# Specifying the url for desired website to be scrapedurl <-"https://www.imdb.com/search/title/?title_type=feature&release_date=2020-01-01,2020-12-31&count=100"# Reading the HTML code from the website(webpage <-read_html(url))
Use SelectorGadget to find the CSS selector .lister-item-header a.
# Using CSS selectors to scrap the title section(title_data_html <-html_nodes(webpage, '.lister-item-header a'))
{xml_nodeset (100)}
[1] <a href="/title/tt6723592/?ref_=adv_li_tt">Tenet</a>
[2] <a href="/title/tt5918982/?ref_=adv_li_tt">Possessor</a>
[3] <a href="/title/tt7923220/?ref_=adv_li_tt">Inheritance</a>
[4] <a href="/title/tt7628504/?ref_=adv_li_tt">Megan</a>
[5] <a href="/title/tt10886166/?ref_=adv_li_tt">365 Days</a>
[6] <a href="/title/tt7126948/?ref_=adv_li_tt">Wonder Woman 1984</a>
[7] <a href="/title/tt10344522/?ref_=adv_li_tt">Four Good Days</a>
[8] <a href="/title/tt10272386/?ref_=adv_li_tt">The Father</a>
[9] <a href="/title/tt7846844/?ref_=adv_li_tt">Enola Holmes</a>
[10] <a href="/title/tt9620292/?ref_=adv_li_tt">Promising Young Woman</a>
[11] <a href="/title/tt8503618/?ref_=adv_li_tt">Hamilton</a>
[12] <a href="/title/tt8332922/?ref_=adv_li_tt">A Quiet Place Part II</a>
[13] <a href="/title/tt7395114/?ref_=adv_li_tt">The Devil All the Time</a>
[14] <a href="/title/tt2222042/?ref_=adv_li_tt">Love and Monsters</a>
[15] <a href="/title/tt9340860/?ref_=adv_li_tt">Let Him Go</a>
[16] <a href="/title/tt7939766/?ref_=adv_li_tt">I'm Thinking of Ending Things ...
[17] <a href="/title/tt10288566/?ref_=adv_li_tt">Another Round</a>
[18] <a href="/title/tt9214832/?ref_=adv_li_tt">Emma.</a>
[19] <a href="/title/tt1502397/?ref_=adv_li_tt">Bad Boys for Life</a>
[20] <a href="/title/tt10919380/?ref_=adv_li_tt">Freaky</a>
...
# Converting the title data to text(title_data <-html_text(title_data_html))
[1] "Tenet"
[2] "Possessor"
[3] "Inheritance"
[4] "Megan"
[5] "365 Days"
[6] "Wonder Woman 1984"
[7] "Four Good Days"
[8] "The Father"
[9] "Enola Holmes"
[10] "Promising Young Woman"
[11] "Hamilton"
[12] "A Quiet Place Part II"
[13] "The Devil All the Time"
[14] "Love and Monsters"
[15] "Let Him Go"
[16] "I'm Thinking of Ending Things"
[17] "Another Round"
[18] "Emma."
