In the next few lectures, we focus on the modeling step. We take the narrow sense of statistical/machine learning for the model step.
1 Overview of statistical/machine learning
In this class, we use the phrases statistical learning, machine learning, or simply learning interchangeably.
1.1 Supervised vs unsupervised learning
Supervised learning: input(s) -> output.
Prediction: the output is continuous (income, weight, bmi, …).
Classification: the output is categorical (disease or not, pattern recognition, …).
Unsupervised learning: no output. We learn relationships and structure in the data.
Clustering.
Dimension reduction.
1.2 Supervised learning
Predictors\[
X = \begin{pmatrix} X_1 \\ \vdots \\ X_p \end{pmatrix}.
\] Also called inputs, covariates, regressors, features, independent variables.
Outcome\(Y\) (also called output, response variable, dependent variable, target).
In the regression problem, \(Y\) is quantitative (price, weight, bmi).
In the classification problem, \(Y\) is categorical. That is \(Y\) takes values in a finite, unordered set (survived/died, customer buy product or not, digit 0-9, object in image, cancer class of tissue sample).
We have training data \((\mathbf{x}_1, y_1), \ldots, (\mathbf{x}_n, y_n)\). These are observations (also called samples, instances, cases). Training data is often represented by a predictor matrix \[
\mathbf{X} = \begin{pmatrix}
x_{11} & \cdots & x_{1p} \\
\vdots & \ddots & \vdots \\
x_{n1} & \cdots & x_{np}
\end{pmatrix} = \begin{pmatrix} \mathbf{x}_1^T \\ \vdots \\ \mathbf{x}_n^T \end{pmatrix}
\tag{1}\] and a response vector \[
\mathbf{y} = \begin{pmatrix} y_1 \\ \vdots \\ y_n \end{pmatrix}
\]
Based on the training data, our goal is to
Accurately predict unseen outcome of test cases based on their predictors.
Understand which predictors affect the outcome, and how.
Assess the quality of our predictions and inferences.
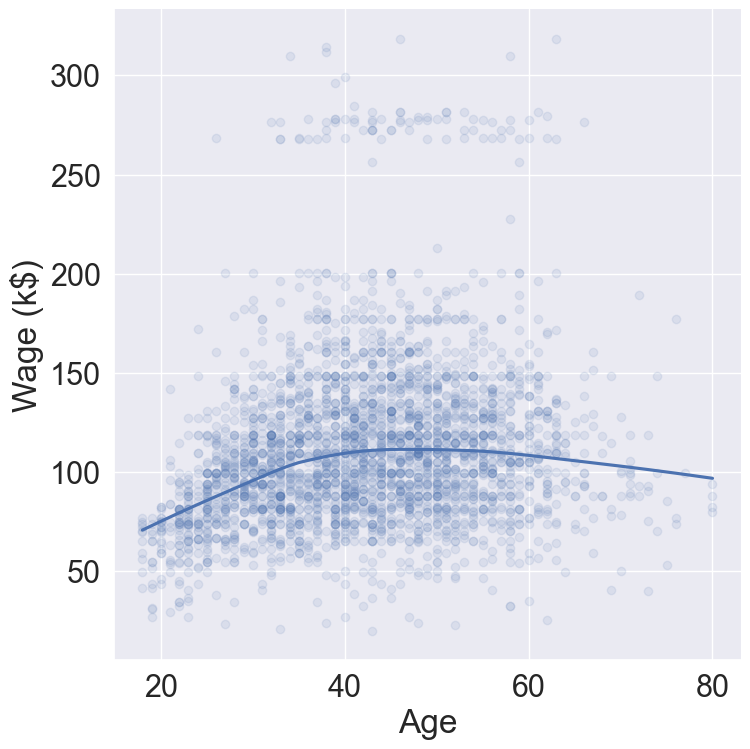
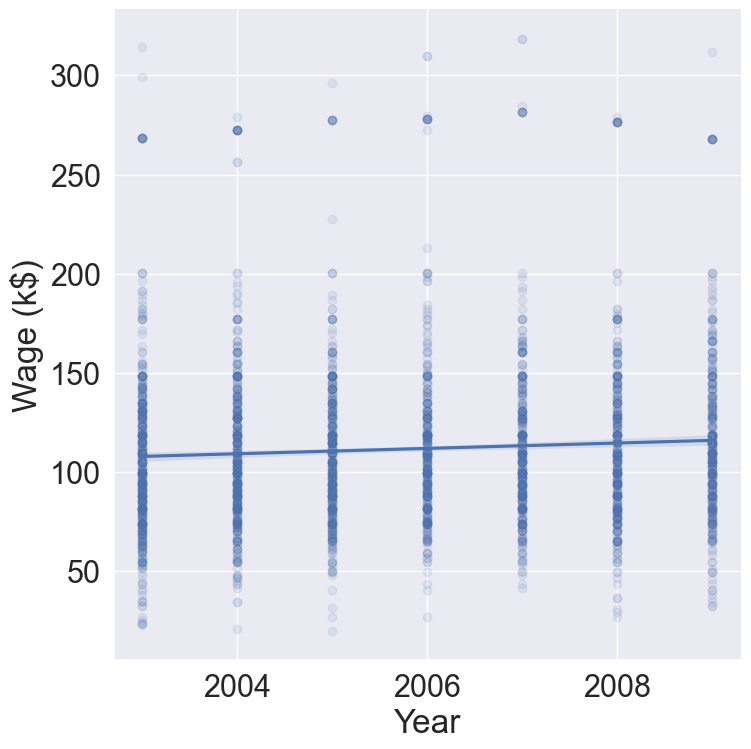
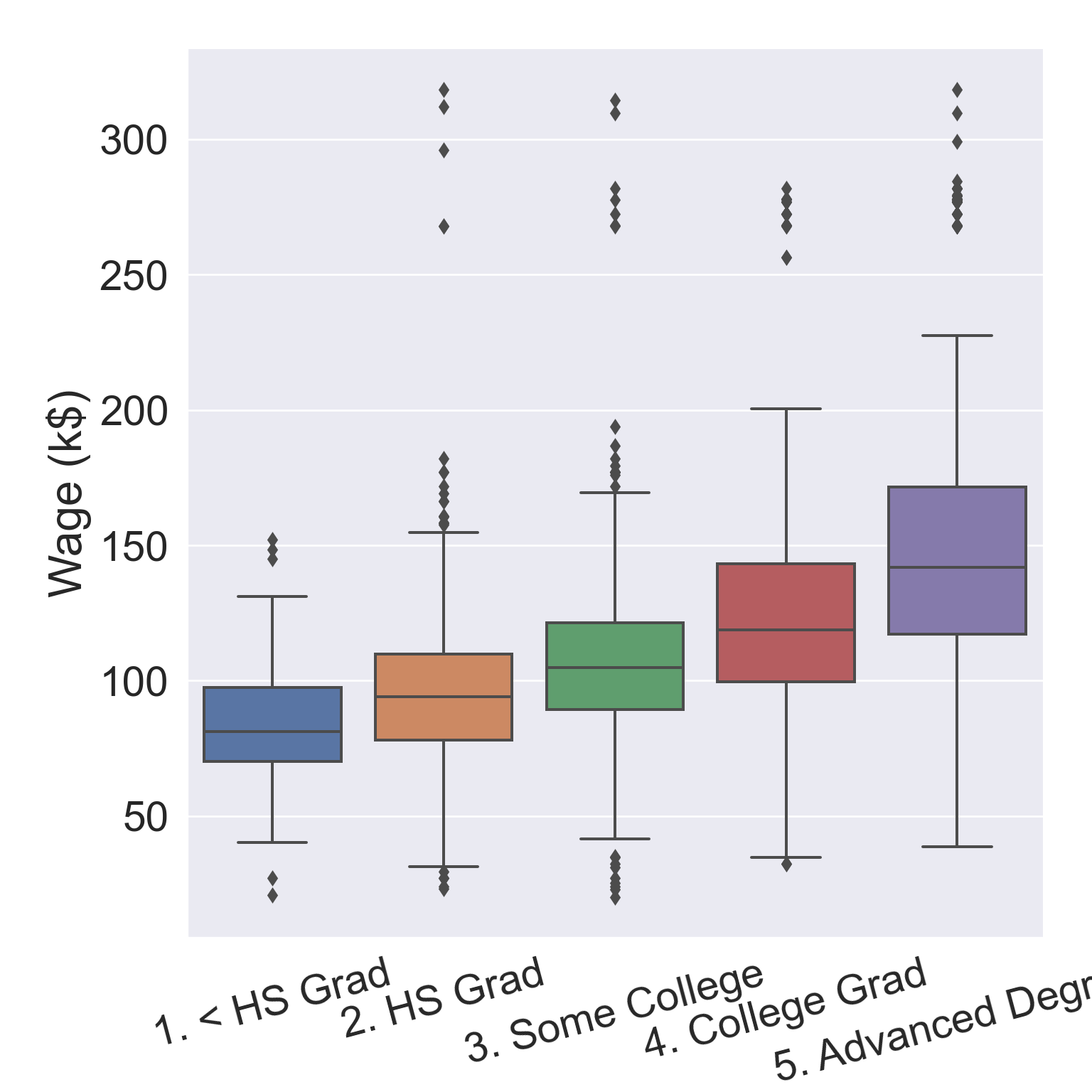
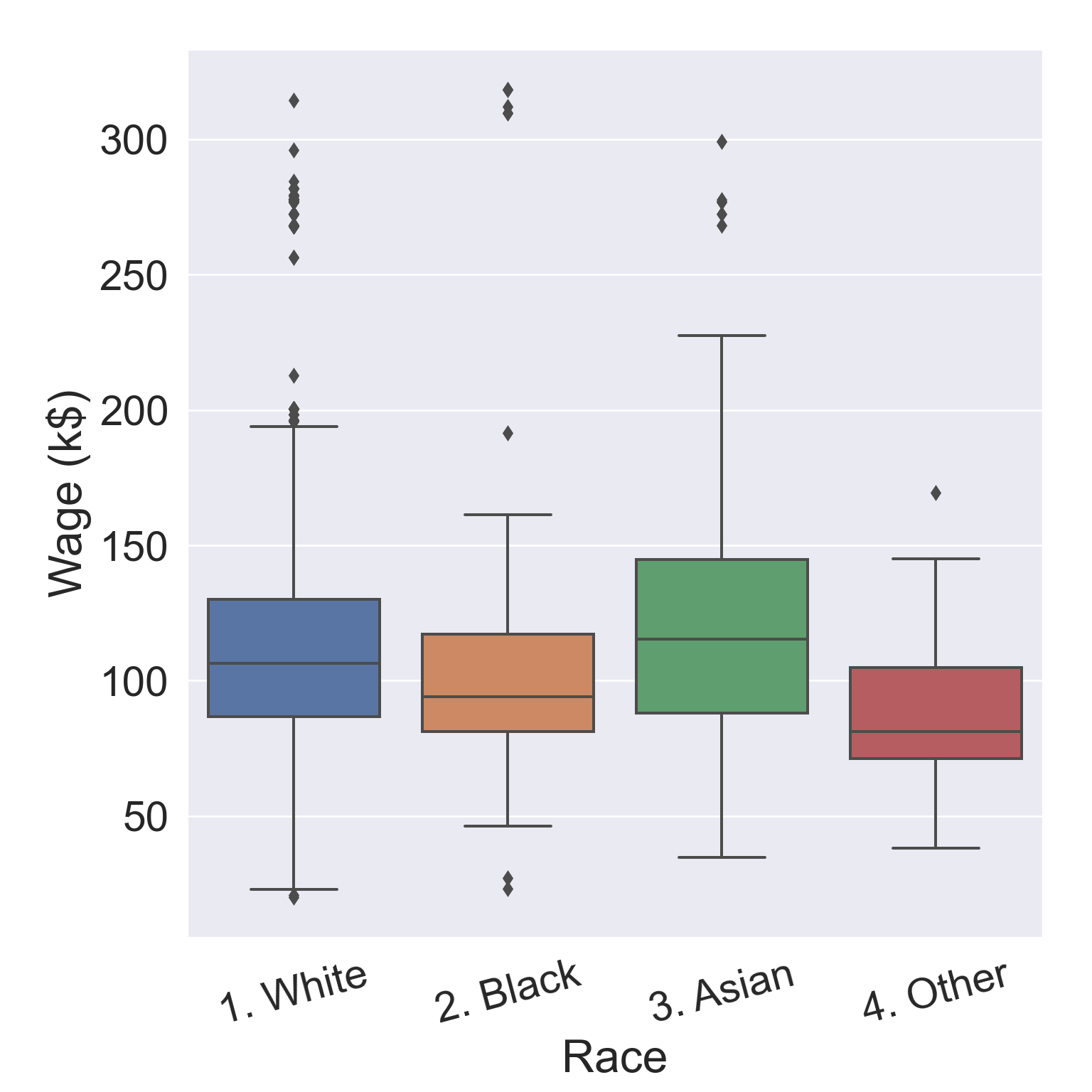
1.2.1 Example: salary
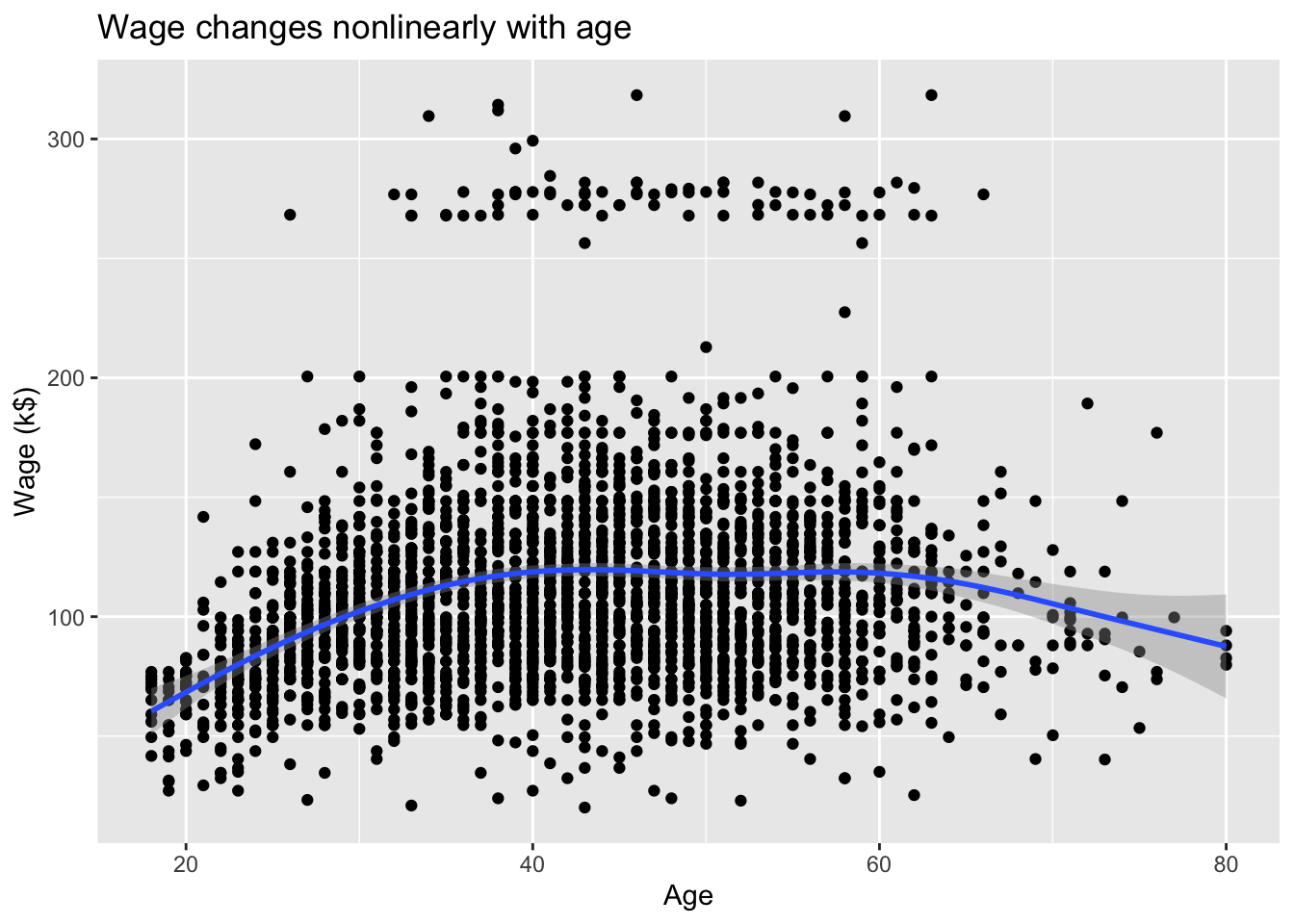
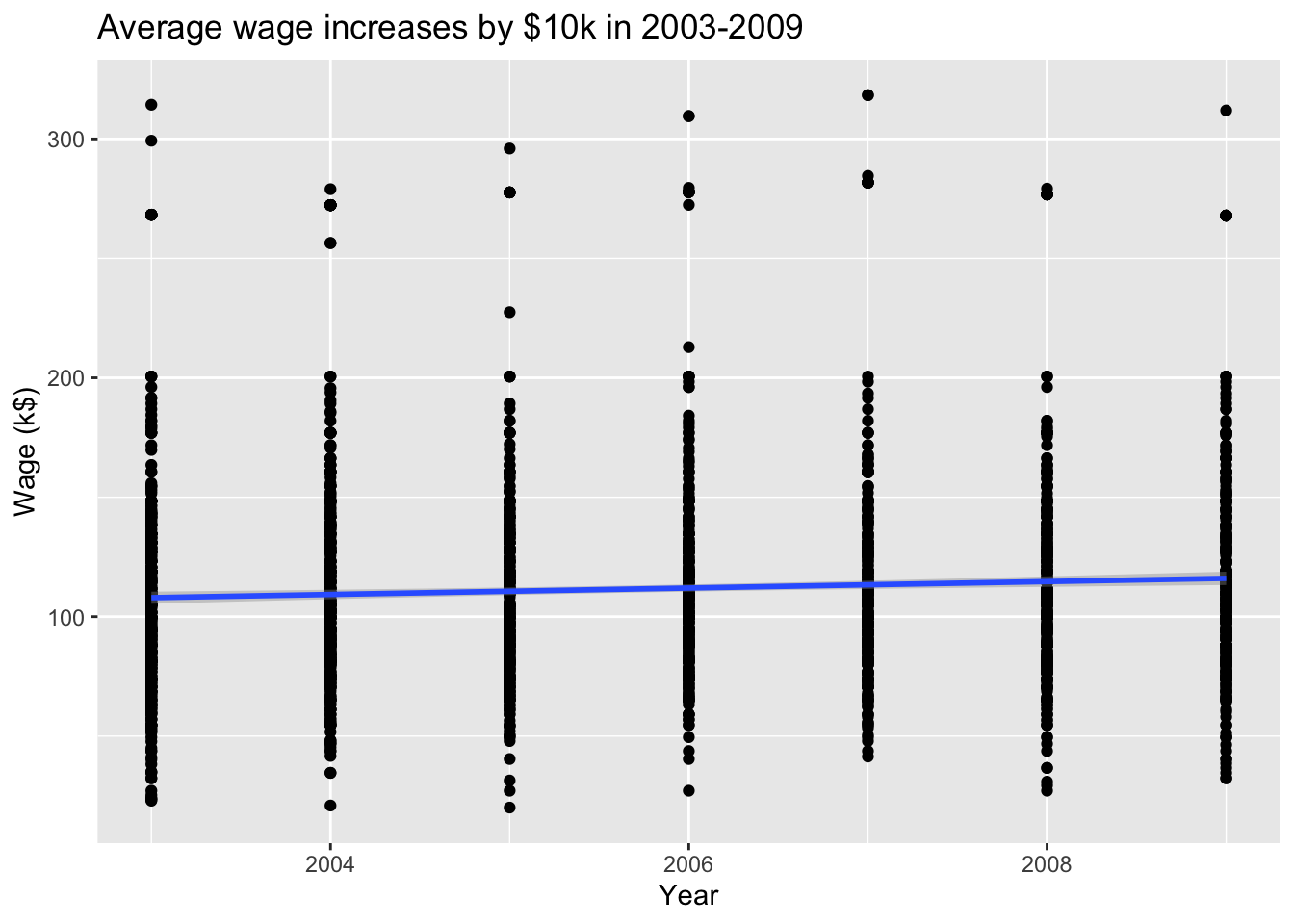
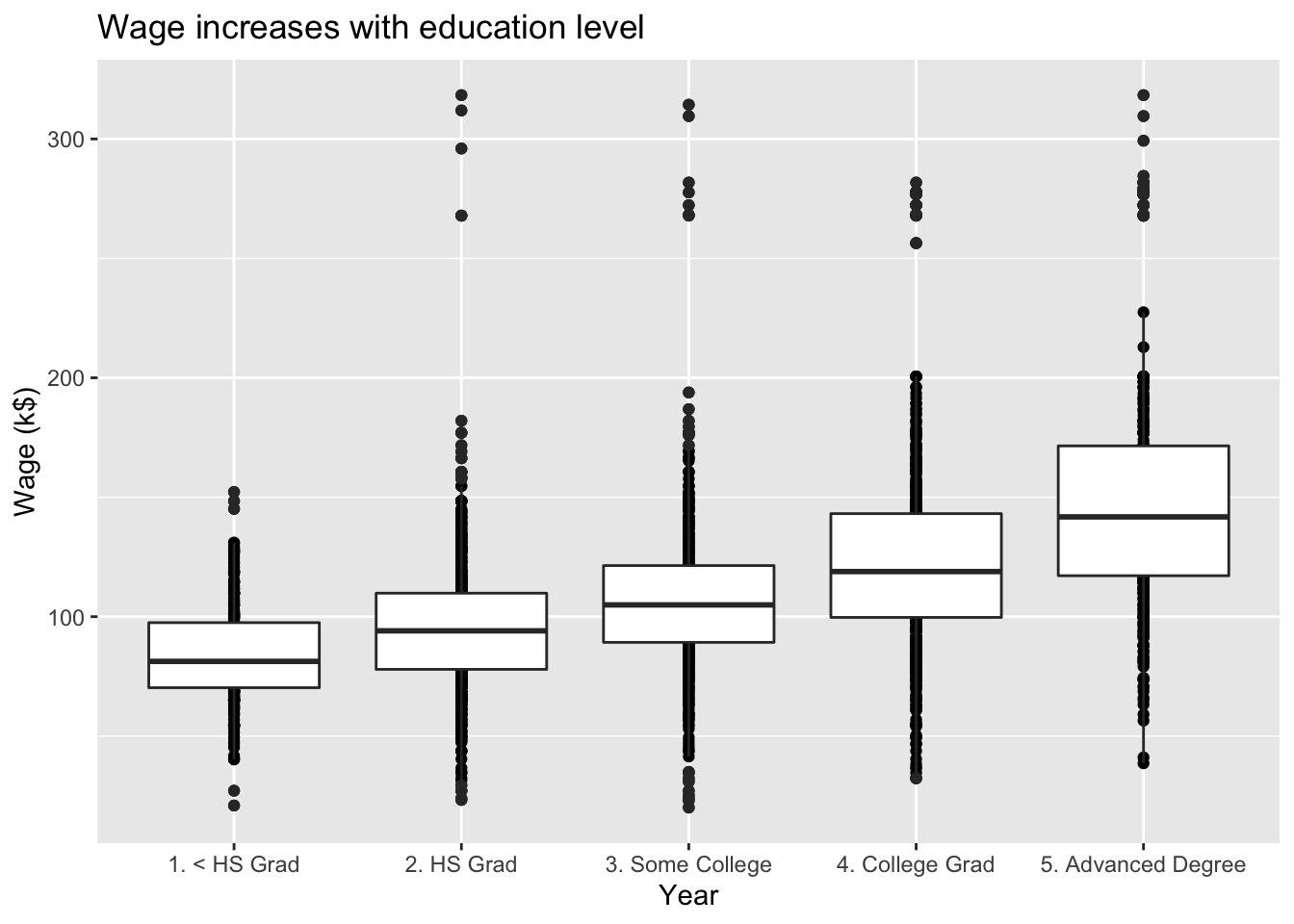
The Wage data set collects the wage and other data for a group of 3000 male workers in the Mid-Atlantic region in 2003-2009.
