 35.040222 -106.609194 5355.0 -7.0
ABQ Albuquerque International Sunport 35.040222 -106.609194 5355.0 -7.0
ABQ Albuquerque International Sunport 35.040222 -106.609194 5355.0 -7.0
.. ... ... ... ... ...
XNA NW Arkansas Regional 36.281869 -94.306811 1287.0 -6.0
XNA NW Arkansas Regional 36.281869 -94.306811 1287.0 -6.0
XNA NW Arkansas Regional 36.281869 -94.306811 1287.0 -6.0
XNA NW Arkansas Regional 36.281869 -94.306811 1287.0 -6.0
XNA NW Arkansas Regional 36.281869 -94.306811 1287.0 -6.0
dst tzone
ABQ A America/Denver
ABQ A America/Denver
ABQ A America/Denver
ABQ A America/Denver
ABQ A America/Denver
.. .. ...
XNA A America/Chicago
XNA A America/Chicago
XNA A America/Chicago
XNA A America/Chicago
XNA A America/Chicago
[336776 rows x 14 columns]
Match multiple variables:
leftjoin (= [: year, : month, : day, : hour, : origin]
336776×18 DataFrame
Row │ year month day hour origin dest tailnum carrier temp ⋯
│ Int64 Int64 Int64 Float64 String String String? String Floa ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 5.0 EWR IAH N14228 UA ⋯
2 │ 2013 1 1 5.0 LGA IAH N24211 UA
3 │ 2013 1 1 5.0 JFK MIA N619AA AA
4 │ 2013 1 1 5.0 JFK BQN N804JB B6
5 │ 2013 1 1 6.0 LGA ATL N668DN DL ⋯
6 │ 2013 1 1 5.0 EWR ORD N39463 UA
7 │ 2013 1 1 6.0 EWR FLL N516JB B6
8 │ 2013 1 1 6.0 LGA IAD N829AS EV
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 2 16.0 EWR CVG N14573 EV miss ⋯
336771 │ 2013 9 2 16.0 EWR SAV N11547 EV miss
336772 │ 2013 9 2 16.0 EWR ROC N11548 EV miss
336773 │ 2013 9 2 16.0 EWR GSO N13978 EV miss
336774 │ 2013 9 2 16.0 EWR ATL N13202 EV miss ⋯
336775 │ 2013 9 2 16.0 EWR CVG missing 9E miss
336776 │ 2013 9 2 16.0 EWR PHX missing US miss
10 columns and 336761 rows omitted
Match the common variable tailnum:
leftjoin (= : tailnum,= true ,= : notequal
336776×16 DataFrame
Row │ year month day hour origin dest tailnum carrier year ⋯
│ Int64 Int64 Int64 Float64 String String String? String Int6 ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 5.0 EWR IAH N14228 UA 1 ⋯
2 │ 2013 1 1 5.0 LGA IAH N24211 UA 1
3 │ 2013 1 1 5.0 JFK MIA N619AA AA 1
4 │ 2013 1 1 5.0 JFK BQN N804JB B6 2
5 │ 2013 1 1 6.0 LGA ATL N668DN DL 1 ⋯
6 │ 2013 1 1 5.0 EWR ORD N39463 UA 2
7 │ 2013 1 1 6.0 EWR FLL N516JB B6 2
8 │ 2013 1 1 6.0 LGA IAD N829AS EV 1
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 30 21.0 JFK DCA N807MQ MQ miss ⋯
336771 │ 2013 9 30 21.0 LGA BNA N532MQ MQ miss
336772 │ 2013 9 30 14.0 JFK DCA missing 9E miss
336773 │ 2013 9 30 22.0 LGA SYR missing 9E miss
336774 │ 2013 9 30 12.0 LGA BNA N535MQ MQ miss ⋯
336775 │ 2013 9 30 11.0 LGA CLE N511MQ MQ miss
336776 │ 2013 9 30 8.0 LGA RDU N839MQ MQ miss
8 columns and 336761 rows omitted
Match variable a in table x to the variable b in table y.