[19] "Bad Boys for Life"
[20] "Freaky"
[21] "Birds of Prey"
[22] "The Forgotten Battle"
[23] "Nomadland"
[24] "Palm Springs"
[25] "The Dry"
[26] "Extraction"
[27] "Soul"
[28] "After We Collided"
[29] "The Old Guard"
[30] "Come Play"
[31] "The Babysitter: Killer Queen"
[32] "Greenland"
[33] "The Hunt"
[34] "The Midnight Sky"
[35] "Ava"
[36] "Mulan"
[37] "Underwater"
[38] "Greyhound"
[39] "Black Bear"
[40] "The Empty Man"
[41] "Pieces of a Woman"
[42] "Run"
[43] "The Night House"
[44] "Sonic the Hedgehog"
[45] "The Rental"
[46] "We Can Be Heroes"
[47] "The Invisible Man"
[48] "The Courier"
[49] "You Should Have Left"
[50] "The New Mutants"
[51] "Monster Hunter"
[52] "The Woman in the Window"
[53] "Eurovision Song Contest: The Story of Fire Saga"
[54] "Wild Mountain Thyme"
[55] "The King of Staten Island"
[56] "The Tax Collector"
[57] "The Wrong Missy"
[58] "The Trial of the Chicago 7"
[59] "I Care a Lot"
[60] "The Craft: Legacy"
[61] "Boss Level"
[62] "Unhinged"
[63] "Mank"
[64] "Project Power"
[65] "The Croods: A New Age"
[66] "Becky"
[67] "The F**k-It List"
[68] "Spenser Confidential"
[69] "Shiva Baby"
[70] "Big Boys Don't Cry"
[71] "The Call"
[72] "Rebecca"
[73] "The Call of the Wild"
[74] "The Witches"
[75] "The Duke"
[76] "Minari"
[77] "Demon Slayer the Movie: Mugen Train"
[78] "Onward"
[79] "Alone"
[80] "Host"
[81] "Dolittle"
[82] "Songbird"
[83] "Hubie Halloween"
[84] "Trolls World Tour"
[85] "2 Hearts"
[86] "Riders of Justice"
[87] "News of the World"
[88] "All the Bright Places"
[89] "Borat Subsequent Moviefilm"
[90] "Horizon Line"
[91] "Run Sweetheart Run"
[92] "Fantasy Island"
[93] "Ammonite"
[94] "Eat Wheaties!"
[95] "Holidate"
[96] "The Comeback Trail"
[97] "#Alive"
[98] "Lost Girls and Love Hotels"
[99] "Nowhere Special"
[100] "Hillbilly Elegy"
3.3 Description
# Using CSS selectors to scrap the description section(description_data_html <-html_nodes(webpage, '.ratings-bar+ .text-muted'))
{xml_nodeset (100)}
[1] <p class="text-muted">\nArmed with only one word, Tenet, and fighting fo ...
[2] <p class="text-muted">\nAn agent works for a secretive organization that ...
[3] <p class="text-muted">\nThe patriarch of a wealthy and powerful family s ...
[4] <p class="text-muted">\nA hiker finds shelter in a mountain lodge inhabi ...
[5] <p class="text-muted">\nMassimo is a member of the Sicilian Mafia family ...
[6] <p class="text-muted">\nDiana must contend with a work colleague, and wi ...
[7] <p class="text-muted">\nA mother helps her daughter work through four cr ...
[8] <p class="text-muted">\nA man refuses all assistance from his daughter a ...
[9] <p class="text-muted">\nWhen Enola Holmes (Sherlock's teen sister) disco ...
[10] <p class="text-muted">\nA young woman, traumatized by a tragic event in ...
[11] <p class="text-muted">\nThe real life of one of America's foremost found ...
[12] <p class="text-muted">\nFollowing the events at home, the Abbott family ...
[13] <p class="text-muted">\nSinister characters converge around a young man ...
[14] <p class="text-muted">\nSeven years after he survived the monster apocal ...
[15] <p class="text-muted">\nA retired sheriff and his wife, grieving over th ...
[16] <p class="text-muted">\nFull of misgivings, a young woman travels with h ...
[17] <p class="text-muted">\nFour high-school teachers consume alcohol on a d ...
[18] <p class="text-muted">\nIn 1800s England, a well meaning but selfish you ...
[19] <p class="text-muted">\nMiami detectives Mike Lowrey and Marcus Burnett ...
[20] <p class="text-muted">\nAfter swapping bodies with a deranged serial kil ...
...
# Converting the description data to textdescription_data <-html_text(description_data_html)# take a look at first fewhead(description_data)
[1] "\nArmed with only one word, Tenet, and fighting for the survival of the entire world, a Protagonist journeys through a twilight world of international espionage on a mission that will unfold in something beyond real time."
[2] "\nAn agent works for a secretive organization that uses brain-implant technology to inhabit other people's bodies - ultimately driving them to commit assassinations for high-paying clients."
[3] "\nThe patriarch of a wealthy and powerful family suddenly passes away, leaving his daughter with a shocking secret inheritance that threatens to unravel and destroy the family."
[4] "\nA hiker finds shelter in a mountain lodge inhabited by two strange women."