Our goal is to establish the relationship between salary and demographic variables in population survey data.
Since wage is a quantitative variable, it is a regression problem.
library(gtsummary)library(ISLR2)library(tidyverse)# Convert to tibbleWage <-as_tibble(Wage) %>%print(width =Inf)
# A tibble: 3,000 × 11
year age maritl race education region
<int> <int> <fct> <fct> <fct> <fct>
1 2006 18 1. Never Married 1. White 1. < HS Grad 2. Middle Atlantic
2 2004 24 1. Never Married 1. White 4. College Grad 2. Middle Atlantic
3 2003 45 2. Married 1. White 3. Some College 2. Middle Atlantic
4 2003 43 2. Married 3. Asian 4. College Grad 2. Middle Atlantic
5 2005 50 4. Divorced 1. White 2. HS Grad 2. Middle Atlantic
6 2008 54 2. Married 1. White 4. College Grad 2. Middle Atlantic
7 2009 44 2. Married 4. Other 3. Some College 2. Middle Atlantic
8 2008 30 1. Never Married 3. Asian 3. Some College 2. Middle Atlantic
9 2006 41 1. Never Married 2. Black 3. Some College 2. Middle Atlantic
10 2004 52 2. Married 1. White 2. HS Grad 2. Middle Atlantic
jobclass health health_ins logwage wage
<fct> <fct> <fct> <dbl> <dbl>
1 1. Industrial 1. <=Good 2. No 4.32 75.0
2 2. Information 2. >=Very Good 2. No 4.26 70.5