leftjoin (= : dest => : faa
336776×15 DataFrame
Row │ year month day hour origin dest tailnum carrier name ⋯
│ Int64 Int64 Int64 Float64 String String String? String Stri ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 5.0 EWR IAH N14228 UA Geor ⋯
2 │ 2013 1 1 5.0 LGA IAH N24211 UA Geor
3 │ 2013 1 1 5.0 JFK MIA N619AA AA Miam
4 │ 2013 1 1 6.0 LGA ATL N668DN DL Hart
5 │ 2013 1 1 5.0 EWR ORD N39463 UA Chic ⋯
6 │ 2013 1 1 6.0 EWR FLL N516JB B6 Fort
7 │ 2013 1 1 6.0 LGA IAD N829AS EV Wash
8 │ 2013 1 1 6.0 JFK MCO N593JB B6 Orla
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
336770 │ 2013 9 30 8.0 JFK SJU N3772H DL miss ⋯
336771 │ 2013 9 30 14.0 JFK SJU N652JB B6 miss
336772 │ 2013 9 30 15.0 JFK SJU N5FTAA AA miss
336773 │ 2013 9 30 15.0 JFK SJU N3756 DL miss
336774 │ 2013 9 30 20.0 JFK SJU N396DA DL miss ⋯
336775 │ 2013 9 30 21.0 JFK SJU N633JB B6 miss
336776 │ 2013 9 30 23.0 JFK PSE N516JB B6 miss
7 columns and 336761 rows omitted
Combine cases (rows)
Top 10 most popular destinations:
<- flights %>% count (dest, sort = TRUE ) %>% head (10 )
# A tibble: 10 × 2
dest n
<chr> <int>
1 ORD 17283
2 ATL 17215
3 LAX 16174
4 BOS 15508
5 MCO 14082
6 CLT 14064
7 SFO 13331
8 FLL 12055
9 MIA 11728
10 DCA 9705
= flights.groupby('dest' )['dest' ].count(= 'n' 'n' , = False 10 )
dest n
69 ORD 17283
4 ATL 17215
49 LAX 16174
11 BOS 15508
54 MCO 14082
23 CLT 14064
90 SFO 13331
35 FLL 12055
58 MIA 11728
28 DCA 9705
= @pipe flights |> groupby (_, : dest) |> combine (_, nrow) |> sort (_, : nrow, rev = true ) |> first (_, 10 )
10×2 DataFrame
Row │ dest nrow
│ String Int64
─────┼───────────────
1 │ ORD 17283
2 │ ATL 17215
3 │ LAX 16174
4 │ BOS 15508
5 │ MCO 14082
6 │ CLT 14064
7 │ SFO 13331
8 │ FLL 12055
9 │ MIA 11728
10 │ DCA 9705
How to filter the cases that fly to these destinations?
Semi-join
semi_join (flights, top_dest)
# A tibble: 141,145 × 19
year month day dep_time sched_de…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
<int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
1 2013 1 1 542 540 2 923 850 33 AA
2 2013 1 1 554 600 -6 812 837 -25 DL
3 2013 1 1 554 558 -4 740 728 12 UA
4 2013 1 1 555 600 -5 913 854 19 B6
5 2013 1 1 557 600 -3 838 846 -8 B6
6 2013 1 1 558 600 -2 753 745 8 AA
7 2013 1 1 558 600 -2 924 917 7 UA
8 2013 1 1 558 600 -2 923 937 -14 UA
9 2013 1 1 559 559 0 702 706 -4 B6
10 2013 1 1 600 600 0 851 858 -7 B6
# … with 141,135 more rows, 9 more variables: flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>, and abbreviated variable names
# ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay
'dest' ].isin(top_dest['dest' ])]
year month day dep_time sched_dep_time dep_delay arr_time \
2 2013 1 1 542.0 540 2.0 923.0
4 2013 1 1 554.0 600 -6.0 812.0
5 2013 1 1 554.0 558 -4.0 740.0
6 2013 1 1 555.0 600 -5.0 913.0
8 2013 1 1 557.0 600 -3.0 838.0
... ... ... ... ... ... ... ...