[5] "\nMassimo is a member of the Sicilian Mafia family and Laura is a sales director. She does not expect that on a trip to Sicily trying to save her relationship, Massimo will kidnap her and give her 365 days to fall in love with him."
[6] "\nDiana must contend with a work colleague, and with a businessman whose desire for extreme wealth sends the world down a path of destruction, after an ancient artifact that grants wishes goes missing."
# strip the '\n'description_data <-str_replace(description_data, "^\\n", "")head(description_data)
[1] "Armed with only one word, Tenet, and fighting for the survival of the entire world, a Protagonist journeys through a twilight world of international espionage on a mission that will unfold in something beyond real time."
[2] "An agent works for a secretive organization that uses brain-implant technology to inhabit other people's bodies - ultimately driving them to commit assassinations for high-paying clients."
[3] "The patriarch of a wealthy and powerful family suddenly passes away, leaving his daughter with a shocking secret inheritance that threatens to unravel and destroy the family."
[4] "A hiker finds shelter in a mountain lodge inhabited by two strange women."
[5] "Massimo is a member of the Sicilian Mafia family and Laura is a sales director. She does not expect that on a trip to Sicily trying to save her relationship, Massimo will kidnap her and give her 365 days to fall in love with him."
[6] "Diana must contend with a work colleague, and with a businessman whose desire for extreme wealth sends the world down a path of destruction, after an ancient artifact that grants wishes goes missing."
3.4 Runtime
Retrieve runtime data
# Using CSS selectors to scrap the Movie runtime section(runtime_data <- webpage %>%html_nodes('.runtime') %>%html_text() %>%str_replace(" min", "") %>%as.integer())
genre_data <- webpage %>%# Using CSS selectors to scrap the Movie genre sectionhtml_nodes('.genre') %>%# Converting the genre data to texthtml_text() %>%# Data-Preprocessing: retrieve the first wordstr_extract("[:alpha:]+")genre_data
We encounter the issue of missing data when scraping metascore.
We see there are only 90 meta scores. 10 movies don’t have meta scores. We may manually find which movies don’t have meta scores but that’s tedious and not reproducible.
# Using CSS selectors to scrap the metascore sectionms_data_html <-html_nodes(webpage, '.metascore')# Converting the runtime data to textms_data <-html_text(ms_data_html)# Let's have a look at the metascore ms_data <-str_replace(ms_data, "\\s*$", "") %>%as.integer()ms_data
[1] 69 72 31 NA NA 60 52 88 68 73 89 71 55 63 63 78 79 71 59 67 60 NA 91 83 69
[26] 56 83 14 70 58 22 64 50 58 39 66 48 64 79 NA 66 67 68 47 62 51 72 65 46 43
[51] 47 41 50 42 67 22 33 76 66 54 56 40 79 51 56 54 NA 49 79 NA NA 46 48 47 74
[76] 89 72 61 70 73 26 27 53 51 29 81 73 61 68 NA 51 22 72 40 44 NA NA 57 NA 38
3.11 Gross
Be careful with missing data.
# Using CSS selectors to scrap the gross revenue sectiongross_data_html <-html_nodes(webpage,'.ghost~ .text-muted+ span')# Converting the gross revenue data to textgross_data <-html_text(gross_data_html)# Let's have a look at the gross datagross_data
[1] 58.46 NA NA NA NA 46.37 NA NA NA NA
[11] NA 160.07 NA 1.07 NA NA NA NA 206.31 NA
[21] 84.16 NA NA NA NA NA NA 2.39 NA NA
[31] NA NA NA NA 0.50 NA 17.29 NA NA NA
[41] NA NA NA 148.97 NA NA 70.41 NA NA NA
[51] 15.16 NA NA NA NA NA NA NA NA NA
[61] NA NA NA NA 58.57 NA NA NA NA NA
[71] NA NA 62.34 NA NA NA 47.70 61.56 NA NA
[81] 77.05 NA NA NA NA NA NA NA NA NA
[91] NA 27.31 NA NA NA NA NA NA NA NA
3.12 Visualizing movie data
Form a tibble:
# Combining all the lists to form a data framemovies <-tibble(Rank = rank_data, Title = title_data,Description = description_data, Runtime = runtime_data,Genre = genre_data, Rating = rating_data,Metascore = metascore_data, Votes = votes_data,Gross_Earning_in_Mil = gross_data,Director = directors_data, Actor = actors_data)movies %>%print(width=Inf)