3 1. Industrial 1. <=Good 1. Yes 4.88 131.
4 2. Information 2. >=Very Good 1. Yes 5.04 155.
5 2. Information 1. <=Good 1. Yes 4.32 75.0
6 2. Information 2. >=Very Good 1. Yes 4.85 127.
7 1. Industrial 2. >=Very Good 1. Yes 5.13 170.
8 2. Information 1. <=Good 1. Yes 4.72 112.
9 2. Information 2. >=Very Good 1. Yes 4.78 119.
10 2. Information 2. >=Very Good 1. Yes 4.86 129.
# … with 2,990 more rows
# Load the pandas libraryimport pandas as pd# Load numpy for array manipulationimport numpy as np# Load seaborn plotting libraryimport seaborn as snsimport matplotlib.pyplot as plt# Set font size in plotssns.set(font_scale =2)# Display all columnspd.set_option('display.max_columns', None)# Import Wage dataWage = pd.read_csv("../data/Wage.csv", dtype = {'maritl':'category', 'race':'category','education':'category','region':'category','jobclass':'category','health':'category','health_ins':'category' } )Wage
year age maritl race education \
0 2006 18 1. Never Married 1. White 1. < HS Grad
1 2004 24 1. Never Married 1. White 4. College Grad
2 2003 45 2. Married 1. White 3. Some College
3 2003 43 2. Married 3. Asian 4. College Grad
4 2005 50 4. Divorced 1. White 2. HS Grad
... ... ... ... ... ...