336755 2013 9 30 2149.0 2156 -7.0 2245.0
336762 2013 9 30 2233.0 2113 80.0 112.0
336763 2013 9 30 2235.0 2001 154.0 59.0
336768 2013 9 30 2307.0 2255 12.0 2359.0
336771 2013 9 30 NaN 1455 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest \
2 850 33.0 AA 1141 N619AA JFK MIA
4 837 -25.0 DL 461 N668DN LGA ATL
5 728 12.0 UA 1696 N39463 EWR ORD
6 854 19.0 B6 507 N516JB EWR FLL
8 846 -8.0 B6 79 N593JB JFK MCO
... ... ... ... ... ... ... ...
336755 2308 -23.0 UA 523 N813UA EWR BOS
336762 30 42.0 UA 471 N578UA EWR SFO
336763 2249 130.0 B6 1083 N804JB JFK MCO
336768 2358 1.0 B6 718 N565JB JFK BOS
336771 1634 NaN 9E 3393 NaN JFK DCA
air_time distance hour minute time_hour
2 160.0 1089 5 40 2013-01-01 10:00:00+00:00
4 116.0 762 6 0 2013-01-01 11:00:00+00:00
5 150.0 719 5 58 2013-01-01 10:00:00+00:00
6 158.0 1065 6 0 2013-01-01 11:00:00+00:00
8 140.0 944 6 0 2013-01-01 11:00:00+00:00
... ... ... ... ... ...
336755 37.0 200 21 56 2013-10-01 01:00:00+00:00
336762 318.0 2565 21 13 2013-10-01 01:00:00+00:00
336763 123.0 944 20 1 2013-10-01 00:00:00+00:00
336768 33.0 187 22 55 2013-10-01 02:00:00+00:00
336771 NaN 213 14 55 2013-09-30 18:00:00+00:00
[141145 rows x 19 columns]
semijoin (flights, top_dest, on = : dest)
141145×19 DataFrame
Row │ year month day dep_time sched_dep_time dep_delay arr_time ⋯
│ Int64 Int64 Int64 Int64? Int64 Float64? Int64? ⋯
────────┼───────────────────────────────────────────────────────────────────────
1 │ 2013 1 1 542 540 2.0 923 ⋯
2 │ 2013 1 1 554 600 -6.0 812
3 │ 2013 1 1 554 558 -4.0 740
4 │ 2013 1 1 555 600 -5.0 913
5 │ 2013 1 1 557 600 -3.0 838 ⋯
6 │ 2013 1 1 558 600 -2.0 753
7 │ 2013 1 1 558 600 -2.0 924
8 │ 2013 1 1 558 600 -2.0 923
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋱
141139 │ 2013 9 30 2140 2140 0.0 10 ⋯
141140 │ 2013 9 30 2147 2137 10.0 30
141141 │ 2013 9 30 2149 2156 -7.0 2245
141142 │ 2013 9 30 2233 2113 80.0 112
141143 │ 2013 9 30 2235 2001 154.0 59 ⋯
141144 │ 2013 9 30 2307 2255 12.0 2359
141145 │ 2013 9 30 missing 1455 missing missing
12 columns and 141130 rows omitted
Anti-join
# Planes that are not in planes table %>% anti_join (planes, by = "tailnum" ) %>% count (tailnum, sort = TRUE )
# A tibble: 722 × 2
tailnum n
<chr> <int>
1 <NA> 2512
2 N725MQ 575
3 N722MQ 513
4 N723MQ 507
5 N713MQ 483
6 N735MQ 396
7 N0EGMQ 371
8 N534MQ 364
9 N542MQ 363
10 N531MQ 349
# … with 712 more rows
- flights['tailnum' ].isin(planes['tailnum' ])].groupby('tailnum' )['tailnum' ].count().sort_values(ascending = False )
tailnum
N725MQ 575
N722MQ 513
N723MQ 507
N713MQ 483
N735MQ 396
...