# A tibble: 100 × 11
Rank Title
<int> <chr>
1 1 Tenet
2 2 Possessor
3 3 Inheritance
4 4 Megan
5 5 365 Days
6 6 Wonder Woman 1984
7 7 Four Good Days
8 8 The Father
9 9 Enola Holmes
10 10 Promising Young Woman
Description
<chr>
1 Armed with only one word, Tenet, and fighting for the survival of the entire…
2 An agent works for a secretive organization that uses brain-implant technolo…
3 The patriarch of a wealthy and powerful family suddenly passes away, leaving…
4 A hiker finds shelter in a mountain lodge inhabited by two strange women.
5 Massimo is a member of the Sicilian Mafia family and Laura is a sales direct…
6 Diana must contend with a work colleague, and with a businessman whose desir…
7 A mother helps her daughter work through four crucial days of recovery from …
8 A man refuses all assistance from his daughter as he ages. As he tries to ma…
9 When Enola Holmes (Sherlock's teen sister) discovers her mother is missing, …
10 A young woman, traumatized by a tragic event in her past, seeks out vengeanc…
Runtime Genre Rating Metascore Votes Gross_Earning_in_Mil
<int> <chr> <dbl> <int> <dbl> <dbl>
1 150 Action 7.3 69 515489 58.5
2 103 Horror 6.5 72 38498 NA
3 111 Drama 5.5 31 16675 NA
4 89 Thriller 4 NA 270 NA
5 114 Drama 3.3 NA 91529 NA
6 151 Action 5.4 60 272157 46.4
7 100 Drama 6.5 52 8263 NA
8 97 Drama 8.2 88 159260 NA
9 123 Action 6.6 68 197916 NA
10 113 Crime 7.5 73 178206 NA
Director Actor
<chr> <chr>
1 Christopher Nolan John David Washington
2 Brandon Cronenberg Andrea Riseborough
3 Vaughn Stein Lily Collins
4 Silvio Nacucchi Sadie Katz
5 Barbara Bialowas Anna-Maria Sieklucka
6 Patty Jenkins Gal Gadot
7 Rodrigo García Mila Kunis
8 Florian Zeller Anthony Hopkins
9 Harry Bradbeer Millie Bobby Brown
10 Emerald Fennell Carey Mulligan
# … with 90 more rows
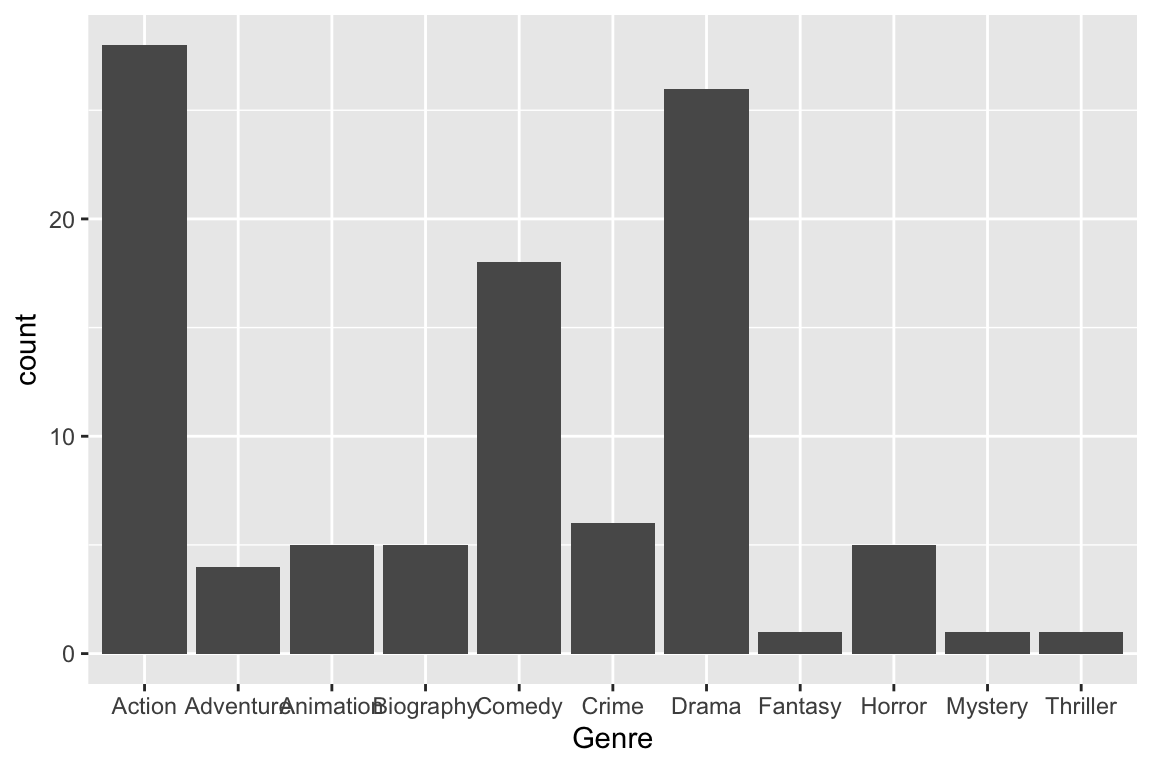
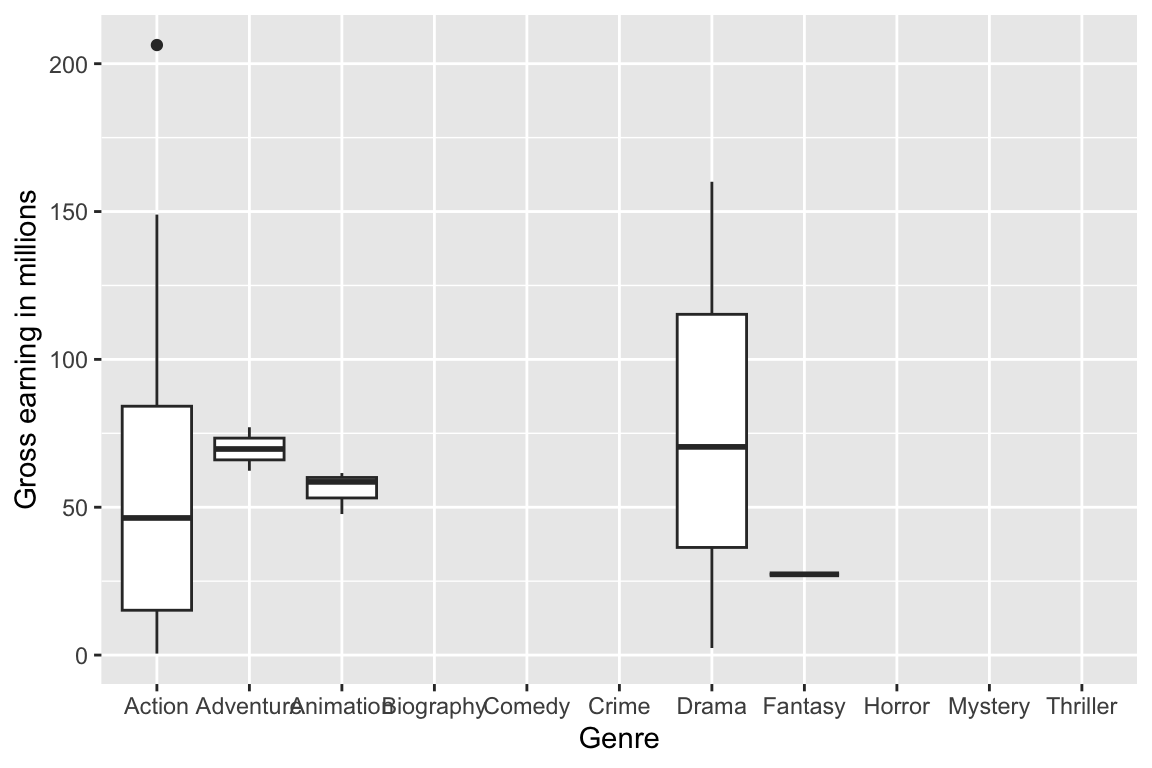
How many top 100 movies are in each genre? (Be careful with interpretation.)