2995 2008 44 2. Married 1. White 3. Some College
2996 2007 30 2. Married 1. White 2. HS Grad
2997 2005 27 2. Married 2. Black 1. < HS Grad
2998 2005 27 1. Never Married 1. White 3. Some College
2999 2009 55 5. Separated 1. White 2. HS Grad
region jobclass health health_ins logwage \
0 2. Middle Atlantic 1. Industrial 1. <=Good 2. No 4.318063
1 2. Middle Atlantic 2. Information 2. >=Very Good 2. No 4.255273
2 2. Middle Atlantic 1. Industrial 1. <=Good 1. Yes 4.875061
3 2. Middle Atlantic 2. Information 2. >=Very Good 1. Yes 5.041393
4 2. Middle Atlantic 2. Information 1. <=Good 1. Yes 4.318063
... ... ... ... ... ...
2995 2. Middle Atlantic 1. Industrial 2. >=Very Good 1. Yes 5.041393
2996 2. Middle Atlantic 1. Industrial 2. >=Very Good 2. No 4.602060
2997 2. Middle Atlantic 1. Industrial 1. <=Good 2. No 4.193125
2998 2. Middle Atlantic 1. Industrial 2. >=Very Good 1. Yes 4.477121
2999 2. Middle Atlantic 1. Industrial 1. <=Good 1. Yes 4.505150
wage
0 75.043154
1 70.476020
2 130.982177
3 154.685293
4 75.043154
... ...
2995 154.685293
2996 99.689464
2997 66.229408
2998 87.981033
2999 90.481913
[3000 rows x 11 columns]
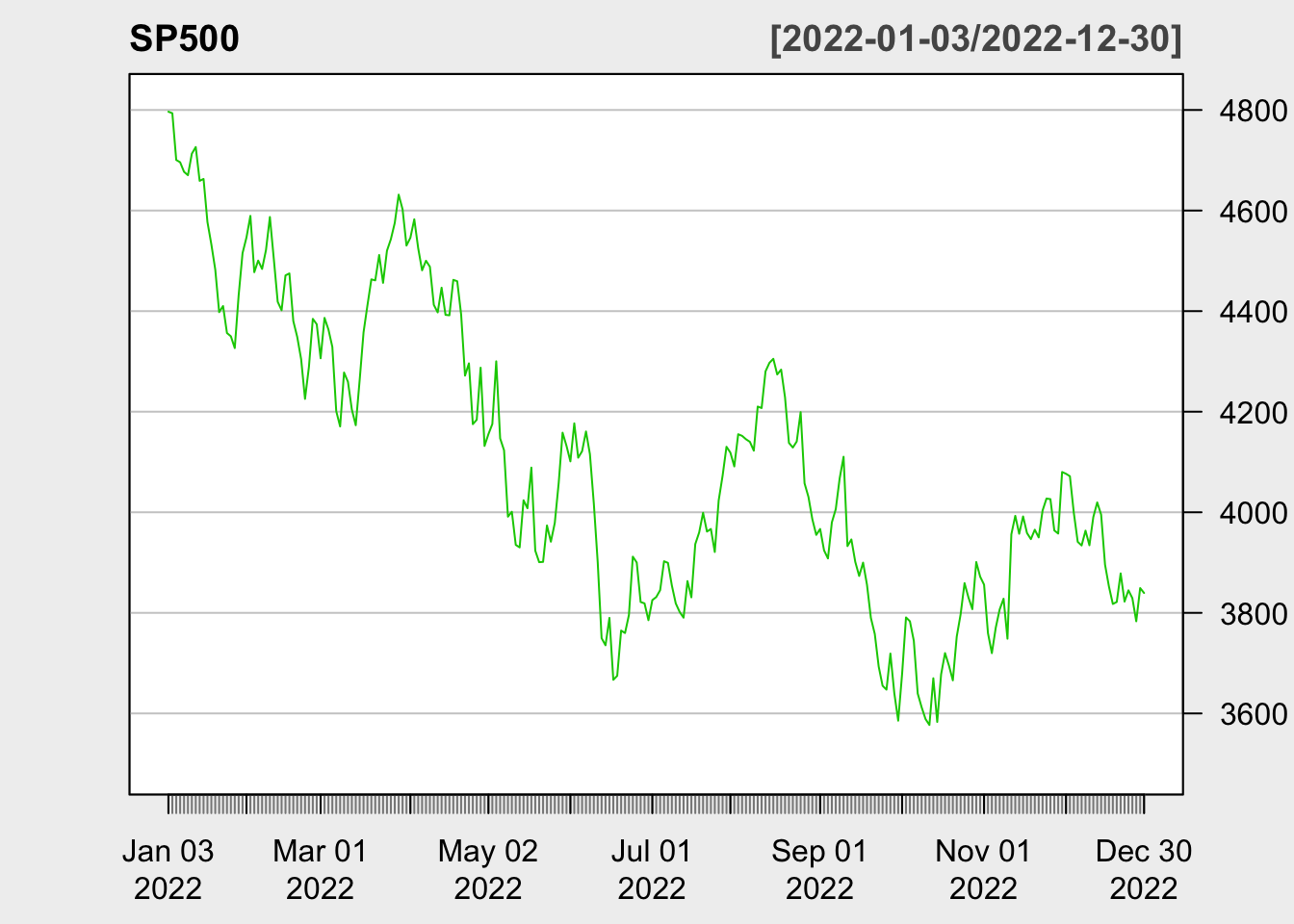
library(quantmod)SP500 <-getSymbols("^GSPC", src ="yahoo", auto.assign =FALSE, from ="2022-01-01",to ="2022-12-31")chartSeries(SP500, theme =chartTheme("white"),type ="line", log.scale =FALSE, TA =NULL)
The Smarket data set contains daily percentage returns for the S&P 500 stock index between 2001 and 2005.
Our goal is to predict whether the index will increase or decrease on a given day, using the past 5 days’ percentage changes in the index.
Since the outcome is binary (increase or decrease), it is a classification problem.