N7ASAA 1
N3LFAA 1
N7ALAA 1
N7AEAA 1
N5ERAA 1
Name: tailnum, Length: 721, dtype: int64
@pipe antijoin (= : tailnum, = : notequal|> groupby (_, : tailnum) |> combine (_, nrow) |> sort (_, : nrow, rev = true )
722×2 DataFrame
Row │ tailnum nrow
│ String? Int64
─────┼────────────────
1 │ missing 2512
2 │ N725MQ 575
3 │ N722MQ 513
4 │ N723MQ 507
5 │ N713MQ 483
6 │ N735MQ 396
7 │ N0EGMQ 371
8 │ N534MQ 364
⋮ │ ⋮ ⋮
716 │ N502SW 1
717 │ N451UW 1
718 │ N7BKAA 1
719 │ N7CAAA 1
720 │ N5FCAA 1
721 │ N5ERAA 1
722 │ N647MQ 1
707 rows omitted
Set operations
<- tribble (~ x, ~ y,1 , 1 ,2 , 1
# A tibble: 2 × 2
x y
<dbl> <dbl>
1 1 1
2 2 1
<- tribble (~ x, ~ y,1 , 1 ,1 , 2
# A tibble: 2 × 2
x y
<dbl> <dbl>
1 1 1
2 1 2
= pd.DataFrame({'x' : [1 , 2 ],'y' : [1 , 1 ]= pd.DataFrame({'x' : [1 , 1 ],'y' : [1 , 2 ]
= DataFrame (= [1 , 2 ],= [1 , 1 ]
2×2 DataFrame
Row │ x y
│ Int64 Int64
─────┼──────────────
1 │ 1 1
2 │ 2 1
= DataFrame (= [1 , 1 ],= [1 , 2 ]
2×2 DataFrame
Row │ x y
│ Int64 Int64
─────┼──────────────
1 │ 1 1
2 │ 1 2
bind_rows(x, y) stacks table x one on top of y.
# A tibble: 4 × 2
x y
<dbl> <dbl>
1 1 1
2 2 1
3 1 1
4 1 2
= 0 )
x y
0 1 1
1 2 1
0 1 1
1 1 2
4×2 DataFrame
Row │ x y
│ Int64 Int64
─────┼──────────────
1 │ 1 1
2 │ 2 1
3 │ 1 1
4 │ 1 2
intersect(x, y) returns rows that appear in both x and y.
# A tibble: 1 × 2
x y
<dbl> <dbl>
1 1 1
= 'inner' , on = ['x' , 'y' ])
DataFrame (intersect (eachrow (df1), eachrow (df2)))
1×2 DataFrame
Row │ x y
│ Int64 Int64
─────┼──────────────
1 │ 1 1
union(x, y) returns unique observations in x and y.
# A tibble: 3 × 2
x y
<dbl> <dbl>
1 1 1
2 2 1
3 1 2
= 'outer' , on = ['x' , 'y' ])
DataFrame (union (eachrow (df1), eachrow (df2)))
3×2 DataFrame
Row │ x y
│ Int64 Int64
─────┼──────────────
1 │ 1 1
2 │ 2 1
3 │ 1 2
setdiff(x, y) returns rows that appear in x but not in y.
# A tibble: 1 × 2
x y
<dbl> <dbl>
1 2 1
# A tibble: 1 × 2
x y
<dbl> <dbl>
1 1 2
Not sure how to do this elegantly.
DataFrame (setdiff (eachrow (df1), eachrow (df2)))
1×2 DataFrame
Row │ x y
│ Int64 Int64
─────┼──────────────
1 │ 2 1
DataFrame (setdiff (eachrow (df2), eachrow (df1)))
1×2 DataFrame
Row │ x y
│ Int64 Int64
─────┼──────────────
1 │ 1 2