movies %>%ggplot() +geom_bar(mapping =aes(x = Genre))
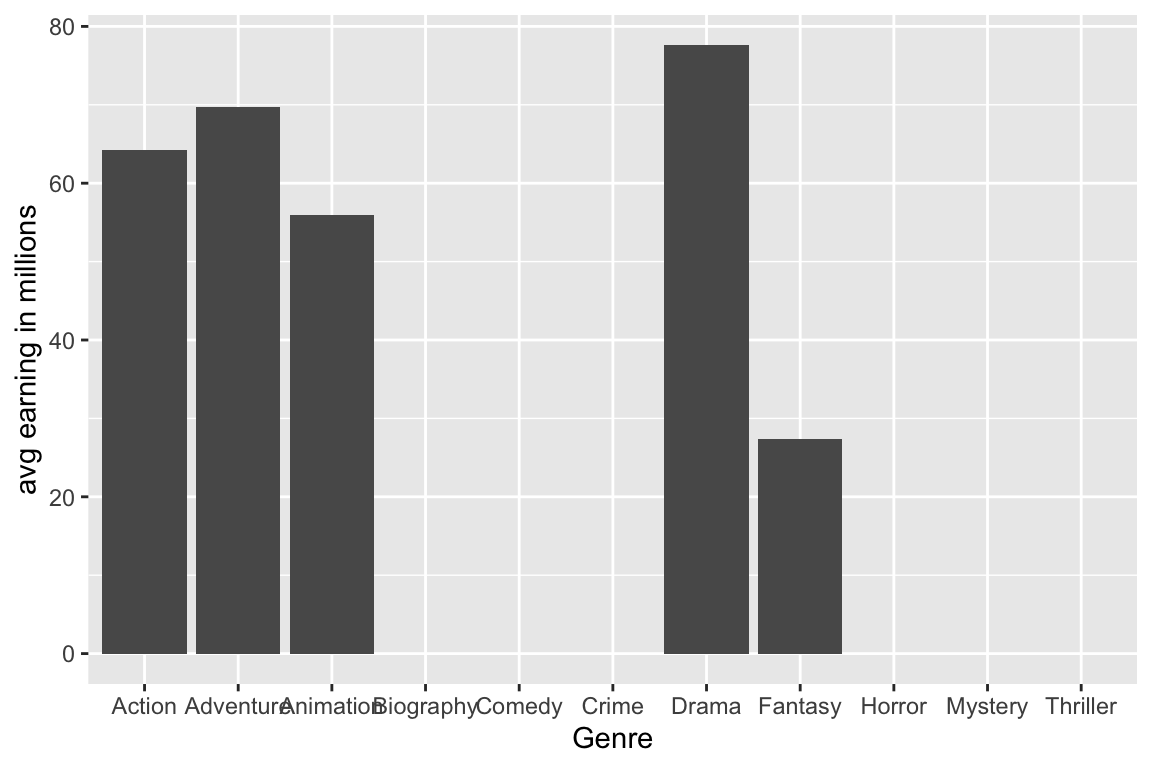
Which genre is most profitable in terms of average gross earnings?