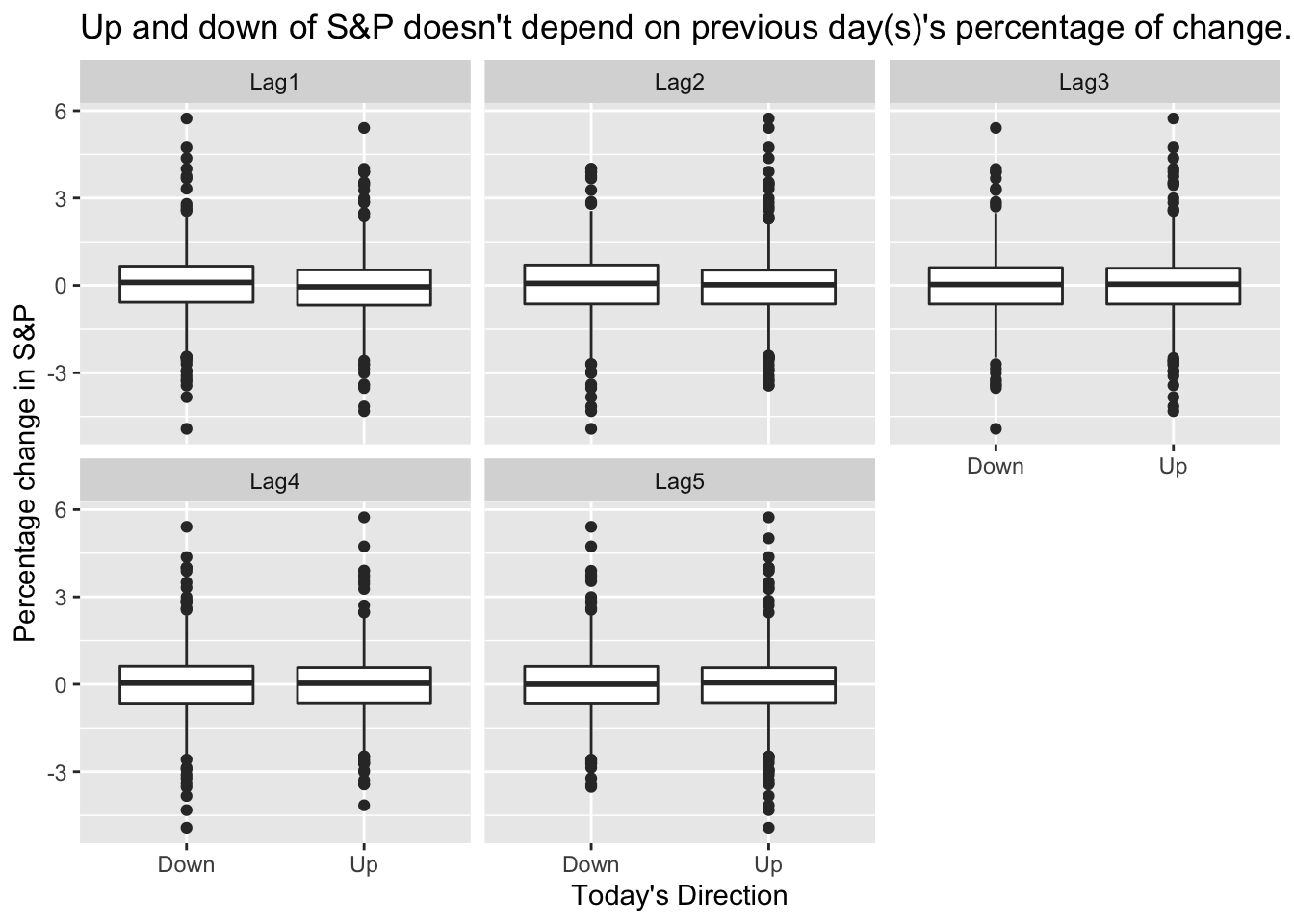
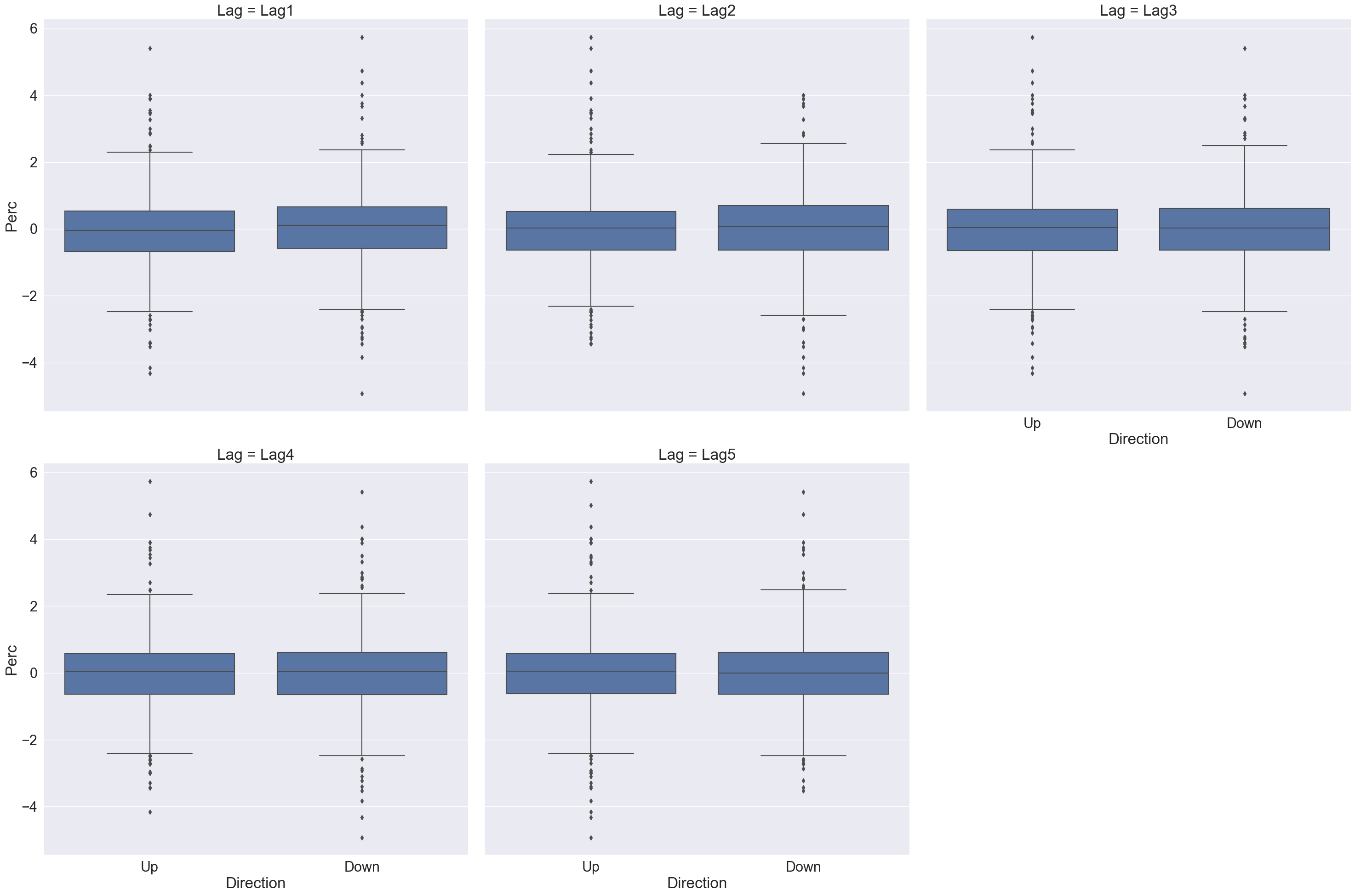
From the boxplots in Figure 5, it seems that the previous 5 days percentage returns do not discriminate whether today’s return is positive or negative.