movies %>%group_by(Genre) %>%summarise(avg_earning =mean(Gross_Earning_in_Mil, na.rm =TRUE)) %>%ggplot() +geom_col(mapping =aes(x = Genre, y = avg_earning)) +labs(y ="avg earning in millions")
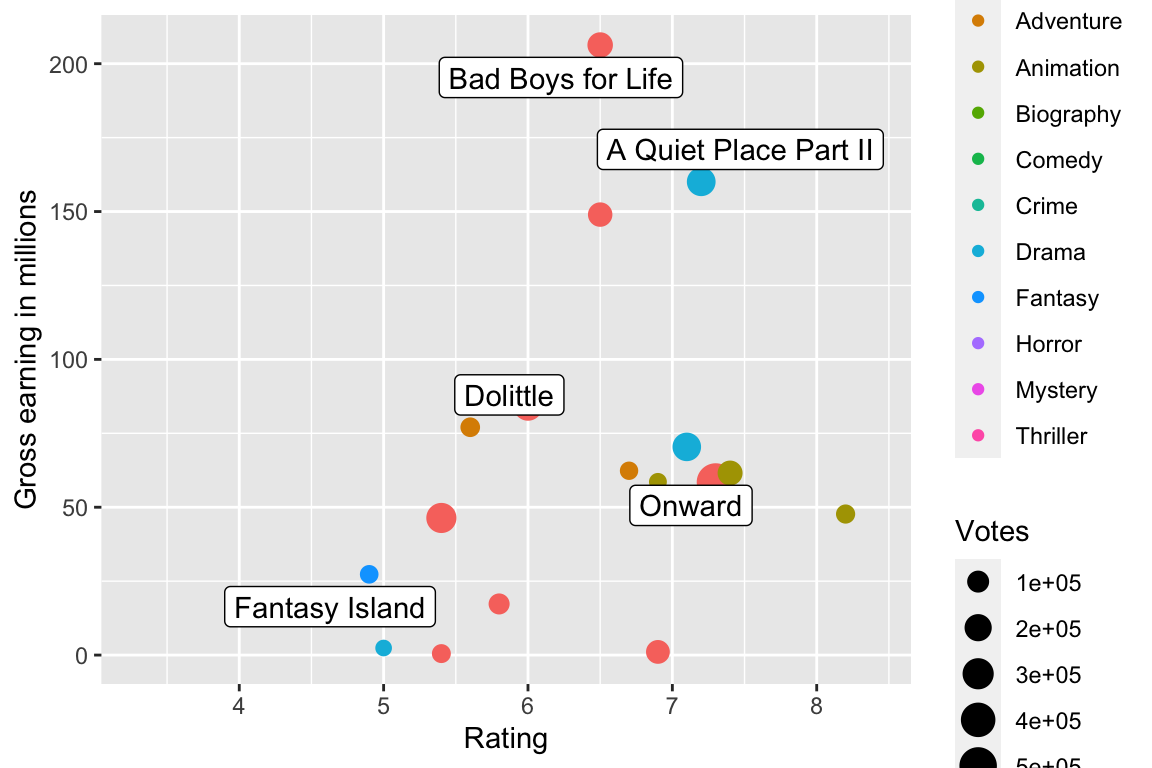
Is there a relationship between gross earning and rating? Find the best selling movie (by gross earning) in each genre
library("ggrepel")(best_in_genre <- movies %>%group_by(Genre) %>%filter(row_number(desc(Gross_Earning_in_Mil)) ==1)) %>%print(width =Inf)
# A tibble: 5 × 11
# Groups: Genre [5]
Rank Title
<int> <chr>
1 12 A Quiet Place Part II
2 19 Bad Boys for Life
3 78 Onward
4 81 Dolittle
5 92 Fantasy Island
Description
<chr>
1 Following the events at home, the Abbott family now face the terrors of the o…
2 Miami detectives Mike Lowrey and Marcus Burnett must face off against a mothe…
3 Two elven brothers embark on a quest to bring their father back for one day.
4 A physician who can talk to animals embarks on an adventure to find a legenda…
5 When the owner and operator of a luxurious island invites a collection of gue…
Runtime Genre Rating Metascore Votes Gross_Earning_in_Mil Director
<int> <chr> <dbl> <int> <dbl> <dbl> <chr>
1 97 Drama 7.2 71 236703 160. John Krasinski
2 124 Action 6.5 59 163610 206. Adil El Arbi
3 102 Animation 7.4 61 153020 61.6 Dan Scanlon
4 101 Adventure 5.6 26 66091 77.0 Stephen Gaghan
5 109 Fantasy 4.9 22 53978 27.3 Jeff Wadlow
Actor
<chr>
1 Emily Blunt
2 Will Smith
3 Tom Holland
4 Robert Downey Jr.
5 Michael Peña
ggplot(movies, mapping =aes(x = Rating, y = Gross_Earning_in_Mil)) +geom_point(mapping =aes(size = Votes, color = Genre)) + ggrepel::geom_label_repel(aes(label = Title), data = best_in_genre) +labs(y ="Gross earning in millions")