# Data informationhelp(Smarket)# Convert to tibbleSmarket <-as_tibble(Smarket) %>%print(width =Inf)
# A tibble: 1,250 × 9
Year Lag1 Lag2 Lag3 Lag4 Lag5 Volume Today Direction
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <fct>
1 2001 0.381 -0.192 -2.62 -1.06 5.01 1.19 0.959 Up
2 2001 0.959 0.381 -0.192 -2.62 -1.06 1.30 1.03 Up
3 2001 1.03 0.959 0.381 -0.192 -2.62 1.41 -0.623 Down
4 2001 -0.623 1.03 0.959 0.381 -0.192 1.28 0.614 Up
5 2001 0.614 -0.623 1.03 0.959 0.381 1.21 0.213 Up
6 2001 0.213 0.614 -0.623 1.03 0.959 1.35 1.39 Up
7 2001 1.39 0.213 0.614 -0.623 1.03 1.44 -0.403 Down
8 2001 -0.403 1.39 0.213 0.614 -0.623 1.41 0.027 Up
9 2001 0.027 -0.403 1.39 0.213 0.614 1.16 1.30 Up
10 2001 1.30 0.027 -0.403 1.39 0.213 1.23 0.287 Up
# … with 1,240 more rows
# Summary statisticssummary(Smarket)
Year Lag1 Lag2 Lag3
Min. :2001 Min. :-4.922000 Min. :-4.922000 Min. :-4.922000
1st Qu.:2002 1st Qu.:-0.639500 1st Qu.:-0.639500 1st Qu.:-0.640000
Median :2003 Median : 0.039000 Median : 0.039000 Median : 0.038500
Mean :2003 Mean : 0.003834 Mean : 0.003919 Mean : 0.001716
3rd Qu.:2004 3rd Qu.: 0.596750 3rd Qu.: 0.596750 3rd Qu.: 0.596750
Max. :2005 Max. : 5.733000 Max. : 5.733000 Max. : 5.733000
Lag4 Lag5 Volume Today
Min. :-4.922000 Min. :-4.92200 Min. :0.3561 Min. :-4.922000
1st Qu.:-0.640000 1st Qu.:-0.64000 1st Qu.:1.2574 1st Qu.:-0.639500
Median : 0.038500 Median : 0.03850 Median :1.4229 Median : 0.038500
Mean : 0.001636 Mean : 0.00561 Mean :1.4783 Mean : 0.003138
3rd Qu.: 0.596750 3rd Qu.: 0.59700 3rd Qu.:1.6417 3rd Qu.: 0.596750
Max. : 5.733000 Max. : 5.73300 Max. :3.1525 Max. : 5.733000
Direction
Down:602
Up :648
# Plot Direction ~ Lag1, Direction ~ Lag2, ...Smarket %>%pivot_longer(cols = Lag1:Lag5, names_to ="Lag", values_to ="Perc") %>%ggplot() +geom_boxplot(mapping =aes(x = Direction, y = Perc)) +labs(x ="Today's Direction", y ="Percentage change in S&P",title ="Up and down of S&P doesn't depend on previous day(s)'s percentage of change." ) +facet_wrap(~ Lag)
Objective is more fuzzy: find groups that behave similarly, find features that behave similarly, find linear combinations of features with the most variations, generative models (transformers).
Difficult to know how well you are doing.
Can be useful in exploratory data analysis (EDA) or as a pre-processing step for supervised learning.
1.3.1 Example: gene expression
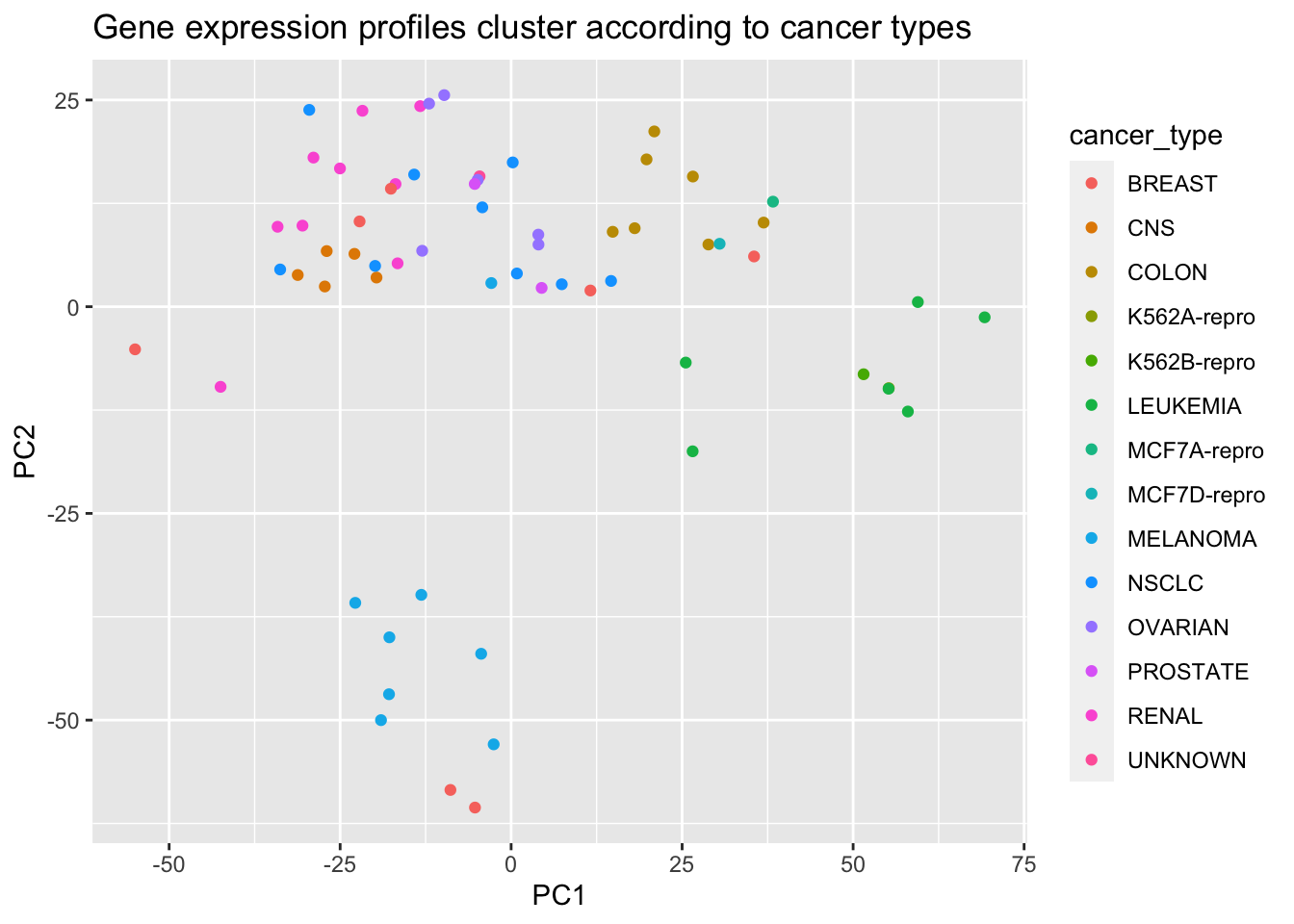
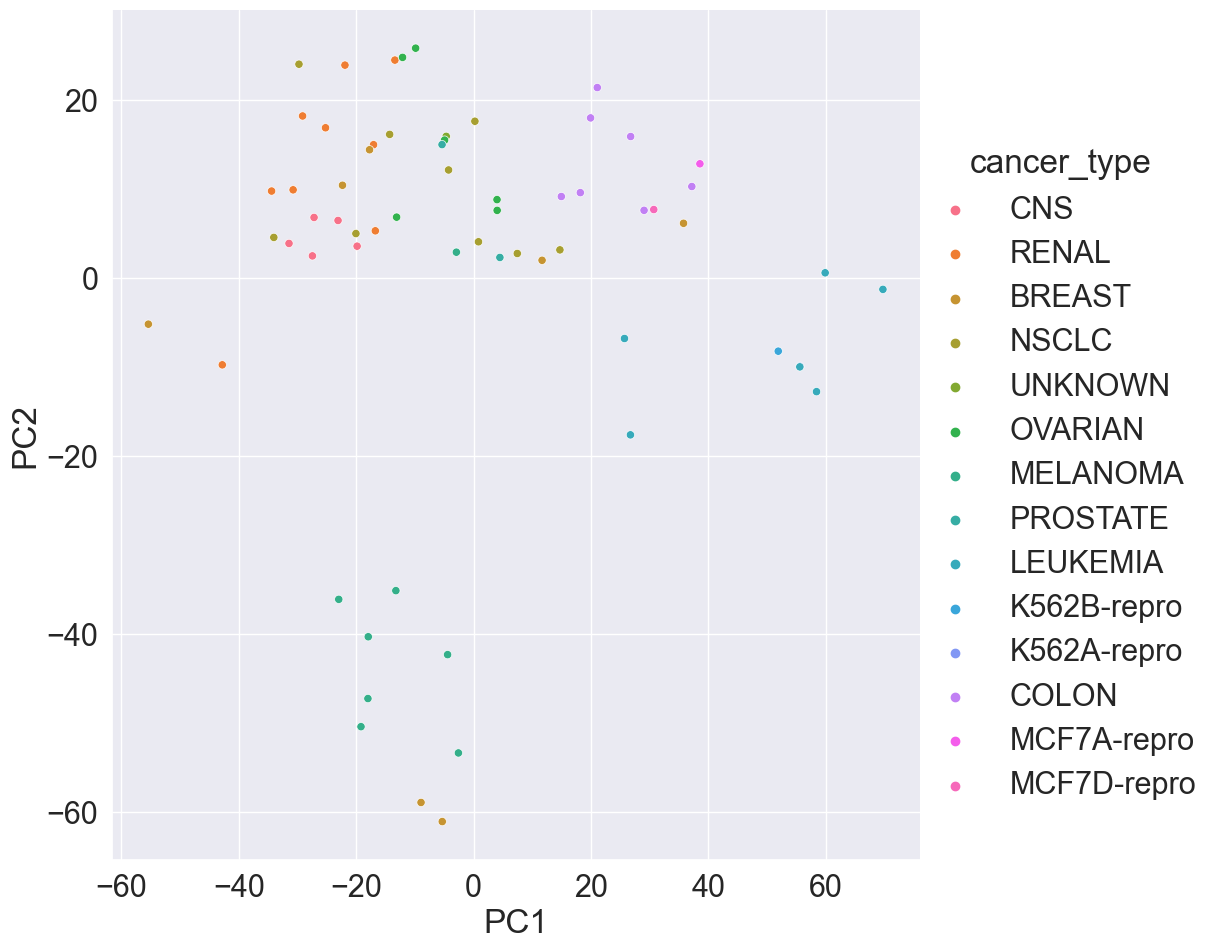
The NCI60 data set consists of 6,830 gene expression measurements for each of 64 cancer cell lines.
# Apply PCA using prcomp function# Need to scale / Normalize as# PCA depends on distance measureprcomp(NCI60$data, scale =TRUE, center =TRUE, retx = T)$x %>%as_tibble() %>%add_column(cancer_type = NCI60$labs) %>%# Plot PC2 vs PC1ggplot() +geom_point(mapping =aes(x = PC1, y = PC2, color = cancer_type)) +labs(title ="Gene expression profiles cluster according to cancer types")
# Plot PC2 vs PC1sns.relplot( kind ='scatter', data = nci60_pc, x ='PC1', y ='PC2', hue ='cancer_type', height =10 )
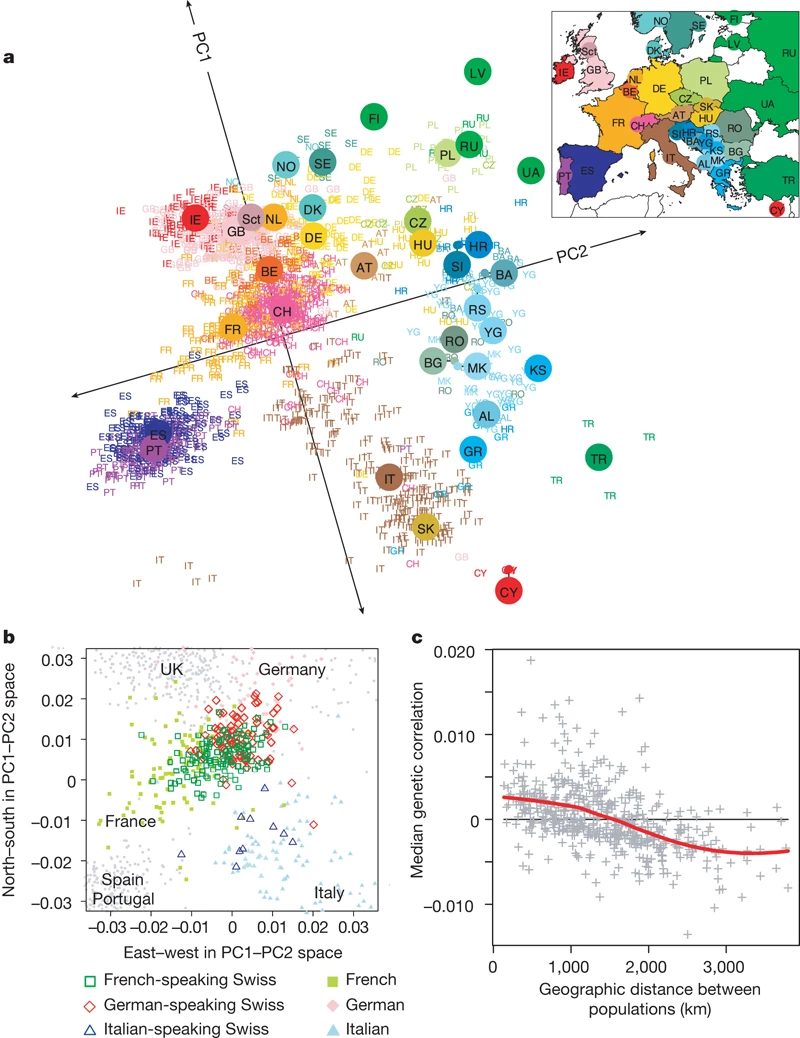
1.3.2 Example: mapping people from their genomes
The genetic makeup of \(n\) individuals can be represented by a matrix Equation 1, where \(x_{ij} \in \{0, 1, 2\}\) is the \(j\)-th genetic marker of the \(i\)-th individual.
Is that possible to visualize the geographic relationship of these individuals?